2023 8 月总结
7.31 模拟赛 1
7:40 入场,T1 一眼 SB
8:10 T2 不会,md
8:30 还是不会/fn/fn/fn
8:45 过 T1
9:00 T3 求大。
9:20 T2 插不动,艹
10:00 T2 纯 sb
11:00 成功罚坐 1h,崽种!
11:45 还在罚坐,崽种!
感觉这场体验不太好,感觉题目质量不行。
T1 一眼秒了,看到至少一次很容易二项式反演,看到 l≤109l≤109 很容易矩阵快速幂,没有写的欲望。
T2 看着很原,大概是某一场省选模拟赛 T2 的中间的一个结论,下来找不到题,很烦/fn
知道大概需要组合意义转化题意之类,但是不太会,所以先考虑了一下其他的路径。
- 一个错误的 DP:f2i=∑f2jf2i−2j,考虑的是一个个合法括号序列的拼接,这个是一个分治 FFT 的形式。但是这样看着就很假,因为会算重。如果想要不算重的话,那么需要改乘 g2i−2j 表示单个括号序列的方案,算出 g 之后,剩下的是一个背包问题。但是我既然都算出来 g 了,不如直接 DP。
- 一个方向:能否将加入左括号的时候也赋予一个贡献?形式整齐之后说不定会出现一些道路。看起来很平方,但是并不是的。
- 老实的 DP:fi,j→fi+1,j+1,jfi,j→fi+1,j−1
- 发现一定是形如一段一段的连续下降段落,且一种下降段唯一对应一种合法的括号序列,那么考虑换个轴 DP。设 fi,j,k 表示考虑了 v≥i 的数字,一共有 j 个数字,v=i 出现了 k 个的贡献总和,转移 fi,j,kit(t+k,tt)→fi−1,j+t,t。这个形式看起来太扯淡了,唯一存在一点斯特林数的可能性,但是我不会。
回来发现还是不会组合意义,想了半天也难以 在将每一个左/右括号视作不同颜色 之后进行一个题目意思的合理转化。
时间来到 8:45,差不多了,滚回去写了 T1,一遍过/hanx
暂时不想看 T2 了,试了一个 T3 的 sb 的构造,即 (2+i,2n+1−i,3n+1−i) ,但是这样虽然能够满足 a2+b2<c2 的条件,但是无法满足 a+b>c, GG。
滚回来想 T2,先按照老实的 DP 写了一个 50pts 上去。
对着这个 DP 想如何优化,设出生成函数,发现 Fi+1(x)=xFi(x)+F′i(x),然后推了推导数法则之类,不会了。
想了想,看到 n≤107,想着不太可能是 O(n) 之类的吧,看起来这个又是一个多项式之类的,那么考虑一下插值?
插值发现连 n=5001 都插不对,真彩。
实在没有办法了,想着毕竟是某一道原题的结论,那么打表看看形状如何。
然后发现就是 (2n−1)!!,太愚蠢了。
T3 是构造,苦思冥想不会,摆烂,去证明了一下 T2 的结论。
大概有两种证明的方式:
- 拿出一个合法的括号序列,将里面的左右括号不论匹配是否相交的匹配的方案数总数即是所求。因为,一种新定义下的匹配方案必然唯一对应到一个合法的括号序列,且这样计算出来的方案正是原题目的组合意义。那么从后往前第一个没有确定的位置一定是右括号,需要敲定的就是左括号到底在哪里,第一次,方案数量是 2n−1,然后可以视作删去这两个括号,找到现在序列末尾的右括号递归执行。很容易看出答案就是 (2n−1)!!
