
python应用之爬虫实战2 请求库与解析库
知识内容:
1.requests库
2.selenium库
3.BeautifulSoup4库
4.re正则解析库
5.lxml库
参考:
http://www.cnblogs.com/wupeiqi/articles/5354900.html
http://www.cnblogs.com/linhaifeng/articles/7785043.html
一、requests库
1.安装及简单使用
(1)安装
1 pip3 install requests
(2)简单使用
1 import requests 2 3 r = requests.get("http://www.baidu.com") # 发起get请求 4 print(r.status_code) # 打印状态码 5 r.encoding = "utf-8" # 指定编码 6 print(r.text) # 输出文本内容
2.基于GET请求
requests.get(url, params=None, **kwargs)
(1)基本请求
1 import requests 2 3 url = "https://www.autohome.com.cn/news/" 4 5 response = requests.get(url) 6 response.encoding = response.apparent_encoding # 指定编码 7 print(response.text)
(2)带参数的GET请求
加headers
1 # 在请求头内将自己伪装成浏览器,否则百度不会正常返回页面内容 2 import requests 3 4 headers = { 5 'User-Agent': 'Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/62.0.3202.75 Safari/537.36', 6 } 7 8 response = requests.get('https://www.baidu.com/s?wd=python&pn=1', headers=headers) 9 print(response.text)
对url进行编码
1 # 在请求头内将自己伪装成浏览器,否则百度不会正常返回页面内容 2 import requests 3 4 headers = { 5 'User-Agent': 'Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/62.0.3202.75 Safari/537.36', 6 } 7 8 # 如果查询关键词是中文或者有其他特殊符号,则必须进行url编码 9 from urllib.parse import urlencode 10 11 wd = '六六六' 12 encode_res = urlencode({'k': wd}, encoding='utf-8') 13 keyword = encode_res.split('=')[1] 14 print(keyword) 15 url = 'https://www.baidu.com/s?wd=%s&pn=1' % keyword 16 17 response = requests.get(url, headers=headers) 18 res = response.text 19 print(res)
params参数
Requests模块允许使用params关键字传递参数,以一个字典来传递参数,例子如下:

import requests
data = {
"name":"zhaofan",
"age":22
}
response = requests.get("http://httpbin.org/get",params=data)
print(response.url)
print(response.text)
GET请求中headers常用元素如下:
1 #通常我们在发送请求时都需要带上请求头,请求头是将自身伪装成浏览器的关键,常见的有用的请求头如下 2 Host 3 Referer #大型网站通常都会根据该参数判断请求的来源 4 User-Agent #客户端 5 Cookie #Cookie信息虽然包含在请求头里,但requests模块有单独的参数处理他,headers内就不要放它了
(3)cookies
1 # 登录github,然后从浏览器中获取cookies,以后就可以直接拿着cookie登录了,无需输入用户名密码 2 3 import requests 4 5 Cookies = { 6 'user_session': 'ac0TP4aV3yyjfejv9dJOv1Erb_IJiSHTd_ac3s4N_sEZ71gK' 7 } 8 9 # github对请求头没有什么限制,我们无需定制user-agent,对于其他网站可能还需要定制 10 response = requests.get('https://github.com/settings/emails', cookies=Cookies) 11 12 13 print('1572834916@qq.com' in response.text) # True
3.基于POST请求
(1)requests模块的post方法和get方法的区别
requests.post()用法与requests.get()完全一致,特殊的是requests.post()有一个data参数,用来存放请求体数据
