
jieba库及wordcloud库的使用
知识内容:
1.jieba库的使用
2.wordcloud库的使用
参考资料:
https://github.com/fxsjy/jieba
https://blog.csdn.net/fontthrone/article/details/72775865
一、jieba库的使用
1.jieba库介绍
jieba是优秀的中文分词第三方库,使用pip安装后可以使用其来对中文文本进行分词
特点:
-
支持三种分词模式:
- 精确模式,试图将句子最精确地切开,适合文本分析,单词无冗余;
- 全模式,把句子中所有的可以成词的词语都扫描出来, 速度非常快,但是不能解决歧义,存在冗余;
- 搜索引擎模式,在精确模式的基础上,对长词再次切分,提高召回率,适合用于搜索引擎分词。
-
支持繁体分词
-
支持自定义词典
-
MIT 授权协议
2.jieba库方法
(1)jieba库3种分词方法(3种模式)
3种模式对应的方法如下:
- cut(s)和lcut(s) # 精确模式
- lcut(s, cut_all=True) # 全模式(存在冗余)
- cut_for_search(s)和lcut_for_search(s) # 搜索模式(存在冗余)
注:cut()和lcut()的不同:cut返回的是生成器,lcut返回的是列表。cut_for_search()和lcut_for_search()也是前者返回生成器,后者返回列表
另外:
cut方法lcut方法接受三个输入参数: 需要分词的字符串;cut_all 参数用来控制是否采用全模式;HMM 参数用来控制是否使用 HMM 模型cut_for_search方法和lcut_for_searchlcut_for_search接受两个参数:需要分词的字符串;是否使用 HMM 模型。该方法适合用于搜索引擎构建倒排索引的分词,粒度比较细- 待分词的字符串可以是 unicode 或 UTF-8 字符串、GBK 字符串。注:不建议直接输入 GBK 字符串,可能无法预料地错误解码成 UTF-8
示例:
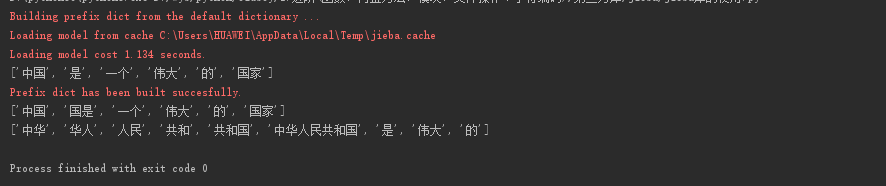
1 import jieba 2 3 s = "中国是一个伟大的国家" 4 res1 = jieba.lcut(s) # 精确模式 5 res2 = jieba.lcut(s, cut_all=True) # 全模式(存在冗余) 6 res3 = jieba.lcut_for_search("中华人民共和国是伟大的") # 搜索模式(存在冗余) 7 8 print(res1, res2, res3, sep="\n")
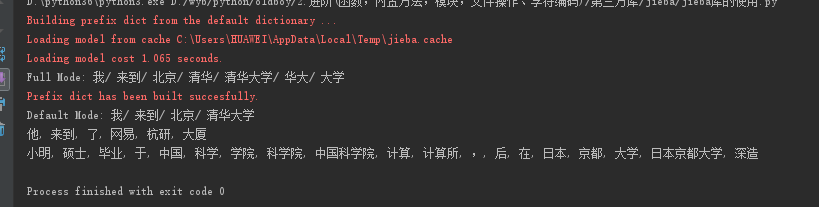
1 import jieba 2 3 seg_list = jieba.cut("我来到北京清华大学", cut_all=True) 4 print("Full Mode: " + "/ ".join(seg_list)) # 全模式 5 6 seg_list = jieba.cut("我来到北京清华大学", cut_all=False) 7 print("Default Mode: " + "/ ".join(seg_list)) # 精确模式 8 9 seg_list = jieba.cut("他来到了网易杭研大厦") # 默认是精确模式 10 print(", ".join(seg_list)) 11 12 seg_list = jieba.cut_for_search("小明硕士毕业于中国科学院计算所,后在日本京都大学深造") # 搜索引擎模式 13 print(", ".join(seg_list))
结果:
(2)向字典中添加新词或添加自定义词典
使用 add_word(word, freq=None, tag=None) 和 del_word(word) 可在程序中动态修改词典,当然也可以使用load_userdict(file_name)来导入自定义字典
最简单的用法:add_word() 直接向分词词典中添加新词
示例:
1 s = "李小福是创新办主任也是云计算方面的专家" 2 print(jieba.lcut(s)) 3 jieba.add_word("创新办") 4 print(jieba.lcut(s))