- 生成函数大法。回到 Fi+1(x)=xFi(x)+F′i(x),F0=1,所求是 [x0]F2n,后续大概是构造一个 Gi=FieQiPi ,使得 Gi=G′i−1 啥啥的,不懂,找巨佬。
upd 2023.8.4 找到原题了,發,但是想了一个上午搞不懂当时是在容斥啥。
现在思考的话,把题目倒着过来看可能会舒服一点:
- 初始有 B 个左括号,(结束有 A 个左括号),操作 N 次,每次加一个左括号或者右括号
- 加入 x=N+A−B2 个左括号, y=N−A+B2 个右括号
- 加入一个右括号会选择某一个存在的左括号匹配,并删去二者
- 时刻保证左括号个数 ≥0
- 求匹配的方案数
那么,初始有 B 个左,增加 X 个左。设 i 个 ori 被删去,y−i 个 new 被删去。
意思是先从两个部分中选出对应数量的左 和右进行匹配,匹配的时候,由于 i 个固定放在最前面,所以和 i 匹配的右括号的放置在 长度为 N−A+B 的序列 的位置的方案数是那个下降幂
剩下 N−A+B−2i 长度的序列,可以自娱自乐了,由 T2 结论,知道是双阶乘。
还剩下 A−B+i 个,即 x−(y−i) 个新增的左括号,他们是最后的 A 的组成部分,因而不需要做匹配,只需要插入到序列中就好。那么等价于 N−A+B−i+1 个可空盒子,A−B+i 个球,方案数 (NA−B+i)
这样算是有问题的,样例都过不了!但是不知道!最后的贡献应当完整地包含两个部分,一个是本身操作序列的方案数,一个是进行匹配的方案。
仔细分析一下上面式子的含义,首先可以认为是把 B+x 个左括号摆在操作序列最前面,然后指定了 i+(y−i) 个被匹配,这些选出的左括号具体匹配给谁还不知道。然后给前 i 个匹配了右括号,并把给这些右括号分配了位置,此时这 i 个左括号的位置也被分配了,因为前 B 个是固定的,所以选出 i 个本来就有分配位置的意思。然后关注操作序列前 (B - i) + (N - A + B) 个位置,把其中还尚未确定的 N−A+B−2i 个位置单独提出来,既分配位置,又分配匹配地处理了 (y−i) 个 new 和剩下的右括号。最后一个组合数,只需要分配位置,那就分配位置咯。
将目光聚焦到最后这个组合数,一个疑虑是这个位置真的可以随意分配吗,需不需要满足最初 x 个左括号从左到右的顺序呢。比如,x = 2,有两个左括号,唤作 l, r,选其中 1 个和一个右括号 z 匹配,然后另外一个随便放,一共会产生这样的方案:选 l:rlz lrz lzr,选 r:lrz rlz rzl;其中 rlz lrz 算了两遍,lzr rzl 各自计算一次,md,看起来居然是正确的!
不知道了!鬼知道什么地方没有考虑好!
upd 知道了。
感觉转移系数大概是没有写错的,错的是第一步转化题意。
注意到原题目是要求本来开头是连续的 A 个左括号,并不要求最后剩下的 B 个没有匹配的左括号是连续的。
而这里的转化恰恰相反,钦定开头 B 个是连续的,那么这样当然就出现了问题。
發 的题解:
发现将操作序列对应的括号序列补全后(前面补 A 个左括号,后面补 B 个右括号,找出 N+A+B2 对括号的方案数量就是答案。
原因是从右往左扫到了一个 '(',此时后缀中右括号个数减去后缀左括号个数 就是当前怒气值,这个实际含义就是让这个左括号和后面的一个没有被匹配过的右括号匹配
//(理智了右括号次,而补全的序列后总怒气值为 0)
// 接下来考虑求配对方案数
// 一开始序列除了最左边 A 个位置后最右边 B 个位置都是未知的
// 为了方便我们直接不管那 B 个了,现在序列长度为 N + A
// 直接配对的话最左边的 A 个左括号可能会与自己匹配,容斥一下就好
// 此时最右边的 B 个右括号有 A-2i+N 个位置可以与自己匹配
// 剩下的 A-2i+N-B 个未知位置两两匹配就行了
8.1 模拟赛 2
8:40 T1 不需要最小化点数,求大。
9:30 T1 Runtime Error???
10:20 T1 自闭
10:40 放弃 T1
11:00 T2 结论假了。
T1 写了太多 bug...
