

django进阶
1.模板内容复习
2.FBV及CBV及上传文件
3.ORM复习
4.ORM拓展
5.cookie和session
6.csrf详情
7.django分页
django预备知识:https://www.cnblogs.com/wyb666/p/9444150.html
django基础:https://www.cnblogs.com/wyb666/p/9464983.html
1.模板内容复习
(1)母版和继承
1 什么时候用母版? 2 html页面有重复的代码,把它们提取出来放到一个单独的html文件(比如:导航条和左侧菜单) 3 4 子页面如何使用母版? 5 {% extends 'base.html' %} --> 必须要放在子页面的第一行 6 母版里面定义block(块),子页面使用block(块)去替换母版中同名的块
(2)组件
1 什么时候用组件? 2 重复的代码,包装成一个独立的小html文件。 3 4 如何使用? 5 {% include 'nav.html' %}
(3)Django模板语言中关于静态文件路径的灵活写法
1 利用Django模板语言内置的static方法帮我拼接静态文件的路径: 2 {% load static %} 3 <link href="{% static 'bootstrap/css/bootstrap.min.css' %}" rel="stylesheet"> 4 5 利用内置的get_static_prefix获取静态文件路径的别名,我们自行拼接路径: 6 {% load static %} 7 <link href="{% get_static_prefix %}bootstrap/css/bootstrap.min.css" rel=stylesheet>
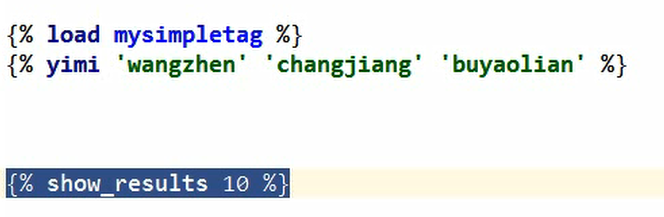
(4)自定义simple_tag和自定义inclusion_tag
1 自定义的simple_tag: 2 比filter高级一点点,返回一段文本 3 它可以接受的参数个数大于2 4 5 自定义的inclusion_tag: 6 用来返回一段html代码(示例:返回ul标签)
py文件(放在在app下面新建的templatetags 文件夹(包)):

HTML:
2.FBV及CBV及上传文件
(1)什么是FBV及CBV
视图:接收请求返回响应那部分
FBV:function base view 基于函数的视图
CBV:class base view 基于类的视图
(2)CBV实例
views.py:
1 # CBV实例 - 添加新的出版社 2 class AddPublisher(View): 3 def get(self, request): 4 return redirect("/book/publisher_list/") 5 6 def post(self, request): 7 new_name = request.POST.get("publisher_name", None) 8 if new_name: 9 # 通过ORM去数据库里新建一条记录 10 models.Publisher.objects.create(name=new_name) 11 return redirect("/book/publisher_list/")
urls.py:
1 url(r'^add_publisher/', views.AddPublisher.as_view()),
(3)上传文件
上传文件要使用到request的以下参数:
request.FILES: 包含所有上传文件的类字典对象;FILES中的每一个Key都是<input type="file" name="" />标签中name属性的值,FILES中的每一个value同时也是一个标准的python字典对象,包含下面三个Keys:
- filename: 上传文件名,用字符串表示
- content_type: 上传文件的Content Type
- content: 上传文件的原始内容
前端HTML:
1 <form action="" method="post" enctype="multipart/form-data"> 2 <input type="file" name="upload-file"> 3 <input type="submit" value="上传文件"> 4 </form> 5 6 注意: 7 上传文件时表单中的enctype="multipart/form-data"必须要写 8 input(file)必须要有name
views.py:
1 def upload(request): 2 if request.method == "POST": 3 filename = request.FILES["upload-file"].name 4 # 在项目目录下新建一个文件 -> 项目根目录 5 with open(filename, "wb") as f: 6 # 从上传的文件对象中一点一点读 7 for chunk in request.FILES["upload-file"].chunks(): 8 # 写入本地文件 9 f.write(chunk) 10 return HttpResponse("上传OK") 11 return render(request, "test/test_upload.html")
3.ORM复习
(1)django ORM增删改查
1 DjangoORM基本增删查改: 2 # 创建: 3 # (1) 4 # models.UserInfo.objects.create(username='root', pwd='666888999') 5 # (2) 6 # dict = {'username': 'alex', 'pwd': '333'} 7 # models.UserInfo.objects.create(**dict) 8 # (3) 9 # obj = models.UserInfo.objects.create(username='root', pwd='666888999') 10 # obj.save() 11 12 # 查: 13 # (1)全部: 14 # result = models.UserInfo.objects.all() 15 # (2)按条件查找: 16 # result = models.UserInfo.objects.filter(username='root') 17 # first = models.UserInfo.objects.filter(username='root').first() 18 # count = models.UserInfo.objects.filter(username='root').count() 19 # result = models.UserInfo.objects.filter(username='root', pwd='123456') 20 21 # 查找的结果的数据结构: 22 # result, QuerySet -> Django -> [] 23 # [obj(id, username, pwd),obj(id, username, pwd),obj(id, username, pwd)] 24 # 输出查找的结果: 25 # for row in result: 26 # print(row.id, row.username, row.pwd) 27 28 # 删: 29 # 删除id为4的数据 30 # models.UserInfo.objects.filter(id=4).delete() 31 # 删除username为alex的数据 32 # models.UserInfo.objects.filter(username="alex").delete() 33 34 # 更新: 35 # 全部更新: 36 # models.UserInfo.objects.all().update(pwd='666') 37 # 条件更新: 38 # models.UserInfo.objects.filter(id=3).update(pwd='69')
(2)ORM字段
常用字段:
- AutoField --> int自增列 必须填入参数primary_key=True
- CharField --> 字符类型 varchar(xx) 必须提供max_length参数
- TextField --> 文本类型
- ForeignKey --> 外键
- ManyToManyField --> 多对多关联
- DateField --> 日期字段 YYYY-MM-DD 相当于python的datetime.date()实例
- DateTimeField --> 日期时间字段 YYYY-MM-DD HH:MM 相当于python的datetime.datetime()实例
- IntegerField --> 整数类型
常用的字段参数:
- null 表示某个字段可以为空
- default 为字段设置默认值
- unique 表示该字段在此表中唯一
- db_index 为此字段设置索引
DateField和DateTimeField才有的参数:
- auto_now_add=True --> 创建数据的时候自动把当前时间赋值
- auto_add=True --> 每次更新数据的时候更新当前时间
- 注意: 上述两个不能同时设置!!!
