爬取中国大学排名
1.爬取目标
爬取http://www.zuihaodaxue.com/rankings.html中的如下链接中的具体数据:

具体页面中数据示例如下:
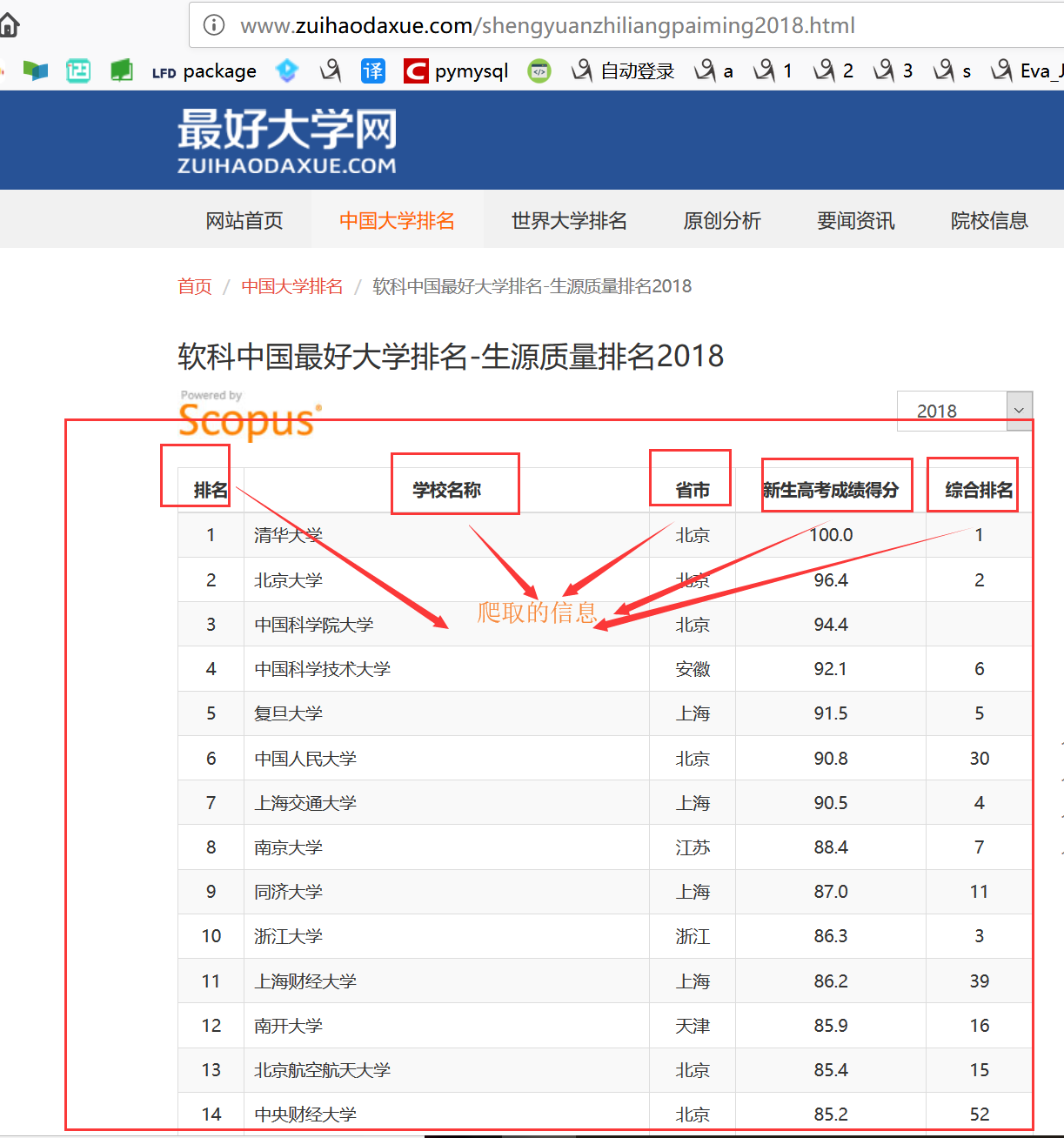
2.爬取步骤
(1)爬取http://www.zuihaodaxue.com/rankings.html页面中的10个链接地址及其文字描述
(2)根据链接地址爬取详细页面中的信息,每一个详细页面的信息存入列表中,列表中第一个数据存储的是排名名称,列表的第二个数据存储的是每一个详细页面中的表格中的表头。例如上面的拍, 、学校名称、省市等信息,后面的数据是表格下面每一行的数,最后将每一个详细页面的信息列表添加到结果列表中
(3)因时间关系未将数据存入数据库,直接输出显示数据
3.使用工具
requests请求库及BeautifulSoup解析库
4.代码
1 # __author__ = "wyb" 2 # date: 2018/5/22 3 import time 4 import requests 5 from bs4 import BeautifulSoup 6 7 headers = { 8 "User-Agent": "Mozilla/5.0 (Linux; Android 6.0; Nexus 5 Build/MRA58N) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/63.0.3239.84 Mobile Safari/537.36" 9 } 10 11 12 # 获取http://www.zuihaodaxue.com/rankings.html中的10个链接 13 def get_link(): 14 urls = [] 15 url = "http://www.zuihaodaxue.com/rankings.html" 16 html = requests.get(url, headers=headers) 17 html.encoding = html.apparent_encoding 18 soup = BeautifulSoup(html.text, "lxml") 19 # links为链接所在的a标签,names为链接对应的描述信息 20 links = soup.select("div.row div.col-lg-12.col-md-12.col-sm-12.col-xs-12 div.smallpic a") 21 for link in links: 22 href = link["href"] 23 href = "http://www.zuihaodaxue.com/" + href 24 urls.append(href) 25 # print(href) 26 # print(len(links)) 27 28 return urls 29 30 31 # 获取网页中的信息 32 def get_info(links): 33 info_s = [] 34 for link in links: 35 info = [] 36 html = requests.get(link, headers=headers) 37 html.encoding = html.apparent_encoding 38 soup = BeautifulSoup(html.text, "lxml") 39 # 获取排名名称 40 ranking_name = soup.select("h3.post-title")[0].text.strip() 41 info.append(ranking_name) 42 # 获取表格头部信息 43 items = soup.select("table.table-bordered thead th") 44 head = [] 45 for item in items: 46 head.append(item.text) 47 info.append(head) 48 # 获取表格主体信息 49 items = soup.select("table.table-bordered tbody tr") 50 for item in items: 51 body = [] 52 tds = item.select("td") 53 for td in tds: 54 body.append(td.text) 55 info.append(body) 56 info_s.append(info) 57 return info_s 58 59 60 # 展示获取的信息 61 def show_info(result): 62 # 循环10个页面爬取的结果 63 for r in result: 64 print(r[0]) 65 print(r[1]) 66 for index in range(2, len(r)): 67 items = r[index] 68 for item in items: 69 print(item, end=" ") 70 print() 71 72 73 if __name__ == '__main__': 74 start_time = time.time() 75 urls = get_link() 76 res = get_info(urls) 77 show_info(res) 78 end_time = time.time() 79 print(end_time-start_time)
too young too simple sometimes native!

 浙公网安备 33010602011771号
浙公网安备 33010602011771号