开场一看 T1 就已经知道这道题可能会把自己卡很久,因为这种题目代码细节一看就很多。
感觉开始一段时间状态不是很好,脑子不太清楚,大概在 9:40 左右感觉上状态了。
T1 最开始读错题了,以为还需要满足的限制是总点数 ≤n,那么意思就是说要构造出来的树尽可能小,那么最重要的问题就是合并的问题。想了半天不会合并,case 实在是太多了,然后突然发现题目只输入 k,即限制个数。
T2 看到贡献形如 ar−al+min{x,y} ,以为可以先全部加上 an−a1,然后就可以简单操作,但是这显然是假的。之后瞬间感觉不可做了,写了一个 O(n2) 的 DP 润了。
T3 没咋看,上完一个二项式反演,知道后续是一个类似自然数拆分的 DP,但是我的方式的复杂度好大。
T1 哪吒的树
样例很良心,通过手模可以得到所需要判定的两个条件:
- u 的 k 级祖先只有一个
- u⇝anc 的所有路径距离一致
考察一个三元关系 u→v,v→w,u→w,发现在 u 是判定不了正确性的,只能在 v 来判定。
暴力地思考,只需要吧所有 u 的信息传给 v 即可。
暴力地实现,搞 n 个 set<pair> ,做一个拓扑排序,每次取出队头 u,先遍历它的 set 以判定合法性,然后令其 set 中距离最近的一个叫做 fath,然后 set[u] 全部扔进 set[fath]。
简单地思考,为了保证复杂度,使用启发式合并。启发式合并时,涉及到对某一个集合中的距离整体加减,维护一个 dlt 即可。
这样算下来就是 O(nlogn),原本的一条限制会被判定 log 次。
写出来 RE!,md,权值有点大,每次判定的时候需要使用 map ,复杂度 O(nlog2n)。
然后一直调不对,GG。
bugs:
- 没有判定存在环的情况,即有某些节点没有入队。
- toposort 的时候,每次只能让 fath 的度数 - 1,不然会导致提前把某一个 anc 加入队列,并且这个 anc 并没有拿到应有的信息;考场上想到了这个问题,但是没有细究,误认为反正可以判掉所有的三元关系。
- 随之而来的问题是,
set应该换成multiset,不然会意外导致某些节点没有入队。 - 随之而来的问题是,每次
deg[fath]不一定 −1,可能减少更多。 - long long 是 8 个字节,所以初始化的时候不能顺手写成
memset(a, 0, (n + 1) << 2)
然后发现跑出来之后,大概是数据比较弱,导致我的 nlog2n 时空代码复杂度爆踩线性做法!(无视离散化的 O(nlogn) )
线性做法:对于每一个限制,连边 <a,b,c>,和 反边 <b,a,−c> 每一个连通块随便选一个点作为起点跑 bfs。
T2 送信
O(n3), fi,j=min{fi−1,k+cost(i,k+1,j)}
O(n2), 注意到一个性质是每一个邮递员所处理的区间必然不会包含另外任何一个邮递员,所以状态数实际上是 O(n) 的。
然后就陷入了困境。
事实上,注意到每一个 cost 一定形如 2x+y 的样子,所以数轴上每一个 [i,i+1) 只会被覆盖 0/1/2 次,然后自然设 fi,0/1/2 dp 就好了。
感觉这个想法在考场上似乎灵光一现地出现过,但是当时杂念太多,把他掩盖了。
按着 fi,0/1/2 转移会发现不对,需要 fi,0/1/2/3/4,这都是小问题,带修上线段树维护转移矩阵即可。
T3 平方
大杂烩!
首先,设 gi 表示钦定有 i 个相邻乘积为平方数的方案数,那么 ans 可以二项式反演 O(n2) 得到
设 fi 表示长度为 i 的合法段的方案数,又知道 gi 是由 n−i 个段组成的。
设 F 是 f 的生成函数,那么 gi=[xn]Fn−i,这个可以 NTT O(n2logn)
考虑一个合法段 a1,a2,…,an,所有 a 的质因数的幂次的奇偶性一定相同,设 a1=∏pqii,x=∏pqimod2i,考虑枚举 x。
首先 x 是一个不含平方因子的数字 ⇔ μ2(x)=1;其次,每一个 a 可以表示成 xb2 的形式,其中 b2≤⌊mx⌋,所以:
容易注意到 ⌊√⌊mx⌋⌋ 取值只有 O(√m) 种,考虑做类似整除分块的操作。
设 ci=∑μ2(x)[⌊√⌊mx⌋⌋=i],di=∑mx=1μ2(x)