(3)关系字段
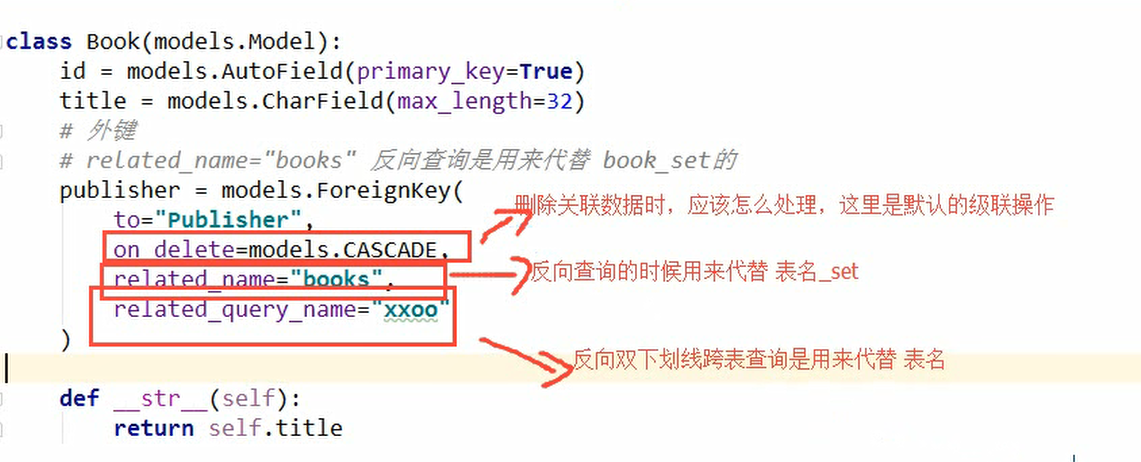
- ForeignKey:外键类型在ORM中用来表示外键关联关系,一般把ForeignKey字段设置在 '一对多'中'多'的一方
- OneToOneField:一对一字段 通常一对一字段用来扩展已有字段
- ManyToManyField: 用于表示多对多的关联关系。在数据库中通过第三张表来建立关联关系
eg:
- ForeignKey(to="类名",related_name=“xx”) --> 1对多,外键通常设置在多的那一边
- ManyToMany(to="类名",related_name="xx") --> 多对多,通常设置在正向查询多的那一边
- OneToOneField(to="类名") --> 1对1,把不怎么常用的字段 单独拿出来做成一张表 然后用过一对一关联起来
关于多对多:
1 # 多对多的方式: 2 # 1. ORM ManyToManyField()自动帮我创建第三张表 --> 关系表中没有额外字段、ORM封装了很多方法可以使用: add() remove() set() clear() 3 4 # 2. 自己创建第三张表, 利用外键分别关联作者和书 这种方法关联查询比较麻烦,因为没办法使用ORM提供的便利方法 5 6 # 3. 自己创建第三张表,用ORM的ManyToManyField()的through指定表名(自建的关系表) --> 可向关系表中添加额外字段, 使用此种方式没有ORM封装的方法可使用 注: through_fields = (field1, field2) field1是关系表通过哪个属性可以找到这张表 7 8 9 # 我们应该用哪种? 看情况: 10 # 如果你第三张表没有额外的字段,就用第一种 11 # 如果你第三张表有额外的字段,就用第三种或第一种 12 13 # 有额外字段的实际情况: 14 """ 15 相亲网站: 16 Boy 17 girl = ManyToManyField(to=“Girl") 18 19 Girl 20 21 约会记录:多对多 22 id boy_id girl_id date 23 """
实例:
1 # 一对多: 2 class Publisher(models.Model): 3 id = models.AutoField(primary_key=True) 4 name = models.CharField(max_length=64, null=False, unique=True) 5 6 class Book(models.Model): 7 id = models.AutoField(primary_key=True) 8 title = models.CharField(max_length=64, null=False, unique=True) 9 # 和出版社关联的外键字段: 10 publisher = models.ForeignKey(to="Publisher") 11 # 数据库中没有publisher这个字段 这有publisher_id这个字段 12 13 # 一对一: 14 class Author(models.Model): 15 name = models.CharField(max_length=32) 16 info = models.OneToOneField(to='AuthorInfo') 17 18 class AuthorInfo(models.Model): 19 phone = models.CharField(max_length=11) 20 email = models.EmailField() 21 22 # 多对多1(系统自动生成第三张表 or 自己建第张方表): 23 class Book(models.Model): 24 id = models.AutoField(primary_key=True) 25 title = models.CharField(max_length=64, null=False, unique=True) 26 27 class Author(models.Model): 28 id = models.AutoField(primary_key=True) 29 name = models.CharField(max_length=32, null=False, unique=True) 30 book = models.ManyToManyField(to="Book") # 告诉ORM Author和Book是多对多关系 系统自动生成第三张表 31 32 # 多对多2(自己建第三张表 利用外键关联) 33 class Author2Book(models.Model): 34 id = models.AutoField(primary_key=True) 35 author = models.ForeignKey(to="Author") # 作者id 36 book = models.ForeignKey(to="Book") # 图书id 37 # 自己建表还可以新建字段 38 publish_date = models.DateField(auto_now_add=True)
多对多第三种方式:

(4)单表查询的双下划线用法
1 models.Book.objects.filter(id__gt=1) 2 models.Book.objects.filter(id__in=[1,2,3]) 3 models.Book.objects.filter(id__range=[1,5]) 4 models.Book.objects.filter(title__contains="python") 5 models.Book.objects.filter(title__icontains="python") 6 models.Book.objects.filter(title__startswith="python") 7 models.Book.objects.filter(title__endswith="python") 8 models.Book.objects.filter(publish_date__year=2017) 9 models.Book.objects.filter(publish_date__month=2)
4.ORM拓展
ORM详细内容:https://www.cnblogs.com/liwenzhou/p/8660826.html
(1)ORM查询
返回QuerySet对象:
- all(): 查询所有结果
- filter(**kwargs): 它包含了与所给筛选条件相匹配的对象
- exclude(**kwargs): 它包含了与所给筛选条件不匹配的对象
- order_by(*field): 对查询结果排序
- reverse(): 对查询结果反向排序,请注意reverse()通常只能在具有已定义顺序的QuerySet上调用(在model类的Meta中指定ordering或调用order_by()方法
- distinct(): 从返回结果中剔除重复纪录(如果你查询跨越多个表,可能在计算QuerySet时得到重复的结果。此时可以使用distinct(),注意只有在PostgreSQL中支持按字段去重
返回一个特殊的QuerySet对象:
- values(*field): 返回一个ValueQuerySet——一个特殊的QuerySet,运行后得到的并不是一系列model的实例化对象,而是一个可迭代的字典序列
- values_list(*field): 它与values()非常相似,它返回的是一个元组序列,values返回的是一个字典序列
返回一个具体对象:
- first(): 返回第一条记录