import requests
data = {
"name":"wyb",
"age": 21,
}
response = requests.post("http://httpbin.org/post", data=data)
print(response.text)
(2)发送post请求,模拟浏览器的登录行为
实例 模拟登录github
1 ''' 2 一 目标站点分析 3 浏览器输入https://github.com/login 4 然后输入错误的账号密码,抓包 5 发现: 登录行为是post并提交到:https://github.com/session且请求头包含cookie 6 而且请求体包含: 7 commit:Sign in 8 utf8:✓ 9 authenticity_token: taqxIh0Qs8Qm54Ov2WoR+RHq6O/1a8L/F960j/arN6xDEC9QArBTp6D4VFROYwLveIk+o5Ca5aBhWMEmhNmEnA== 10 login: 1572834916@qq.com 11 password:123 12 13 14 二 流程分析 15 先GET:https://github.com/login拿到初始cookie与authenticity_token 16 返回POST:https://github.com/session, 带上初始cookie,带上请求体(authenticity_token,用户名,密码等) 17 最后拿到登录cookie 18 19 ps:如果密码是密文形式,则可以先输错账号,输对密码,然后到浏览器中拿到加密后的密码 20 但是github的密码是明文,故不需使用上述的步骤 21 ''' 22 23 import requests 24 import re 25 26 # 第一次请求 27 r1 = requests.get('https://github.com/login') 28 r1_cookie = r1.cookies.get_dict() # 拿到初始cookie(未被授权) 29 authenticity_token = re.findall(r'name="authenticity_token".*?value="(.*?)"', r1.text)[0] # 从页面中拿到CSRF TOKEN 30 31 # 第二次请求:带着初始cookie和TOKEN发送POST请求给登录页面,带上账号密码 32 data = { 33 'commit': 'Sign in', 34 'utf8': '✓', 35 'authenticity_token': authenticity_token, 36 'login': '1572834916@qq.com', 37 'password': 'xxx' 38 } 39 r2 = requests.post('https://github.com/session', 40 data=data, 41 cookies=r1_cookie 42 ) 43 44 login_cookie = r2.cookies.get_dict() 45 46 # 第三次请求:以后的登录,拿着login_cookie就可以,比如访问一些个人配置 47 r3 = requests.get('https://github.com/settings/emails', 48 cookies=login_cookie) 49 50 print('1572834916@qq.com' in r3.text) # True
当然上面也可以用requests.session()来自动保存cookie信息,示例如下:


1 import requests 2 import re 3 4 session = requests.session() 5 # 第一次请求 6 r1 = session.get('https://github.com/login') 7 authenticity_token = re.findall(r'name="authenticity_token".*?value="(.*?)"', r1.text)[0] # 从页面中拿到CSRF TOKEN 8 9 # 第二次请求:带着初始cookie和TOKEN发送POST请求给登录页面,带上账号密码 10 data = { 11 'commit': 'Sign in', 12 'utf8': '✓', 13 'authenticity_token': authenticity_token, 14 'login': '1572834916@qq.com', 15 'password': 'xxx' 16 } 17 r2 = session.post('https://github.com/session', data=data) 18 19 20 # 第三次请求:以后的登录,拿着login_cookie就可以,比如访问一些个人配置 21 r3 = session.get('https://github.com/settings/emails') 22 23 print('1572834916@qq.com' in r3.text) # True
4.响应Response
(1)response属性