知道实际上,ci=dr[i]−dl[i]−1,这个 l,r 可以二分求出。
假如求出了 ci,利用 fn=∑√mi=1ciin,可以 O(n√m) 求出 f
现在唯一剩下的问题是筛 d,即莫比乌斯函数平方的前缀和,利用等式:
Proof:
μ2(x) 等价于 x 不含平方因子,设 x=∏pqii,y=∏p⌊qi2⌋i,那么
μ2(x)=[y==1]=∑d|yμ(d)
∑μ2(x)=∑x∑d|yμ(d)=∑dμ(d)∑y[d|y ∩ y2≤n]=∑√nd⌊nd2⌋μ(d)
用整除分块结合 杜教筛筛莫比乌斯函数前缀和,可以得到 d
复杂度是啥?不知道,设这部分复杂度叫做 O(T)
那么,总结上述过程:
其中,O(√mlog2m) 指的是对于每一个 c 二分左右边界(手写 sqrt 函数,二分)的复杂度,假装 O(T) 求出了所有需要的 d。
据 chroneZ 说 T=m25,不了解。
复杂度可以认为是 O(n√m+n2logn)
8.2 自习(tsx DP)
上午:补昨天总结 + 简单回顾二类斯特林
下午晚上:做了点题,补了点水土总结之类之类。
感觉今天整体效率不是很高啊,中午打了球之后没咋睡午觉摆了一会儿,下午有点昏昏沉沉的。
然后偶然发现 7 月 luogu div2 月赛的题解发出来了,临时决定把题补了。
P9461 众数 II
简单 luogu 月赛题,当时口胡了没写。
肯定不能对真序列 b 来考虑,肯定要挖掘 a 的性状
注意到题目两个性质:
- 序列形如 1,2,…a1,1,2,…,a2,…an
- 值域 106
第一反应是计算众数 ≥x 的方案数,如何计算呢
枚举 l,r,简单思考,发现如果里面存在 a[i]<x,那么众数必然不可能 ≥x
也就是说这个其实是一个经典的广义笛卡尔树的结构。
感觉感觉,搞个 solve(1, n, 1),分治下去 solve(1, x - 1, 2), solve(x + 1, n, 2) 啥啥的,随便算算贡献就好了。
具体的,假如有极长连续段 [L,R],使得 ∀i∈[L,R],ai≥x && a[L−1]<x,a[R+1]<x,我们干脆直接计算众数 =x 的方案数:
其中 si=si−1+ai,ssi=ssi−1+si
分别维护一下 F=∑(R−L+1)sR 和 G=(R−L+1)(R−L+2)2 就好。
复杂度线性
P9462 终点
智慧 luogu 月赛题,被打败了/ll
只能问中点是啥,而且居然可能中点在边上,这个看起来就很困难。
当时只想到了说可以区分出深度 >d2 的点,然后考虑如何递归做之类之类。
这样是不可做的。
考虑部分分 fai<i,已经知道 fa[2]=1
要好好利用给的是一个中点这个玩意,一个比较自然的想法是,在找 fa[x] 的时候,肯定是 log 次找到。
自然的,是不是每次只要问一下 (1,x),然后问 (得到的中点, x),一直问下去就好了!
现在唯一的问题是可能会问到中点在边上的情况,好处理,比如 (y,x) 中点在边上,那么问一下 (fa[y],x) 即可。令 fa[1]=2。
这样就获得了一个 ∑log2(depi) 的做法。
考虑推广这个做法,发现只要找到两个相邻点就好。
考虑先把所有点都和 1 问一遍,找到和 1 的距离 lowbit 最大的(即能取中点次数最多的)不断取中点即可得到一个和 1 相邻的点
找到之后,称其为 2, 意图效仿之前的操作,枚举一个点,然后找和 1 的中点。
但是现在的问题是,这个中点的父亲可能还没有确定,那有点尬。
问题不大,此时的想法是把这个点的询问先挂到这个中点上,到时候处理。
那么此时枚举顺序就需要讲究一点了,使用 bfs 优化上述过程,初始将 1 和 2 入队,将所有询问挂到 1。每次询问的时候,不确定就把询问挂上去;如果已经找到了某一个点的 fa,就把这个点入队;每次取出队首的时候,处理所有挂上去的询问。
n+∑log2(depi)
[EGOI2022] Lego Wall / 乐高墙
想出了做法,但是自己并没有意识到。。。
连通块显然是列的区间。
一眼丁真,鉴定为昨天的 T3。
设 fi 表示 n×i 的方格随便填的方案数,可以先算一行的, fi=fi−1+fi−2,或者 fi=∑j(i−jj) (枚举 2 的个数),然后搞个 n 次幂。