- last(): 返回最后一条记录
- get(**kwargs): 返回与所给筛选条件相匹配的对象,返回结果有且只有一个,如果符合筛选条件的对象超过一个或者没有都会抛出错误
返回布尔值:
exists(): 如果QuerySet包含数据,就返回True,否则返回False
返回数字:
count(): 返回数据库中匹配查询(QuerySet)的对象数量
多对多查询拓展:
1 def select_related(self, *fields) 2 # 性能相关:表之间进行join连表操作,一次性获取关联的数据。 3 4 总结: 5 1. select_related主要针一对一和多对一关系进行优化。 6 2. select_related使用SQL的JOIN语句进行优化,通过减少SQL查询的次数来进行优化、提高性能。 7 8 def prefetch_related(self, *lookups) 9 # 性能相关:多表连表操作时速度会慢,使用其执行多次SQL查询在Python代码中实现连表操作。 10 11 总结: 12 1. 对于多对多字段(ManyToManyField)和一对多字段,可以使用prefetch_related()来进行优化。 13 2. prefetch_related()的优化方式是分别查询每个表,然后用Python处理他们之间的关系。
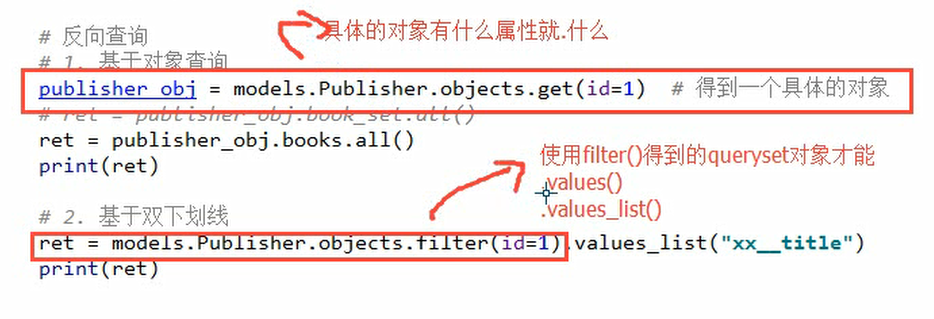
(2)外键的查询操作
1 # 正向查询: 2 # 查询第一本书的出版社 3 book_obj = models.Book.objects.all().first() 4 ret = book_obj.publisher 5 res = book_obj.publisher.name 6 print(ret, res) 7 # 查询id是7的书的出版社的名称 8 # 利用双下划线 跨表查询 双下划线就表示跨了一张表 9 ret = models.Book.objects.filter(id=7).values_list("publisher__name") 10 print(ret) 11 12 # 反向查询: 13 # 1. 基于对象查询 14 publisher_obj = models.Publisher.objects.get(id=1) # 得到一个具体的对象 15 # ret = publisher_obj.book_set.all() 16 # 在外键字段中加上related_name="books",之后就要使用下面的方法查询: 17 ret = publisher_obj.books.all() 18 print(ret) 19 # 2. 基于双下划线 20 ret = models.Publisher.objects.filter(id=1).values_list("books__title") 21 print(ret)
注意:
(3)多对多操作
查询:
1 # 查询第一个作者: 2 author_obj = models.Author.objects.first() 3 print(author_obj.name) 4 # 查询写过的书: 5 ret = author_obj.book.all() 6 print(author_obj.book, type(author_obj.book)) 7 print(ret)
增删改查操作:
1 # 1. create 2 # 通过作者创建一本书,会自动保存 3 # 做了两件事:1. 在book表里面创建一本新书,2. 在作者和书的关系表中添加关联记录 4 author_obj = models.Author.objects.first() 5 author_obj.book.create(title="wyb自传", publisher_id=1) 6 7 # 2. add 8 # 在wyb关联的书里面,再加一本id是8的书 9 book_obj = models.Book.objects.get(id=8) 10 author_obj.book.add(book_obj) 11 # 添加多个 12 book_objs = models.Book.objects.filter(id__gt=5) 13 author_obj.book.add(*book_objs) # 要把列表打散再传进去 14 # 直接添加id 15 author_obj.book.add(9) 16 17 # 3.remove 18 book_obj = models.Book.objects.get(title="跟Alex学泡妞") 19 author_obj.book.remove(book_obj) 20 # 把 id是8的记录 删掉 21 author_obj.book.remove(8) 22 23 # 4.clear 24 # 清空 25 jing_obj = models.Author.objects.get(id=2) 26 jing_obj.book.clear()
注意:
对于ForeignKey对象,clear()和remove()方法仅在null=True时存在
(4)分组和聚合查询
聚合查询:
aggregate()是QuerySet 的一个终止子句,意思是说,它返回一个包含一些键值对的字典。
键的名称是聚合值的标识符,值是计算出来的聚合值。键的名称是按照字段和聚合函数的名称自动生成出来的
用到的内置函数:
1 from django.db.models import Avg, Sum, Max, Min, Count
实例如下:
1 from django.db.models import Avg, Sum, Max, Min, Count 2 res = models.Book.objects.all().aggregate(price_avg=Avg("price"), price_max=Max("price"), price_min=Min("price")) 3 print(res) 4 print(res.get("price_avg"), res.get("price_max"), res.get("price_min")) 5 print(type(res.get("price_max"))) # <class 'decimal.Decimal'>
分组查询:
1 # 查询每一本书的作者个数 2 from django.db.models import Avg, Sum, Max, Min, Count 3 ret = models.Book.objects.all().annotate(author_num=Count("author")) 4 print(ret) 5 for book in ret: 6 print("书名:{},作者数量:{}".format(book.title, book.author_num)) 7 8 # 查询作者数量大于1的书 9 ret = models.Book.objects.all().annotate(author_num=Count("author")).filter(author_num__gt=1) 10 print(ret) 11 12 # 查询各个作者出的书的总价格13 ret = models.Author.objects.all().annotate(price_sum=Sum("book__price")) 14 print(ret) 15 for i in ret: 16 print(i, i.name, i.price_sum) 17 print(ret.values_list("id", "name", "price_sum"))
(5)F查询和Q查询
F查询:
在上面所有的例子中,我们构造的过滤器都只是将字段值与某个常量做比较。如果我们要对两个字段的值做比较,那该怎么做呢?