1 import requests 2 3 response = requests.get('http://www.zhihu.com') 4 # response属性 5 print(response.text) # 以文本形式打印网页源码 6 print(response.content) # 以字节流形式打印 7 8 print(response.status_code) # 打印状态码 9 print(response.headers) # 打印头信息 10 print(response.cookies) # 打印cookies信息 11 print(response.cookies.get_dict()) # 将cookies信息以字典方式打印 12 print(response.cookies.items()) # 打印cookies的键 13 14 print(response.url) # 输出响应的链接 15 16 print(response.encoding) # 输出响应的编码(从header中猜测的响应内容编码格式)
(2)编码问题
1 # 编码问题 2 import requests 3 response = requests.get('http://www.autohome.com/news') 4 5 # 将编码设置为网站的编码(不设置可能无法显示中文) 6 response.encoding = response.apparent_encoding 7 print(response.text)
(3)获取二进制数据
1 import requests 2 3 response = requests.get('https://timgsa.baidu.com/timg?image&quality=80&size=b9999_10000&sec=1509868306530&di=712e4ef3ab258b36e9f4b48e85a81c9d&imgtype=0&src=http%3A%2F%2Fc.hiphotos.baidu.com%2Fimage%2Fpic%2Fitem%2F11385343fbf2b211e1fb58a1c08065380dd78e0c.jpg') 4 5 # 以字节流的形式写入文件 6 with open('girl.jpg', 'wb') as f: 7 f.write(response.content)
1 #stream参数:一点一点的取,比如下载视频时,如果视频100G,用response.content然后一下子写到文件中是不合理的 2 3 import requests 4 5 response=requests.get('https://gss3.baidu.com/6LZ0ej3k1Qd3ote6lo7D0j9wehsv/tieba-smallvideo-transcode/1767502_56ec685f9c7ec542eeaf6eac93a65dc7_6fe25cd1347c_3.mp4', 6 stream=True) 7 8 with open('b.mp4','wb') as f: 9 for line in response.iter_content(): 10 f.write(line)
(4)解析json
1 #解析json 2 import requests 3 import json 4 5 response=requests.get('http://httpbin.org/get') 6 res1=json.loads(response.text) # 太麻烦 7 res2=response.json() # 直接获取json数据 8 9 print(res1 == res2) # True
5.所有方法及所有参数
(1)requests模块中所有方法
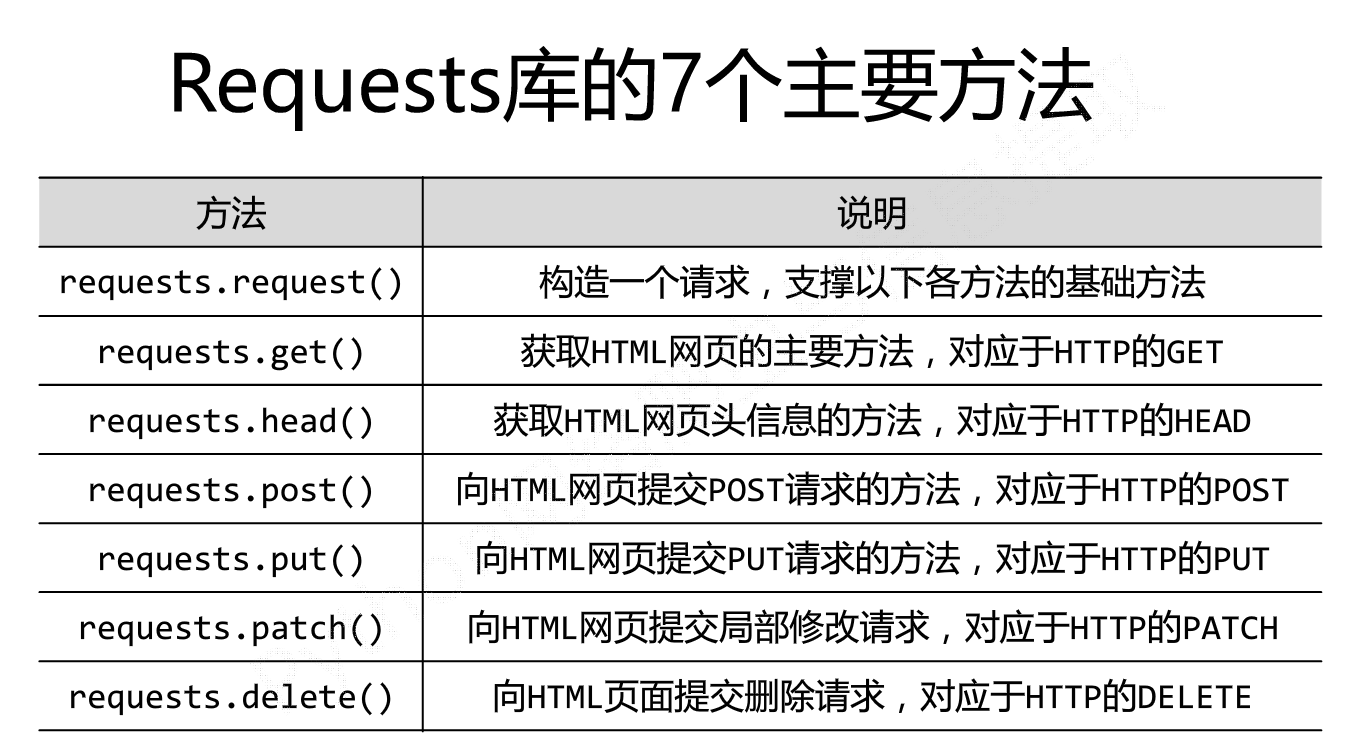
1 requests.get(url, params=None, **kwargs) 2 requests.post(url, data=None, json=None, **kwargs) 3 requests.put(url, data=None, **kwargs) 4 requests.head(url, **kwargs) 5 requests.delete(url, **kwargs) 6 requests.patch(url, data=None, **kwargs) 7 requests.options(url, **kwargs) 8 9 # 以上方法均是在此方法的基础上构建 10 requests.request(method, url, **kwargs)
(2)requests模块中的参数
重要的参数:
- method: 提交方式
- url: 提交地址
- params: 在URL中传递的参数,GET中独有
requests.request(
method='GET',
url= 'http://www.oldboyedu.com',
params = {'k1':'v1','k2':'v2'}
)
请求的链接:http://www.oldboyedu.com?k1=v1&k2=v2
- data: 在请求体里传递的数据
requests.request(
method='POST',
url= 'http://www.oldboyedu.com',
params = {'k1':'v1','k2':'v2'},
data = {'use':'wyb','pwd': '123'}(也可以写成"user=wyb&pwd=123")
)
请求头: content-type: application/url-form-encod.....