一个愚蠢的方法是直接无脑套用昨天 T3,gi=[xn]Fn−i 表示钦定 i 个,然后再搞一个二项式反演。
但是这样很没有必要啊,因为复杂度很不平衡,NNT 是 O(m2logm),但是由于只需要反演求一个值,所以反演部分是 O(m),这不是纯 sb。
考察容斥系数的特点,只有一段的时候为 1,每次增加一段,容斥系数乘上 −1。
设 gi 表示长度为 i 且满足要求的答案,
这样,复杂度平衡到 O(m2)。
过不了,考虑换一种 DP 的方式。
发现上一列对这一列的影响仅仅在于“突出”了多少个,设 fi,j 表示第 i 列,j 个位置被占据的方案数,这样做是 O(n2m) 的。
没有注意到 n×m≤5×105,这两个做法拼起来居然过了,fxxk。
[CF1250D]Conference Problem
写的做法的思路大概是,端点按 r 排序,然后通过手段处理出第一个与 li,ri 无关的 k(无关:设 Si 代表和 i 有交集的区间,i,k 无关 ⇔Si 和 Sk 无交集,即二者无法“两步”到达,这样才能保证给 i 染色的时候计算贡献不会影响到 k),然后 DP 就好。计算贡献使用了 BIT。
CF 的评论区给出了一个更为明亮的做法:
将 (li,ri) 放到二维平面轴上,新增 n 个以 (ri,li) 为右下端点的矩形(x∈[1,ri],y∈[li,∞]),问题转化为:
- 给没有颜色的矩形和点分配颜色,要求点和对应的矩形颜色一致
- 选一个矩形集合,最大化集合大小,使得集合中每一个矩形内部所有点的颜色都和矩形所分配的颜色一致。
将所有矩形按照 ri(右边界) 从小到大排序,设 dp[i][y][c] 表示处理前 i 个矩阵,纵坐标 ≥y 的部分都被涂上了颜色 c 的答案。
一个矩形的颜色定义为矩形中本来就确定的点的颜色,如果有多种颜色,那么删除这个矩形;如果都是 0(未确定),那么这个矩形的颜色也是 0.
考虑转移,对于 dp[i][j][k],如果矩形 i + 1 要选,发现一定会转移到 dp[i+1][max{j,l[i+1]}][∗]
特别计算 mx[j] 表示矩形内全部是不确定 且 dp[i][j][k] 没有“绑架” i+1 的情况,即不管染成啥颜色都可以。
那么 ∗ 只能取:点 i+1 的颜色(点 i+1 颜色是 k 或矩形颜色是 0) / 矩形的颜色 / k,O(1) 种,所以 dp 的复杂度就是 O(n2k)
需要预处理每个左上角的矩形的颜色之类之类,可以用 bitset + 二位前缀和之类之类。
8.3 模拟赛 3
7:45 入场
8:30 md,感觉脑子没有热起来!!
9:10 总算是过了,洗把脸清醒一下/oh/oh
10:00 T2 眉头
10:40 T2 致命缺陷
也就是说,这把 90min 过了 T1,然后剩下 3h 投入 T2,并且由于没有得到任何一个有正确性的 DP,光荣地获得了 0 分的好成绩。
srds,感觉做 T2 的时候时间过得很快,说明还是非常投入,即使结果不是很好,但是也是很美好的体验。
T2
感觉有点巧妙,提醒我当发现 DP 有点工业的时候,应当尝试先去寻找性质
其实吧,当时的想法是先打一个暴力 DP 出来再说,但是时间分配实在是有问题,当暴力确实不太能的时候是否应当考虑收手呢?是否因为是模拟赛就不太认真了?
考场首先考虑将相同的 a 缩在一起处理。
然后从下往上考虑,发现最后一个一定每一行都会放一个车,这些车肯定尽量放在 ≤a[n−1] 的位置比较符合贪心,然后发现对于一个 i,它最关心的是列 [ai,ai+1) 是否有车之类,然后设计了一个 DP。
发现方案数实在是不好计算啊,最开始没有注意到由于 ai 有 ci 个,所有一列的方案数是多样的;然后一直调一直调,不断处理一些边边角角的 bugs,断断续续更换了很多种转移的方式,陆陆续续地完善所有的转移。
然后没有想到 某个 i,即使 [ai,ai+1) 已经被下面的某些位置解决的了,但是还是可以选车的情况,这种情况就很致命了,因为这个车购买方案只能在 i 才能计算,但是一个车如果在列 x 买了,对于 aj<x 的时候还会出现失效白买的情况,这些内容是 DP状态 记录不了的东西。
好吧,那么换一个 DP 方向吧,考虑从上往下 DP,记录需要买多少个车”援助“上方,这样总可以计算方案数了!