Django 提供 F() 来做这样的比较。F() 的实例可以在查询中引用字段,来比较同一个 model 实例中两个不同字段的值
F查询实例:
1 from django.db.models import F 2 3 # 查询评论数大于收藏数的书籍 4 models.Book.objects.filter(comment_num__gt=F('keep_num')) 5 6 # 修改操作也可以使用F函数,比如将每一本书的价格提高30元 7 models.Book.objects.all().update(price=F("price")+30) 8 9 # 修改字段: 10 from django.db.models.functions import Concat 11 from django.db.models import Value 12 models.Book.objects.all().update(title=Concat(F("title"), Value("("), Value("第一版"), Value(")")))
Q查询:
filter() 等方法中的关键字参数查询都是一起进行“AND” 的。 如果你需要执行更复杂的查询(例如OR语句),你可以使用Q对象
Q查询实例:
1 from django.db.models import Q 2 # 查询 卖出数大于1000,并且 价格小于100的所有书 3 ret = models.Book.objects.filter(maichu__gt=1000, price__lt=100) 4 print(ret) 5 6 # 查询 卖出数大于1000,或者 价格小于100的所有书 7 ret = models.Book.objects.filter(Q(maichu__gt=1000) | Q(price__lt=100)) 8 print(ret) 9 10 # Q查询和字段查询同时存在时, 字段查询要放在Q查询的后面 11 ret = models.Book.objects.filter(Q(maichu__gt=1000) | Q(price__lt=100), title__contains="金老板") 12 print(ret)
ORM拓展内容总结:
1 #分组和聚合 2 # 聚合: 3 from django.db.models import Avg, Sum, Max, Min, Count 4 models.Book.objects.all().aggregate(Avg("price")) 5 6 # 分组: 7 book_list = models.Book.objects.all().annotate(author_num=Count("author")) 8 9 # F和Q 10 # 当需要字段和字段作比较的时候用F查询 11 # 当查询条件是 或 的时候 用Q查询,因为默认的filter参数都是且的关系


1 ################################################################## 2 # PUBLIC METHODS THAT ALTER ATTRIBUTES AND RETURN A NEW QUERYSET # 3 ################################################################## 4 5 def all(self) 6 # 获取所有的数据对象 7 8 def filter(self, *args, **kwargs) 9 # 条件查询 10 # 条件可以是:参数,字典,Q 11 12 def exclude(self, *args, **kwargs) 13 # 条件查询 14 # 条件可以是:参数,字典,Q 15 16 def select_related(self, *fields) 17 性能相关:表之间进行join连表操作,一次性获取关联的数据。 18 19 总结: 20 1. select_related主要针一对一和多对一关系进行优化。 21 2. select_related使用SQL的JOIN语句进行优化,通过减少SQL查询的次数来进行优化、提高性能。 22 23 def prefetch_related(self, *lookups) 24 性能相关:多表连表操作时速度会慢,使用其执行多次SQL查询在Python代码中实现连表操作。 25 26 总结: 27 1. 对于多对多字段(ManyToManyField)和一对多字段,可以使用prefetch_related()来进行优化。 28 2. prefetch_related()的优化方式是分别查询每个表,然后用Python处理他们之间的关系。 29 30 def annotate(self, *args, **kwargs) 31 # 用于实现聚合group by查询 32 33 from django.db.models import Count, Avg, Max, Min, Sum 34 35 v = models.UserInfo.objects.values('u_id').annotate(uid=Count('u_id')) 36 # SELECT u_id, COUNT(ui) AS `uid` FROM UserInfo GROUP BY u_id 37 38 v = models.UserInfo.objects.values('u_id').annotate(uid=Count('u_id')).filter(uid__gt=1) 39 # SELECT u_id, COUNT(ui_id) AS `uid` FROM UserInfo GROUP BY u_id having count(u_id) > 1 40 41 v = models.UserInfo.objects.values('u_id').annotate(uid=Count('u_id',distinct=True)).filter(uid__gt=1) 42 # SELECT u_id, COUNT( DISTINCT ui_id) AS `uid` FROM UserInfo GROUP BY u_id having count(u_id) > 1 43 44 def distinct(self, *field_names) 45 # 用于distinct去重 46 models.UserInfo.objects.values('nid').distinct() 47 # select distinct nid from userinfo 48 49 注:只有在PostgreSQL中才能使用distinct进行去重 50 51 def order_by(self, *field_names) 52 # 用于排序 53 models.UserInfo.objects.all().order_by('-id','age') 54 55 def extra(self, select=None, where=None, params=None, tables=None, order_by=None, select_params=None) 56 # 构造额外的查询条件或者映射,如:子查询 57 58 Entry.objects.extra(select={'new_id': "select col from sometable where othercol > %s"}, select_params=(1,)) 59 Entry.objects.extra(where=['headline=%s'], params=['Lennon']) 60 Entry.objects.extra(where=["foo='a' OR bar = 'a'", "baz = 'a'"]) 61 Entry.objects.extra(select={'new_id': "select id from tb where id > %s"}, select_params=(1,), order_by=['-nid']) 62 63 def reverse(self): 64 # 倒序 65 models.UserInfo.objects.all().order_by('-nid').reverse() 66 # 注:如果存在order_by,reverse则是倒序,如果多个排序则一一倒序 67 68 69 def defer(self, *fields): 70 models.UserInfo.objects.defer('username','id') 71 或 72 models.UserInfo.objects.filter(...).defer('username','id') 73 #映射中排除某列数据 74 75 def only(self, *fields): 76 #仅取某个表中的数据 77 models.UserInfo.objects.only('username','id') 78 或 79 models.UserInfo.objects.filter(...).only('username','id') 80 81 def using(self, alias): 82 指定使用的数据库,参数为别名(setting中的设置) 83 84 85 ################################################## 86 # PUBLIC METHODS THAT RETURN A QUERYSET SUBCLASS # 87 ################################################## 88 89 def raw(self, raw_query, params=None, translations=None, using=None): 90 # 执行原生SQL 91 models.UserInfo.objects.raw('select * from userinfo') 92 93 # 如果SQL是其他表时,必须将名字设置为当前UserInfo对象的主键列名 94 models.UserInfo.objects.raw('select id as nid from 其他表') 95 96 # 为原生SQL设置参数 97 models.UserInfo.objects.raw('select id as nid from userinfo where nid>%s', params=[12,]) 98 99 # 将获取的到列名转换为指定列名 100 name_map = {'first': 'first_name', 'last': 'last_name', 'bd': 'birth_date', 'pk': 'id'} 101 Person.objects.raw('SELECT * FROM some_other_table', translations=name_map) 102 103 # 指定数据库 104 models.UserInfo.objects.raw('select * from userinfo', using="default") 105 106 ################### 原生SQL ################### 107 from django.db import connection, connections 108 cursor = connection.cursor() # cursor = connections['default'].cursor() 109 cursor.execute("""SELECT * from auth_user where id = %s""", [1]) 110 row = cursor.fetchone() # fetchall()/fetchmany(..) 