请求体: "use=wyb&pwd=123"
- json 在请求体里传递的数据
requests.request(
method='POST',
url= 'http://www.oldboyedu.com',
params = {'k1':'v1','k2':'v2'},
json = {'use':'wyb','pwd': '123'}
)
请求头: content-type: application/json
请求体: "{'use':'wyb','pwd': '123'}"
注: 当字典中嵌套字典时使用json
- headers 请求头
requests.request(
method='POST',
url= 'http://www.oldboyedu.com',
params = {'k1':'v1','k2':'v2'},
json = {'use':'alex','pwd': '123'},
headers={
'Referer': 'http://dig.chouti.com/',
'User-Agent': "Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/56.0.2924.87 Safari/537.36"
}
)
- cookies Cookies
其他参数:
- files 上传文件
- auth 基本认知(headers中加入加密的用户名和密码)
- timeout 请求和响应的超时时间
- allow_redirects 是否允许重定向
- proxies 代理
- verify 是否忽略证书
- cert 证书文件
- stream 村长下大片
- session: 用于保存客户端历史访问信息
1 import requests 2 files= {"files":open("git.jpg","rb")} 3 response = requests.post("http://httpbin.org/post",files=files) 4 print(response.text)
(2)获取cookie
1 import requests 2 3 response = requests.get("http://www.baidu.com") 4 print(response.cookies) 5 6 for key,value in response.cookies.items(): 7 print(key+"="+value)
cookie的一个作用就是可以用于模拟登陆,做会话维持
1 import requests 2 s = requests.Session() 3 s.get("http://httpbin.org/cookies/set/number/123456") 4 response = s.get("http://httpbin.org/cookies") 5 print(response.text)
两次requests请求之间是独立的,通过创建一个session对象,两次请求都通过这个对象访问
(3)证书验证
现在的很多网站都是https的方式访问,所以这个时候就涉及到证书的问题
1 import requests 2 3 response = requests.get("https:/www.12306.cn") 4 print(response.status_code)
默认的12306网站的证书是不合法的,这样就会提示错误,为了避免这种情况的发生可以通过verify=False
但是这样是可以访问到页面,但是会提示:
InsecureRequestWarning: Unverified HTTPS request is being made. Adding certificate verification is strongly advised. See: https://urllib3.readthedocs.io/en/latest/advanced-usage.html#ssl-warnings InsecureRequestWarning)
解决方法为:
1 import requests 2 from requests.packages import urllib3 3 urllib3.disable_warnings() 4 response = requests.get("https://www.12306.cn",verify=False) 5 print(response.status_code)
这样就不会提示警告信息,当然也可以通过cert参数放入证书路径
(4)代理设置
1 import requests 2 3 proxies= { 4 "http":"http://127.0.0.1:9999", 5 "https":"http://127.0.0.1:8888" 6 } 7 response = requests.get("https://www.baidu.com",proxies=proxies) 8 print(response.text)
如果代理需要设置账户名和密码,只需要将字典更改为如下:
proxies = {
"http":"http://user:password@127.0.0.1:9999"
}
如果你的代理是通过sokces这种方式则需要pip install "requests[socks]"
proxies= {
"http":"socks5://127.0.0.1:9999",
"https":"sockes5://127.0.0.1:8888"
}
(5)超时设置 -> 通过timeout参数可以设置超时的时间
(6)认证设置 -> 如果碰到需要认证的网站可以通过requests.auth模块实现
import requests
from requests.auth import HTTPBasicAuth
response = requests.get("http://120.27.34.24:9001/",auth=HTTPBasicAuth("user","123"))