但是转移实在难崩,case 太多太复杂,人写晕了都写不对。
warning:
Think twice, Code once.
solution:
(考场第一眼就知道) 最贪心的方案肯定从左下角开始斜着往上放,一直放到不能放为止。(但是没有放在心上,因为觉得这个算不了方案数啊)
那么首先考虑求出最少需要放 r 个, r=maxmin{ai,n−i+1}
考虑左下角这个 r×r 的正方形,发现任意一个 r 阶排列 pi,把车放在 (n−r+i,pi) 都会是一个合法的方案。
思考还没有其他可能的放置方案,首先对着一条对角线考虑。
发现似乎可能可以把对角线右上角的车 (n−r+1,r) 往左边移动一步,只要 an−r<=r−1,那么就会是一个合法解。
更进一步的,假装所有的车都可以左右平移,只要保证最后平移结果满足列 [1,an−r] 都有至少一个车就好了!
这个方案数可以随便用 DP 计算。
众所周知,车还可以上下移动,同理可以计算。
T3
很有趣的题,但是鱼越大,鱼越小。
先离散化。
样例其实是解题的关键,看懂样例就可以获得 50pts
注意到是 Bob 每次选择 Alice 的左手或者右手,显然应该随机地选择一侧,不然,Alice 将所有手上的数调换左右手一定会使得 Bob 胜率变低。
考虑样例 1 2 3 4,Naive 地思考,如果 Alice 选择了 1 2,那么我有 12 的概率抽到 1,然后胜利;12 的概率抽到 2,12 地猜一下 1/3,这样胜率就是 34;2 3 的胜率是 12;3 4 的胜率是 34
那么,此时作为 Alice,我定然会一直选择 2 3,这样的话 Bob 的胜率就会只有 12,而不是答案 23
那么 Bob 肯定不乐意,为了平衡,他会调整面临一个 2 的时候猜 1 的概率和猜 3 的概率。
- 感性理解:由于抽到 1 的时候必胜,
1 2的胜率很高,所以考虑给2 3匀一点胜率。 - ”理性“理解:由于 Alice 可以采取任意的策略,所以考虑极限情况,即一直选择
2 3,需要让这样的情况下的胜率也很高。
(怎么感觉写了点废话)
判定是等于肯定需要存在相同的数,且 ≥2 个相同的数字可以视作 2 个,因为在 Alice 看来都是一样的策略。
设 ai,bi,ci 表示面临 i 的时候,猜 <,=,> 的概率,设 tt[i]=[i 不止一个]。
二分答案 p。
首先 a1=0,b1=ti2p,c1=1−b1,其中 b1 的 12 是因为当 Alice 选择 1 1 的时候,Bob 有两种抽到 1 的方式。
注意实际上上面三个数都要 /2,因为上面是在分配
然后需要保证的是,∀i,ci+ai+1≥p,也就是极限情况下,Alice 一直选择 i i + 1 的时候胜率要足够。
那么 a2=max(0,p−c1)
也就每次:
- a←max{0,a+p−1+ti−12p}
- a+ti2p≤1
那么现在获得了一个 O(nlogV) 的算法,考虑如何把这个二分给优化掉。
观察 a←max{0,a+p−1+ti−12p},取 max 的意义是尽量让限制变紧张,然后使得在最紧张的情况下也需要满足条件;操作是关于 p 的一次函数,限制也是关于 p 的一次函数。
称取 0 是操作 1,取 a+p−1+ti−12p 是操作 2,操作序列一定形如 222221222212222...
那么,枚举所有极长连续 2 段 [l,r],l≥2,r<n,由 al−1=0 计算出 ar+1(由于操作和限制都是一次函数,这样我们获得了可以枚举 l,r 来获得限制的权利,如果操作不是这样的格式,比如不满足结合律之类,就不好做了),令 si=si+1+ti,此时
上式出现的玩意都是正数,不用担心不等号的改变。
那么很自然想到, p=minl,rh(l,r),解释:
- 理解1:枚举所有 2 段,由于最紧的上界一定是在 真实的 2 段的某个连续段的子区间 取到,所以这样一定可以找到。
- 理解2(Charlie):发现之所以会做 1,是因为 2 操作太松了,二者实际上是一个松紧交替的状态。我只要枚举了所有的松紧交替的情况就好了。
将 h(l,r) 写成 y(r)−y(l)x(r)−x(l),即给 n 个点,求两点斜率最小值,维护一个下凸包就好。
O(n)
小剧场:
wyb:它维护了 yx,由于队头和下一个的斜率比 i 和队头的斜率小(在纸上反复画画),弹出队头让 yx 变小,那么答案 xy 变大了!
czl:嗯??好像很多,这是为什么呢?
。。。。(手造数据探究真相,做出若干猜想等)
czl:等下,这样一条线,这样一条线,它的斜率比它的斜率大!
wyb:woc,鱼越大,鱼越小!