111 112 113 def values(self, *fields): 114 # 获取每行数据为字典格式 115 116 def values_list(self, *fields, **kwargs): 117 # 获取每行数据为元祖 118 119 def dates(self, field_name, kind, order='ASC'): 120 # 根据时间进行某一部分进行去重查找并截取指定内容 121 # kind只能是:"year"(年), "month"(年-月), "day"(年-月-日) 122 # order只能是:"ASC" "DESC" 123 # 并获取转换后的时间 124 - year : 年-01-01 125 - month: 年-月-01 126 - day : 年-月-日 127 128 models.DatePlus.objects.dates('ctime','day','DESC') 129 130 def datetimes(self, field_name, kind, order='ASC', tzinfo=None): 131 # 根据时间进行某一部分进行去重查找并截取指定内容,将时间转换为指定时区时间 132 # kind只能是 "year", "month", "day", "hour", "minute", "second" 133 # order只能是:"ASC" "DESC" 134 # tzinfo时区对象 135 models.DDD.objects.datetimes('ctime','hour',tzinfo=pytz.UTC) 136 models.DDD.objects.datetimes('ctime','hour',tzinfo=pytz.timezone('Asia/Shanghai')) 137 138 """ 139 pip3 install pytz 140 import pytz 141 pytz.all_timezones 142 pytz.timezone(‘Asia/Shanghai’) 143 """ 144 145 def none(self): 146 # 空QuerySet对象 147 148 149 #################################### 150 # METHODS THAT DO DATABASE QUERIES # 151 #################################### 152 153 def aggregate(self, *args, **kwargs): 154 # 聚合函数,获取字典类型聚合结果 155 from django.db.models import Count, Avg, Max, Min, Sum 156 result = models.UserInfo.objects.aggregate(k=Count('u_id', distinct=True), n=Count('nid')) 157 ===> {'k': 3, 'n': 4} 158 159 def count(self): 160 # 获取个数 161 162 def get(self, *args, **kwargs): 163 # 获取单个对象 164 165 def create(self, **kwargs): 166 # 创建对象 167 168 def bulk_create(self, objs, batch_size=None): 169 # 批量插入 170 # batch_size表示一次插入的个数 171 objs = [ 172 models.DDD(name='r11'), 173 models.DDD(name='r22') 174 ] 175 models.DDD.objects.bulk_create(objs, 10) 176 177 def get_or_create(self, defaults=None, **kwargs): 178 # 如果存在,则获取,否则,创建 179 # defaults 指定创建时,其他字段的值 180 obj, created = models.UserInfo.objects.get_or_create(username='root1', defaults={'email': '1111111','u_id': 2, 't_id': 2}) 181 182 def update_or_create(self, defaults=None, **kwargs): 183 # 如果存在,则更新,否则,创建 184 # defaults 指定创建时或更新时的其他字段 185 obj, created = models.UserInfo.objects.update_or_create(username='root1', defaults={'email': '1111111','u_id': 2, 't_id': 1}) 186 187 def first(self): 188 # 获取第一个 189 190 def last(self): 191 # 获取最后一个 192 193 def in_bulk(self, id_list=None): 194 # 根据主键ID进行查找 195 id_list = [11,21,31] 196 models.DDD.objects.in_bulk(id_list) 197 198 def delete(self): 199 # 删除 200 201 def update(self, **kwargs): 202 # 更新 203 204 def exists(self): 205 # 是否有结果 206 207 QuerySet方法大全
5.cookie和session
详细内容:https://www.cnblogs.com/wyb666/p/9068853.html
6.csrf详情
(1)什么是csrf
csrf:跨站请求伪造
百度解释:CSRF(Cross-site request forgery)跨站请求伪造,也被称为“One Click Attack”或者Session Riding,通常缩写为CSRF或者XSRF,是一种对网站的恶意利用。尽管听起来像跨站脚本(XSS),但它与XSS非常不同,XSS利用站点内的信任用户,而CSRF则通过伪装来自受信任用户的请求来利用受信任的网站。与XSS攻击相比,CSRF攻击往往不大流行(因此对其进行防范的资源也相当稀少)和难以防范,所以被认为比XSS更具危险性
一句话解释:CSRG是指通过通过伪造页面来欺骗用户,让用户在钓鱼网址上输入关键信息,然后修改部分数据提交给真正的服务端程序
(2)csrf实例
钓鱼网站的页面和正经网站的页面对浏览器来说有什么区别? (页面是怎么来的?)
- 钓鱼网站的页面是由 钓鱼网站的服务端给你返回的
- 正经网站的网页是由 正经网站的服务端给你返回的
钓鱼网站如何实现钓鱼:前端页面一模一样,但是在表单中隐藏了某些关键的input然后这些input写成无用的input显示在页面上,这些隐藏的input的value是固定值,无论你在那些无用的input上输入什么值,最后提交给服务端的值都是确定的
详情见下面实例:
真正的网站前端代码:
1 <!--__author__ = "wyb"--> 2 <!DOCTYPE html> 3 <html lang="en"> 4 <head> 5 <meta charset="UTF-8"> 6 <title>转账</title> 7 </head> 8 <body> 9 10 <h1>真正的网站</h1> 11 <form action="" method="post"> 12 <p> 13 转出: 14 <input type="text" name="from"> 15 </p> 16 <p> 17 转入: 18 <input type="text" name="to"> 19 </p> 20 <p> 21 金额: 22 <input type="text" name="money"> 23 </p> 24 <p> 25 <input type="submit" value="转账"> 26 </p> 27 28 </form> 29 30 </body> 31 </html>
真正的网站后端代码:
1 # 真正网站的服务端: 2 def transfer(request): 3 if request.method == "GET": 4 return render(request, "test/transfer_test.html") 5 from_ = request.POST.get("from") 6 to_ = request.POST.get("to") 7 money = request.POST.get("money") 8 print("{} 给 {} 转了 {}钱".format(from_, to_, money)) 9 return HttpResponse("转账成功!")