还可以使用load_userdict(file_name)导入自定义字典
示例:
自定义字典文件dict.txt内容如下:
1 云计算 5 2 李小福 2 nr 3 创新办 3 i 4 easy_install 3 eng 5 好用 300
1 s = "李小福是创新办主任也是云计算方面的专家" 2 print(jieba.lcut(s)) 3 jieba.load_userdict("dict.txt") 4 print(jieba.lcut(s))

3.文本词频统计通用代码
1 import string 2 import jieba 3 # 统计哈姆雷特和三国演义的词频 4 5 6 # 统计hamlet的词频 -> 可以用做英文的通用分词和统计 7 class Hamlet(object): 8 def __init__(self, name): 9 """ 10 :param name: 文本名字或路径 11 """ 12 self.text_name = name 13 14 def get_text(self): 15 """ 16 获取文本并进行相关处理 17 :return: 返回文本内容 18 """ 19 txt = open(self.text_name, "r").read().lower() 20 for ch in string.punctuation: 21 txt = txt.replace(ch, " ") 22 return txt 23 24 def count(self): 25 """ 26 统计单词出现的次数并输出结果 27 """ 28 hamlet_txt = self.get_text() 29 words = hamlet_txt.split() 30 counts = {} 31 for word in words: 32 counts[word] = counts.get(word, 0) + 1 33 items = list(counts.items()) 34 # key指定用列表中每一项中第二个值作为排序依据, reverse设置排序顺序 设为True的排序顺序为从大到小 35 items.sort(key=lambda x: x[1], reverse=True) 36 for i in range(10): 37 print(items[i][0], items[i][1]) 38 39 40 # 统计三国演义中人物名字的词频 -> 可以用做中文的通用分词及统计 41 class ThreeKindDom(object): 42 def __init__(self, name): 43 """ 44 :param name: 文本名字或路径 45 """ 46 self.text_name = name 47 48 def get_text(self): 49 """ 50 获取文本并进行相关处理 51 :return: 返回文本内容 52 """ 53 txt = open(self.text_name, "r", encoding="utf-8").read() 54 return txt 55 56 def split_txt(self): 57 """ 58 对文本进行分词 59 :return: 返回分词后的列表 60 """ 61 threekingdom_txt = self.get_text() 62 words = jieba.lcut(threekingdom_txt) 63 return words 64 65 def count(self): 66 """ 67 统计单词出现的次数并输出结果 68 """ 69 words = self.split_txt() 70 # excludes为要去掉的词 71 excludes = {"将军", "却说", "二人", "不可", "荆州", "不能", "如此", "商议", "如何", "左右", 72 "军马", "引兵", "军士", "次日", "主公", "大喜", "天下", "东吴", "于是", "今日", "魏兵"} 73 counts = {} 74 for word in words: 75 rword = word 76 if len(word) == 1: 77 continue 78 # 对一些特殊的词进行处理 79 elif word == "诸葛亮" or word == "孔明" or word == "孔明曰": 80 rword = "孔明" 81 elif word == "关公" or word == "云长": 82 rword = "关羽" 83 elif word == "玄德" or word == "玄德曰": 84 rword = "刘备" 85 elif word == "孟德" or word == "丞相": 86 rword = "曹操" 87 counts[rword] = counts.get(rword, 0) + 1 88 for word in excludes: 89 del counts[word] 90 items = list(counts.items()) 91 # key指定用列表中每一项中第二个值作为排序依据, reverse设置排序顺序 设为True的排序顺序为从大到小 92 items.sort(key=lambda x: x[1], reverse=True) 93 for i in range(8): 94 print(items[i][0], items[i][1]) 95 96 97 if __name__ == '__main__': 98 # s1 = Hamlet("hamlet.txt") 99 # s1.count() 100 101 s2 = ThreeKindDom("threekingdoms.txt") 102 s2.count()
二、wordcloud库的使用
1.wordcloud库介绍
wordcloud库是基于Python的词云生成类库,很好用,而且功能强大
词云如下所示:

2.wordcloud库基本使用

实例:
1 import wordcloud 2 3 c = wordcloud.WordCloud() # 生成词云对象 4 c.generate("wordcloud by Python") # 加载词云文本 5 c.to_file("wordcloud.png") # 输出词云文件
WordCloud方法的参数如下:
- width:指定词云对象生成的图片的宽度(默认为200px)
- height:指定词云对象生成的图片的高度(默认为400px)
- min_font_size:指定词云中字体最小字号,默认为4
- max_font_size:指定词云中字体最大字号
- font_step:指定词云中字体之间的间隔,默认为1
- font_path:指定字体文件路径
- max_words:指定词云中能显示的最多单词数,默认为200
- stop_words:指定在词云中不显示的单词列表
- background_color:指定词云图片的背景颜色,默认为黑色
指定词云形状:
1 import jieba 2 import wordcloud 3 from scipy.misc import imread 4 5 mask = imread("yun.png") # 读取图片数据到mask中 6 7 f = open("文档.txt", "r", encoding="utf-8") 8 data = f.read() 9 f.close() 10 11 ls = jieba.lcut(data) # 分词 12 txt = " ".join(ls) # 将列表中的单词连接成一个字符串 13 14 w = wordcloud.WordCloud(mask=mask) # 指定词云形状 15 w.generate(txt) 16 w.to_file("output.png")
3.生成词云通用代码
1 import jieba 2 import wordcloud 3 from scipy.misc import imread 4 5 6 def make_cloud(input_file, output_file, **kwargs): 7 """ 8 制作词云的通用代码 9 :param input_file: 输入文本的路径或名字 10 :param output_file: 输出图片的路径或名字 11 :param kwargs: WordCloud的参数(width、height、background_color、font_path、max_words) 12 :return: 13 """ 14 width = kwargs.get("width") 15 height = kwargs.get("height") 16 background_color = kwargs.get("background_color") 17 font_path = kwargs.get("font_path") 18 max_words = kwargs.get("max_words") 19 20 f = open(input_file, "r", encoding="utf-8") 21 data = f.read() 22 f.close() 23 24 ls = jieba.lcut(data) # 分词 25 txt = " ".join(ls) # 将列表中的单词连接成一个字符串 26 27 w = wordcloud.WordCloud(width=width, height=height, background_color=background_color, font_path=font_path, 28 max_words=max_words) 29 w.generate(txt) 30 w.to_file(output_file) 31 32 33 def make_cloud_png(input_file, output_file, png_file, **kwargs): 34 """ 35 用特殊图形制作词云的通用代码 36 :param input_file: 输入文本的路径或名字 37 :param output_file: 输出图片的路径或名字 38 :param png_file: 设置词云的图片形状的文件路径或名字 39 :param kwargs: WordCloud的参数(width、height、background_color、font_path、max_words) 40 :return: 41 """ 42 width = kwargs.get("width") 43 height = kwargs.get("height") 44 background_color = kwargs.get("background_color") 45 font_path = kwargs.get("font_path") 46 max_words = kwargs.get("max_words") 47 mask = imread(png_file) 48 49 f = open(input_file, "r", encoding="utf-8") 50 data = f.read() 51 f.close() 52 53 ls = jieba.lcut(data) # 分词 54 txt = " ".join(ls) # 将列表中的单词连接成一个字符串 55 56 w = wordcloud.WordCloud(width=width, height=height, background_color=background_color, font_path=font_path, 57 max_words=max_words, mask=mask) 58 w.generate(txt) 59 w.to_file(output_file)
too young too simple sometimes native!

 浙公网安备 33010602011771号
浙公网安备 33010602011771号