print(response.status_code)
当然这里还有一种方式
import requests
response = requests.get("http://120.27.34.24:9001/",auth=("user","123"))
print(response.status_code)
7.requests使用实例
1 # __author__ = "wyb" 2 # date: 2018/5/21 3 import requests 4 5 url = "https://item.jd.com/5036602.html" 6 headers = { 7 "User-Agent": "Mozilla/5.0 (Linux; Android 6.0; Nexus 5 Build/MRA58N) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/63.0.3239.84 Mobile Safari/537.36" 8 } 9 try: 10 res = requests.get(url, headers=headers) 11 res.raise_for_status() 12 res.encoding = res.apparent_encoding 13 print(res.status_code) 14 print(res.text) 15 except: 16 print("爬取失败")
1 # __author__ = "wyb" 2 # date: 2018/5/21 3 import requests 4 5 url = "http://www.baidu.com/s" 6 kv = {"wd": "python"} # 搜索关键词 7 8 try: 9 res = requests.get(url, params=kv) 10 print(res.url) 11 print(res.status_code) 12 res.raise_for_status() 13 print(res.text) 14 except: 15 print("爬取失败")
1 # __author__ = "wyb" 2 # date: 2018/5/21 3 import requests 4 5 url = "http://m.ip138.com/ip.asp?ip=" 6 7 try: 8 ip = "202.204.80.112" 9 res = requests.get(url+ip) 10 res.raise_for_status() 11 res.encoding = res.apparent_encoding 12 print(res.text[-500:]) 13 except: 14 print("爬取失败")
1 # __author__ = "wyb" 2 # date: 2018/5/26 3 4 import os 5 import requests 6 from bs4 import BeautifulSoup 7 import re 8 import time 9 10 headers = { 11 "User-Agent": "Mozilla/5.0 (Linux; Android 6.0; Nexus 5 Build/MRA58N) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/63.0.3239.84 Mobile Safari/537.36" 12 } 13 14 # url = "https://www.zhihu.com/question/22918070" # url为知乎链接 15 url = input("请输入知乎的链接>>>").strip() 16 links = [] 17 18 try: 19 html = requests.get(url, headers=headers) 20 soup = BeautifulSoup(html.text, 'html.parser') 21 # 用Beautiful Soup结合正则表达式来提取包含所有图片链接(img标签中,class=**,以.jpg格式结尾的链接)的语句 22 links = soup.find_all('img', src=re.compile(r'.jpg$')) 23 # print(links) 24 except Exception as e: 25 print("请输入正确的链接或查看网络是否连接!") 26 exit() 27 28 try: 29 # 设置保存图片的路径,否则会保存到程序当前路径 30 path = r'./images' # 路径前的r是保持字符串原始值的意思,就是说不对其中的符号进行转义 31 for link in links: 32 print(link.attrs['src']) 33 src = link.attrs['src'] 34 if not os.path.exists('imgs'): 35 os.mkdir('imgs') 36 img = requests.get(src, headers=headers) 37 import uuid 38 with open("imgs/%s.jpg" % uuid.uuid4(), "wb") as f: 39 f.write(img.content) 40 except Exception as e: 41 print() 42 else: 43 print("图片下载成功请到该程序目录下的imgs文件夹下查看") 44 45 print("牛不牛逼啊?") 46 47 time.sleep(5)
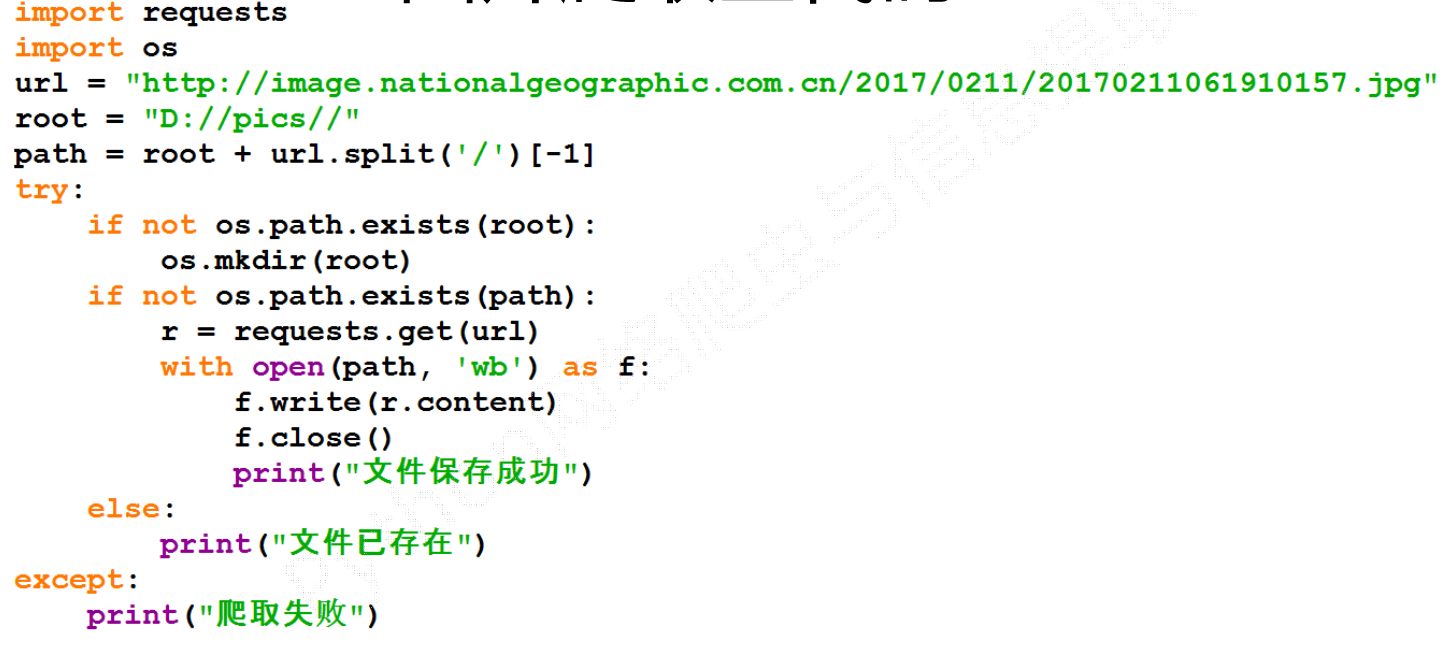
爬取图片原理:
二、selenium库
1.selenium介绍与其作用
selenium最初是一个自动化测试工具,而爬虫中使用它主要是为了解决requests无法直接执行JavaScript代码的问题
selenium本质是通过驱动浏览器,完全模拟浏览器的操作,比如跳转、输入、点击、下拉等,来拿到网页渲染之后的结果,可支持多种浏览器