(狂笑)
。。。。
wyb:(笑得抖一抖地说话)草,不对啊,再分析一边,xxxxx,所以答案还是变大!
czl:草!鱼越大,鱼越小!
8.4 自习
感觉今天上午没做啥事情,把昨天 T3 的题解补了,然后就一直在思考 發 怎么做怎么做但是一直不会,弄得心态都不是很好。
后面坚持努力推导,并写代码验证,但是还是失败了,可惜。
下午找到了问题所在,补充了 DAY1 的内容和原题的题解。
晚上想了一晚上的 [atcoder-pakencamp_2022_day2_h] Habatu,帮巨佬调了调 [GYM101754A] Letters Swap。
然后开写 Habatu,写不完,感觉细节非常多!
这一天看下来,感觉虽然效率很低,但是还算充实。
8.5 模拟赛 4
8:30 T1 fxxk
9:15 集合 HASH???
9:40 别急!
10:40 finally pass
感觉 T1 这道题没啥价值。
T1 推了很久的性质,其中最有可能的一个方向是对于每一个 i,求出以 i 作为区间左端点的最近的合法的右端点,然后跑一个 DP 啥的。
然后开始针对这个想法进行优化,并猜测了一坨性质,但是都是假的/fn
后面想到能不能上点随机化,集合 HASH 之类。
最开始想的是矩阵,写完才发现正是因为矩阵不满足交换律,所以不可以!
然后想了想 异或 之类,但是都不好,最后决定感觉使用乘法吧。
写写写,发现单模数被卡了,写了一个双 HASH。发现双 HASH TLE 了,手写了一个 HashTable。
T2,感觉不合法的方案比较少,所以计算不合法的方案。
分析一下条件,感觉对逆排列比较好做。
然后分析出了一个假结论,剩下的不会做了/qd,摆烂了
看完题解,发现这题没啥营养。
由于不合法的方案数确实很少,所以可以暴力 fi,S 表示前 i 个填了集合 S 的数字 方案数。
下午在继续写 Habatu
8.6 晚自习
写 Habatu,有啥好说的!
发现自己的代码破绽太大,所以去学习了一下 jiangly 的实现,非常优美!!
8.7 自习
由于前几天留了点欠帐(写了一半/看懂了没写),所以先搞欠帐。
[atcoder-pakencamp_2022_day2_h] Habatu
很巧妙的题目。
首先,从 b 最小的开始考虑,那么发现每次都可以把数量少的那一半丢掉。称这个操作叫做“切分”
但是这样复杂度显然是没有保证的,因为最小值的位置是随意的。
但是这提示我们如果每次都可以把区间长度砍半就好了。
进一步的,对于当前的区间 [l,r],如果能够找到一个 [u,d]:
- [u,d]∈[l,r]
- max{bu−1,bv}<minv−1i=ubv
- ∑di=uai≥12∑ri=lai
- 求 min∑
那么显然,[u,d] 会成为一个“无敌”的区间,那么 [u,d] 的答案就是 [l,r] 的答案,且,如果这个时候对 [u,d] 进行一次切分操作,那么一定可以使得 ∑a 减半,这样一共只会有 O(lognV) 个区间需要处理。
如何找呢?如果直接找是难崩的,需要注意到,这个区间是通过不断切分得到的,也就是说,他实际上是对 [l,r] 不断切分的一个中间过程,我们现在其实是在加速切分,把一些切分合起来做。
考虑对 u,d 同时二分,怎么二分可以看 OI TRICKS。
需要保证两个区间 [lu,ru],[ld,rd] 无交,分析一下,可以知道如果令 pos 表示第一个 ∑pi=1osai≥all2 的位置,那么初始 ru = pos, ld = pos + 1 就好。
牢记执行的是一个加速切分的过程,经过分析:
记 bu=minposi=midub,bv=minmidvi=pos+1b
如果 ∑midd−1i=miduai>12all,如果 bu<bd,那么 u 只能在 [midu+1,ru],否则 d 只能在 [ld,midd]。
另一侧略。
这样二分出来的 [u,d],满足是无敌的,但是并不能直接递归 solve(u, d),还应当把 以 u 为右端点的后缀使得 minb > min[u,d] 加进去; d 前缀。以保证合法性。
细节很多,总复杂度 (qlognVlogn)
一个有趣的代码细节:
由于 b[i] 表示的是 [i,i+1] 的仇恨值,在线段树上维护的时候,为了使得 [l,r] 维护的是 b[l…r−1],所以不把 b 放在叶子节点,而是在