钓鱼网站前端代码:
1 <!DOCTYPE html> 2 <html lang="en"> 3 <head> 4 <meta charset="UTF-8"> 5 <title>转账</title> 6 </head> 7 <body> 8 9 <h1>钓鱼的网站</h1> 10 <form action="http://127.0.0.1:8000/basic/transfer/" method="post"> 11 <p> 12 转出: 13 <input type="text" name="from"> 14 </p> 15 16 <p> 17 转入: 18 <input type="text" name=""> 19 <input type="text" name="to" style="display: none" value="黑客"> 20 </p> 21 <p> 22 金额: 23 <input type="text" name="money"> 24 </p> 25 <p> 26 <input type="submit" value="转账"> 27 </p> 28 </form> 29 </body> 30 </html>
钓鱼网站后端代码:
1 def transfer(request): 2 return render(request, "transfer.html")
两者页面如下:
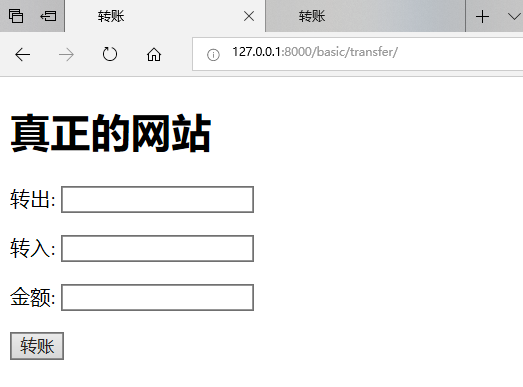
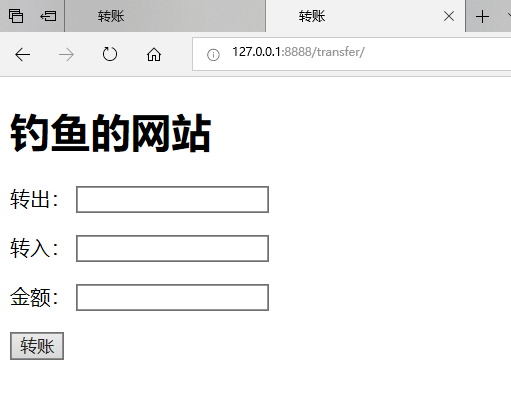
注:页面中的标题只是为了便于区分,正真的钓鱼网站可以说和原网站几乎一模一样,可以以假乱真
两个网站转账的数据相同时转账效果:
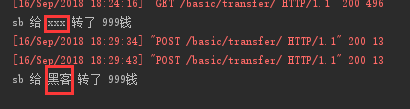
钓鱼网站通过隐藏的input框修改了转账的转入方,在钓鱼网站上的转入方无论你填什么最后转入方都是黑客
(3)Django内置的处理csrf问题的中间件
django中内置的处理csrf问题的中间件是:django.middleware.csrf.CsrfViewMiddleware
这个中间件做的事情:
- 在render返回页面的时候,在页面中塞了一个隐藏的input标签(eg: <input type="hidden" name="csrfmiddlewaretoken" value="8gthvLKulM7pqulNl2q3u46v1oEbKG7BSwg6qsHBv4zf0zj0UcbQmpbAdijqyhfE">)
- 当你提交POST数据的时候,它帮你做校验,如果校验不通过就拒绝这次请求
(4)django内置csrf中间件用法
在页面上 form表单 里面 写上 {% csrf_token %}就行了然后在settings.py中去掉csrf的注释,之后再用上面的实例测试效果如下:
钓鱼网站: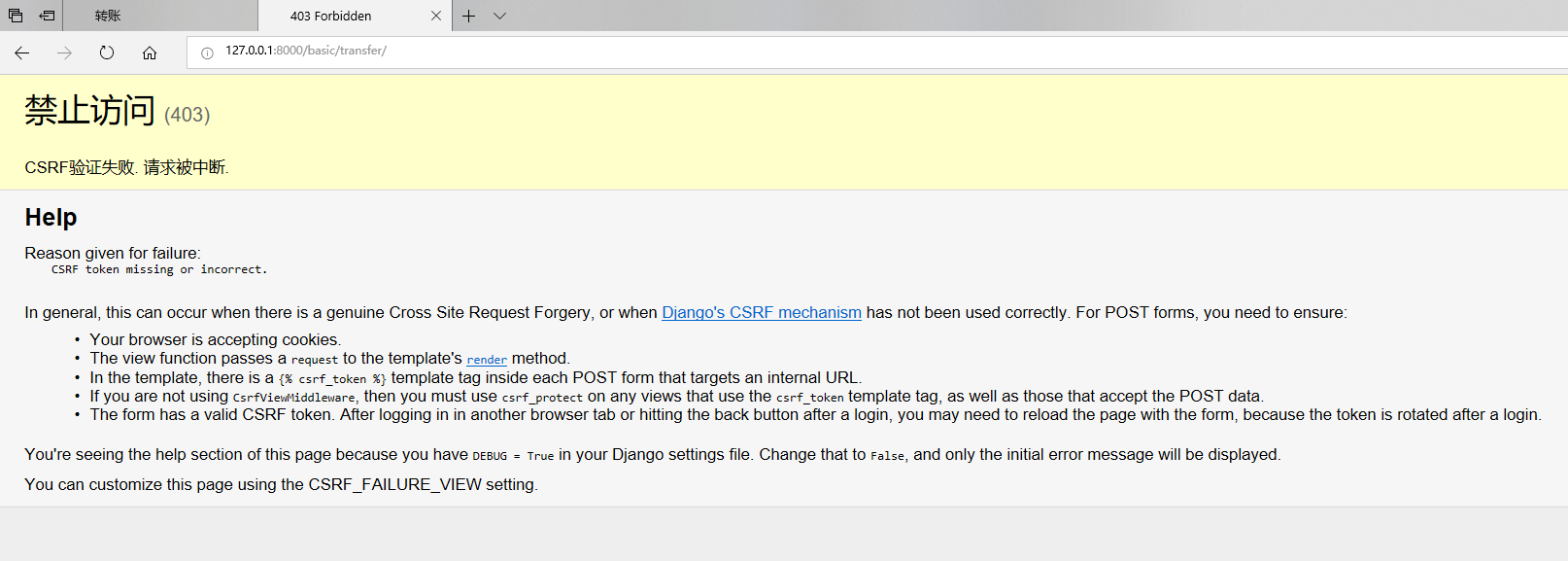
真正网站:
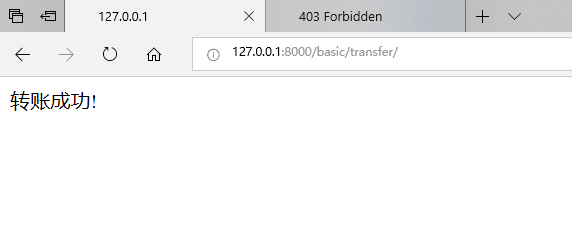
(5)csrf补充 - CSRF Token相关装饰器
CSRF Token相关装饰器在CBV只能加到dispatch方法上,或者加在视图类上然后name参数指定为dispatch方法。
- csrf_protect:为当前函数强制设置防跨站请求伪造功能,即便settings中没有设置全局中间件
- csrf_exempt:取消当前函数防跨站请求伪造功能,即便settings中设置了全局中间件
CBV写法:
1 from django.views.decorators.csrf import csrf_exempt, csrf_protect 2 from django.utils.decorators import method_decorator 3 4 class HomeView(View): 5 @method_decorator(csrf_exempt) 6 def dispatch(self, request, *args, **kwargs): 7 return super(HomeView, self).dispatch(request, *args, **kwargs) 8 9 def get(self, request): 10 return render(request, "home.html") 11 12 def post(self, request): 13 print("Home View POST method...") 14 return redirect("/index/") 15 16 17 # 或者这样写: 18 @method_decorator(csrf_exempt, name='dispatch') 19 class HomeView(View): 20 21 def dispatch(self, request, *args, **kwargs): 22 return super(HomeView, self).dispatch(request, *args, **kwargs) 23 24 def get(self, request): 25 return render(request, "home.html") 26 27 def post(self, request): 28 print("Home View POST method...") 29 return redirect("/index/")
FBV写法:
1 from django.views.decorators.csrf import csrf_exempt, csrf_protect 2 3 @csrf_exempt 4 def login(request): 5 xxx
7.django分页
(1)分页基本逻辑
books/?page=n --> n是整数,表示第几页
- page=1: 第一条到第十条数据
- page=2: 第十一条到第二十条数据
- page=3: 第二十一条到第三十条数据
- 以后依次类推
1 # 第一页: all_book = models.Book.objects.all()[0:10] # 1到10 2 # 第二页: all_book = models.Book.objects.all()[10:20] # 11到20 3 # 第三页: all_book = models.Book.objects.all()[20:30] # 21到30 4 # 第n页: n -> [(n-1)*10, n*10]
从request.GET中取出page对应的数,然后取出对应的数据传给前端即可,page对应的数默认设为1
(2)自定义分页
views.py:
1 # 原生分页 2 def books(request): 3 # 第一页: all_book = models.Book.objects.all()[0:10] # 1到10 4 # 第二页: all_book = models.Book.objects.all()[10:20] # 11到20 5 # 第三页: all_book = models.Book.objects.all()[20:30] # 21到30 6 # 第n页: n -> [(n-1)*10, n*10] 7 8 # 总数据是多少 9 data_count = models.Book.objects.all().count() 10 # 每一页显示多少条数据 11 per_page = 10 12 # 总共需要多少页码来展示 13 total_page, m = divmod(data_count, per_page) 14 if m: 15 total_page = total_page + 1 16 17 # 从URL中取参数: 18 page_num = request.GET.get("page", "1") 19 try: 20 page_num = int(page_num) 21 except Exception as e: 22 # 当输入页码不是正常数字时 默认返回1 23 page_num = 1 24 # 