1 from selenium import webdriver 2 browser=webdriver.Chrome() 3 browser=webdriver.Firefox() 4 browser=webdriver.PhantomJS() 5 browser=webdriver.Safari() 6 browser=webdriver.Edge()
注:个人推荐使用PhantomJS这个浏览器,直接百度下载安装,安装完了后配置一下path即可
2.selenium基本使用
1 from selenium import webdriver 2 from selenium.webdriver import ActionChains 3 from selenium.webdriver.common.by import By # 按照什么方式查找,By.ID,By.CSS_SELECTOR 4 from selenium.webdriver.common.keys import Keys # 键盘按键操作 5 from selenium.webdriver.support import expected_conditions as EC 6 from selenium.webdriver.support.wait import WebDriverWait # 等待页面加载某些元素 7 8 browser=webdriver.Chrome() 9 try: 10 browser.get('https://www.baidu.com') 11 12 input_tag=browser.find_element_by_id('kw') 13 input_tag.send_keys('美女') 14 input_tag.send_keys(Keys.ENTER) #输入回车 15 16 wait=WebDriverWait(browser,10) 17 # 等到id为content_left的元素加载完毕,最多等10秒 18 wait.until(EC.presence_of_element_located((By.ID,'content_left'))) 19 20 print(browser.page_source) 21 print(browser.current_url) 22 print(browser.get_cookies()) 23 24 finally: 25 browser.close()
三、BeautifulSoup4库
1 #安装 Beautiful Soup 2 pip install bs4 3 4 #安装解析器 5 pip install lxml 6 pip install html5lib
BeautifulSoup中可以使用的解释器如下:
| 解析器 | 使用方法 | 优势 | 劣势 |
|---|---|---|---|
| Python标准库 | BeautifulSoup(markup, "html.parser") |
|
|
| lxml HTML 解析器 | BeautifulSoup(markup, "lxml") |
|
|
| lxml XML 解析器 |
BeautifulSoup(markup, ["lxml", "xml"]) BeautifulSoup(markup, "xml") |
|
|
| html5lib | BeautifulSoup(markup, "html5lib") |
|
|
1 from bs4 import BeautifulSoup 2 html = """ 3 <html><head><title>The Dormouse's story</title></head> 4 <body> 5 <p class="title" name="dromouse"><b>The Dormouse's story</b></p> 6 <p class="story">Once upon a time there were three little sisters; and their names were 7 <a href="http://example.com/elsie" class="sister" id="link1"><!-- Elsie --></a>, 8 <a href="http://example.com/lacie" class="sister" id="link2">Lacie</a> and 9 <a href="http://example.com/tillie" class="sister" id="link3">Tillie</a>; 10 and they lived at the bottom of a well.</p> 11 <p class="story">...</p> 12 """ 13 14 soup = BeautifulSoup(html, 'html.parser') # 创建BeautifulSoup对象 15 print(soup.prettify()) # 打印soup对象(格式化输出)
(2)BeautifulSoup对象中的常用方法
- find_all方法:fin_all(tag, attributes, recursive, text, limit, keywords)
- find方法:find(tag, attributes, recursive, text, keywords)
- find()方法类似find_all()方法,只不过find_all()方法返回的是文档中符合条件的tag是一个集合,而find()方法返回的只是一个tag
- select()方法: # select方法中的选择器类似CS,将在后面详细介绍
- get_text()方法 -> 获取对象中的文本内容
find和find_all中的参数:
- tag:标签名
- attributes:一个标签的若干属性和其对应的值
- recursive:布尔变量,设置为True表示会递归查找,否则不会递归查找,find_all方法默认支持递归查找,一般情况下这个参数不需要设置