如果输入的数字大于total_page时 默认返回最大 25 if page_num > total_page: 26 page_num = total_page 27 28 # data_start和data_end分别保存数据的起始 29 data_start = (page_num - 1) * per_page 30 data_end = page_num * per_page 31 # 页面上总共展示多少页码(最多) 32 max_page = 10 33 if total_page < max_page: 34 max_page = total_page 35 half_max_page = max_page//2 36 # 页码开始和结束 37 page_start = page_num - half_max_page 38 page_end = page_num + half_max_page 39 if page_start <= 1: 40 page_start = 1 41 page_end = max_page + 1 42 if page_end > total_page: 43 page_start = total_page - max_page 44 page_end = total_page + 1 45 46 all_book = models.Book.objects.all()[data_start:data_end] 47 48 # 拼接HTML: 49 html_str_list = [] 50 # 加上上一页 51 # 判断 如果是第一页 就没有上一页 52 if page_num <= 1: 53 html_str_list.append('<li class="disabled"><a href="#" aria-label="Previous"><span aria-hidden="true">«</span></a></li>'.format(page_num-1)) 54 else: 55 html_str_list.append('<li><a href="/books/?page={}" aria-label="Previous"><span aria-hidden="true">«</span></a></li>'.format(page_num-1)) 56 # 加上第一页 -> 写死 57 html_str_list.append('<li><a href="/books/?page=1">首页</a></li>') 58 for i in range(page_start, page_end): 59 # 如果是当前页就加上active类 60 if i == page_num: 61 tmp = '<li class="active"><a href="/books/?page={0}">{0}</a></li>'.format(i) 62 else: 63 tmp = '<li><a href="/books/?page={0}">{0}</a></li>'.format(i) 64 html_str_list.append(tmp) 65 # 加上最后一页 66 html_str_list.append('<li><a href="/books/?page={}">尾页</a></li>'.format(total_page)) 67 # 加上下一页 68 # 判断 如果是最后一页 就没有下一页 69 if page_num >= total_page: 70 html_str_list.append('<li class="disabled"><a href="#" aria-label="Next"><span aria-hidden="true">»</span></a></li>'.format(page_num+1)) 71 else: 72 html_str_list.append('<li><a href="/books/?page={}" aria-label="Next"><span aria-hidden="true">»</span></a></li>'.format(page_num+1)) 73 page_html = "".join(html_str_list) 74 75 return render(request, "books.html", {"books": all_book, "page_html": page_html})
HTML:
1 <!--__author__ = "wyb"--> 2 <!DOCTYPE html> 3 <html lang="en"> 4 <head> 5 <meta charset="UTF-8"> 6 <title>书籍列表</title> 7 <link rel="stylesheet" href="https://cdn.bootcss.com/bootstrap/3.3.7/css/bootstrap.min.css" 8 integrity="sha384-BVYiiSIFeK1dGmJRAkycuHAHRg32OmUcww7on3RYdg4Va+PmSTsz/K68vbdEjh4u" crossorigin="anonymous"> 9 </head> 10 <body> 11 12 <div class="container"> 13 <table class="table table-bordered table-striped"> 14 <thead> 15 <tr> 16 <th>序号</th> 17 <th>id</th> 18 <th>书名</th> 19 </tr> 20 </thead> 21 <tbody> 22 {% for book in books %} 23 <tr> 24 <td>{{ forloop.counter }}</td> 25 <td>{{ book.id }}</td> 26 <td>{{ book.title }}</td> 27 </tr> 28 {% endfor %} 29 </tbody> 30 </table> 31 32 <nav aria-label="Page navigation"> 33 <ul class="pagination"> 34 {{ page_html|safe }} 35 </ul> 36 </nav> 37 38 </div> 39 40 41 </body> 42 </html>
封装之后的分页:
1 # 分页封装保存版 2 class Pagination(object): 3 def __init__(self, current_page, total_count, base_url, per_page=10, max_show=10): 4 """ 5 :param current_page: 当前页 6 :param total_count: 数据库中数据总数 7 :param base_url: url前缀 8 :param per_page: 每页显示多少条数据 9 :param max_show: 最多显示多少页 10 """ 11 try: 12 current_page = int(current_page) 13 except Exception as e: 14 current_page = 1 15 16 self.current_page = current_page 17 self.total_count = total_count 18 self.base_url = base_url 19 self.per_page = per_page 20 self.max_show = max_show 21 22 # 总页码 23 total_page, more = divmod(total_count, per_page) 24 if more: 25 total_page += 1 26 self.total_page = total_page 27 28 # 左边间隔的页码和右边间隔的页码 29 # 10 -> 4和5 11 -> 5和5 30 if max_show % 2 == 0: 