- text:用标签的文本内容匹配
- limit:只用于find_all方法,find其实等价于find_all参数limit等于1时的情况
- keyword:选择那些具有指定属性的标签
(3)BeautifulSoup对象中的属性
- 标签选择器:soup.标签名 -> 获得这个标签(多个这样的标签,返回的结果是第一个标签)
- 获取名称:soup.标签.name -> 获得该标签的名称
- 获取属性:soup.p.attrs['name']或soup.p['name'] -> 可以获取p标签的name属性值
- 获取内容:soup.p.string -> 可以获取第一个p标签的内容
- 嵌套选择:soup.head.title.string -> 获取head标签中的title标签中的内容
1 # __author__ = "wyb" 2 # date: 2018/5/21 3 from bs4 import BeautifulSoup 4 html = """ 5 <html><head><title>The Dormouse's story</title></head> 6 <body> 7 <p class="title" name="dromouse"><b>The Dormouse's story</b></p> 8 <p class="story">Once upon a time there were three little sisters; and their names were 9 <a href="http://example.com/elsie" class="sister" id="link1"><!-- Elsie --></a>, 10 <a href="http://example.com/lacie" class="sister" id="link2">Lacie</a> and 11 <a href="http://example.com/tillie" class="sister" id="link3">Tillie</a>; 12 and they lived at the bottom of a well.</p> 13 <p class="story">...</p> 14 """ 15 16 soup = BeautifulSoup(html, "html.parser") # 创建BeautifulSoup对象 17 18 print(soup.title) # 输出title标签 19 print(soup.title.name) # 输出title标签的name 20 print(soup.p) # 输出第一个p标签 21 print(soup.p.string) # 输出第一个p标签的内容 22 print(soup.p['class']) # 输出第一个p标签的class值 23 print(soup.p.b) # 嵌套查询
(4)BeautifulSoup中节点
子节点:contents和children
子孙节点:descendants
父节点:parent
祖先节点:list(enumerate(soup.a.parents))
兄弟节点:
- soup.a.next_siblings 获取后面的兄弟节点
- soup.a.previous_siblings 获取前面的兄弟节点
- soup.a.next_sibling 获取下一个兄弟标签
- souo.a.previous_sinbling 获取上一个兄弟标签
1 # __author__ = "wyb" 2 # date: 2018/5/21 3 from bs4 import BeautifulSoup 4 html = """ 5 <html> 6 <head><title>The Dormouse's story</title></head> 7 <body> 8 <p class="story"> 9 Once upon a time there were three little sisters; and their names were 10 <a href="http://example.com/elsie" class="sister" id="link1"> 11 <span>Elsie</span> 12 </a> 13 <a href="http://example.com/lacie" class="sister" id="link2">Lacie</a> 14 and 15 <a href="http://example.com/tillie" class="sister" id="link3">Tillie</a> 16 and they lived at the bottom of a well. 17 </p> 18 <p class="story">...</p> 19 """ 20 soup = BeautifulSoup(html, 'lxml') 21 22 # 获取子节点 23 print(soup.p.contents) # 将p标签下的所有子标签存入到了一个列表中 24 print(soup.p.children) # 迭代对象,而不是列表,只能通过循环的方式获取信息 25 26 # 获取子孙节点 27 print(soup.descendants) # 迭代对象,而不是列表,只能通过循环的方式获取信息 28 29 # 获取父节点 30 print(soup.p.parent) 31 32 print(soup.p.next_siblings) # 获取后面的兄弟节点 33 print(soup.p.previous_siblings) # 获取前面的兄弟节点 34 print(soup.p.next_sibling) # 获取下一个兄弟标签 35 print(soup.p.previous_sinbling) # 获取上一个兄弟标签
- .表示class #表示id
- 标签1,标签2 找到所有的标签1和标签2
- 标签1 标签2 找到标签1内部的所有的标签2
- [attr] 可以通过这种方法找到具有某个属性的所有标签
- [atrr=value] 例子[target=_blank]表示查找所有target=_blank的标签
- 获取内容:通过get_text()就可以获取文本内容
- 获取属性:获取属性可以通过[属性名]或者attrs[属性名]
1 # __author__ = "wyb" 2 # date: 2018/5/21 3 html = """ 4 <html><head><title>The Dormouse's story</title></head> 5 <body> 6 <p class="title"> 7 <b>The Dormouse's story</b> 8 Once upon a time there were three little sisters; and their names were 9 <a href="http://example.com/elsie" class="sister" id="link1"> 10 <span>Elsie</span> 11 </a> 12 <a href="http://example.com/lacie" class="sister" id="link2">Lacie</a> and 13 <a href="http://example.com/tillie" class="sister" id="link3">Tillie</a>; 14 <div class='panel-1'> 15 <ul class='list' id='list-1'> 16 <li class='element'>Foo</li> 17 <li class='element'>Bar</li> 18 <li class='element'>Jay</li> 19 </ul> 20 <ul class='list list-small' id='list-2'> 21 <li class='element'><h1 class='yyyy'>Foo</h1></li> 22 <li class='element xxx'>Bar</li> 23 <li class='element'>Jay</li> 24 </ul> 25 </div> 26 and they lived at the bottom of a well. 27 </p> 28 <p class="story">...</p> 29 """ 30 from bs4 import BeautifulSoup 31 soup = BeautifulSoup(html, 'lxml') 32 33 # 1、CSS选择器 34 print(soup.p.select('.sister')) 35 print(soup.select('.sister span')) 36 print(soup.select('#link1')) 37 print(soup.select('#link1 span')) 38 print(soup.select('#list-2 .element.xxx')) 39 40 41 # 2、获取属性 42 print(soup.select('#list-2 h1')[0].attrs) 43 44 # 3、获取内容 45 print(soup.select('#list-2 h1')[0].get_text())
5.BeautifulSoup使用实例
(1)BeautifulSoup简单使用
1 from bs4 import BeautifulSoup 2 3 html = """ 4 <html><head><title>The Dormouse's story</title></head> 5 <body> 6 <p class="title"> 7 <b>The Dormouse's story</b> 8 Once upon a time there were three little sisters; and their names were 9 <a href="http://example.com/elsie" class="sister" id="link1"> 10 <span>Elsie</span> 11 </a> 12 <a href="http://example.com/lacie" class="sister" id="link2">Lacie</a> and 13 <a href="http://example.com/tillie" class="sister" id="link3">Tillie</a>; 14 <div class='panel-1'> 15 <ul class='list' id='list-1'> 16 <li class='element'>Foo</li> 17 <li class='element'>Bar</li> 18 <li class='element'>Jay</li> 19 </ul> 20 <ul class='list list-small' id='list-2'> 21 <li class='element'><h1 class='yyyy'>Foo</h1></li> 22 <li class='element xxx'>Bar</li> 23 <li class='element'>Jay</li> 24 </ul> 25 </div> 26 and they lived at the bottom of a well. 27 </p> 28 <p class="story">...</p> 29 """ 30 31 soup = BeautifulSoup(html, "lxml") 32 for link in soup.find_all('a'): 33 print(link.get("href"))
(2)综合使用
爬取中国大学排名:https://www.cnblogs.com/wyb666/p/9068832.html

 浙公网安备 33010602011771号
浙公网安备 33010602011771号