31 self.left_show = max_show // 2 - 1 32 self.right_show = max_show // 2 33 else: 34 self.left_show = self.right_show = max_show // 2 35 36 @property 37 def start(self): 38 return (self.current_page - 1) * self.per_page 39 40 @property 41 def end(self): 42 return self.current_page * self.per_page 43 44 def page_html(self): 45 46 if self.current_page <= self.left_show: 47 show_start = 1 48 show_end = self.max_show 49 else: 50 if self.current_page + self.right_show >= self.total_page: 51 show_start = self.total_page - self.max_show + 1 52 show_end = self.total_page 53 else: 54 show_start = self.current_page - self.left_show 55 show_end = self.current_page + self.right_show 56 57 # 存html的列表 58 page_html_list = [] 59 60 # 加首页 61 first_li = '<li><a href="{}?page=1">首页</a></li>'.format(self.base_url) 62 page_html_list.append(first_li) 63 # 加上一页 64 if self.current_page == 1: 65 prev_li = '<li><a href="#">上一页</a></li>' 66 else: 67 prev_li = '<li><a href="{0}?page={1}">上一页</a></li>'.format(self.base_url, self.current_page - 1) 68 page_html_list.append(prev_li) 69 70 # 生成页面上显示的页码 71 for i in range(show_start, show_end + 1): 72 if i == self.current_page: 73 li_tag = '<li class="active"><a href="{0}?page={1}">{1}</a></li>'.format(self.base_url, i) 74 else: 75 li_tag = '<li><a href="{0}?page={1}">{1}</a></li>'.format(self.base_url, i) 76 page_html_list.append(li_tag) 77 78 # 加下一页 79 if self.current_page == self.total_page: 80 next_li = '<li><a href="#">下一页</a></li>' 81 else: 82 next_li = '<li><a href="{0}?page={1}">下一页</a></li>'.format(self.base_url, self.current_page + 1) 83 page_html_list.append(next_li) 84 # 加尾页 85 page_end_li = '<li><a href="{0}?page={1}">尾页</a></li>'.format(self.base_url, self.total_page) 86 page_html_list.append(page_end_li) 87 88 return "".join(page_html_list)
封装的分页的使用方法:
1 # 使用封装的分页 2 def books2(request): 3 data = models.Book.objects.all() 4 pager = Pagination(request.GET.get("page"), len(data), request.path_info) 5 book_list = data[pager.start:pager.end] 6 page_html = pager.page_html() 7 return render(request, "books.html", {"books": book_list, "page_html": page_html})
注:books.html见上面的HTML
(3)django内置分页
1 from django.shortcuts import render 2 from django.core.paginator import Paginator, EmptyPage, PageNotAnInteger 3 4 L = [] 5 for i in range(999): 6 L.append(i) 7 8 def index(request): 9 current_page = request.GET.get('p') 10 11 paginator = Paginator(L, 10) 12 # per_page: 每页显示条目数量 13 # count: 数据总个数 14 # num_pages:总页数 15 # page_range:总页数的索引范围,如: (1,10),(1,200) 16 # page: page对象 17 try: 18 posts = paginator.page(current_page) 19 # has_next 是否有下一页 20 # next_page_number 下一页页码 21 # has_previous 是否有上一页 22 # previous_page_number 上一页页码 23 # object_list 分页之后的数据列表 24 # number 当前页 25 # paginator paginator对象 26 except PageNotAnInteger: 27 posts = paginator.page(1) 28 except EmptyPage: 29 posts = paginator.page(paginator.num_pages) 30 return render(request, 'index.html', {'posts': posts})
1 <!DOCTYPE html> 2 <html> 3 <head lang="en"> 4 <meta charset="UTF-8"> 5 <title></title> 6 </head> 7 <body> 8 <ul> 9 {% for item in posts %} 10 <li>{{ item }}</li> 11 {% endfor %} 12 </ul> 13 14 <div class="pagination"> 15 <span class="step-links"> 16 {% if posts.has_previous %} 17 <a href="?p={{ posts.previous_page_number }}">Previous</a> 18 {% endif %} 19 <span class="current"> 20 Page {{ posts.number }} of {{ posts.paginator.num_pages }}. 21 </span> 22 {% if posts.has_next %} 23 <a href="?p={{ posts.next_page_number }}">Next</a> 24 {% endif %} 25 </span> 26 27 </div> 28 </body> 29 </html>