pushup的时候,mn[rt] = min(mn[ls], mn[rs], mid),即把 b 放在 mid 上。
神秘排列
状态数很少,暴力 DP。
需要翻转二进制位啥的,不太会写,卡卡常过去了。了解到有分治写法,但是不想了解。
[GYM101754A] Letters Swap ( Yandex Algorithm 2018 Round 2 A )
经典 Trick,算作集合 HASH。
发现如果构造一个矩阵,满足 A×A=I,那么搞三个这样的矩阵对应 a,b,c ,一个序列合法当且仅当所有矩阵乘积为 I。
需要统计的是有多少个二元组 (i,j),使得 swap(s[i],s[j]) 之后序列合法,看起来不太好做,因为很难说对于 i 预处理个啥东西出来。
不太能预处理的原因在于会导致 i,j 的信息重叠,只要使得他们的信息不重合就好,那么我们可以分治。(类二维偏序)
这样就很好做了,对于一个 l, r, mid,需要计算 i∈[l,mid],j∈[mid+1,r],可以把左边插入 HashTable,然后查询右侧的矩阵逆的出现次数。
手写 HashTable 可以让复杂度为 O(nlogn)
CF1815F OH NO1 (-2-3-4)
挺神的构造题。
首先考虑这样一个问题:
给定 n 个点 m 条边无向图,每个点有初始权值 wi。需要给每条边定向,记 di 表示 i 的总入度,构造方案使得所有 wi+di 不同
对于这个问题,一个简单的解法是每次找到 w+d 最小的 i,然后把所有它的没有定向的边 (i,x) 都让 ++d[x]
考虑如何将原问题转化为上述问题,对于一个三元环,本质不同的定向方案只有 2 种,分别对应权值 3 4 5, 4 4 4,所以,只需要初始的时候给 w[a],w[b],w[c]+3,然后跑上述算法并定向,然后构造方案就好。
CF1616F Tricolor Triangles
诈骗题。
容易知道合法当前仅当所有三元环权值都满足 mod3=0
那么这是 O(m√m) 个方程,暴力解就好。
CF1801E Gasoline prices
很类似之前的一道模拟赛字符串题,大概题意是每次钦定一个区间是回文串,然后问填写字符的方案数之类。
很类似 萌萌哒,所以有类似 萌萌哒 的”分治“并查集做法,我没有看。
很容易想到只会合并 n−1 次,只需要每次都找出来需要合并的位置就可以了。
如果在序列上,那么就是 HASH + 二分,放到树上,那么树剖一下,然后 HASH + 二分。
CF1801F Another n-dimensional chocolate bar
在做上一道题的时候突然想起来这场 CF 我当时 口胡过,而且当时不太会做 F,所以现在来补。
看到形如选择若干个数使得乘积 ≥x,请动一动 DNA
首先可以随便搞一个 DP,fi,j 前 i 个数字 ∏b=j,答案在 f[n][≥k] 取。
发现这个转移和 喇嘛哑巴trick 的描述一模一样!
改设 fi,j 表示前 i 个数字,⌈k∏⌉=j,即至少还需要乘上 j 才可以满足条件的最大 ∏⌊ab⌋ 值。
这样状态数是 O(n√k),但是转移真的是 √k 的吗?
当然不是,正如 k 只有 √k 个状态,容易发现一个 j 只会转移到 √j 个位置。
那么总复杂度应该是 O(n∑√kj√j) 这种。
伟大的 czl 告知我们,在 O 的意义下,∑ 和 ∫ 等价(利用夹逼定理之类),所以 O(∑ni√i)=O(n32)
那么这里,复杂度就是 O(nk0.75)
[国家集训队] Tree 2
LCT 板子,不小心把 t[ff].ch[getid(f)] = x 写成了 t[f].ch[getid(f)],有点离谱
帮 wyx 调了一点。
CF1740H MEX Tree Manipulation
典。
找一个 DS 维护重链,找一个 DS 维护轻儿子。
特别注意到,如果只考虑点 u 的轻儿子,那么可以用一个二元组 (x,y) 表示 u 的 mex,即假如 重儿子 为 x,那么 u 的 mex = y, 否则 mex = x。
这个二元组是可以合并的,所以可以找线段树维护重链,节点维护 (x,y,z,sy,sz) 表示如果输入的不是 x,那么头部的 mex=y,链上 ∑mex=sy ;另一侧同理。
8.8 自习
发现 linux 看不了 mp4,太怪了。
突然想起来一个严肃的问题,7 月份的总结什么时候补呢...
学习了一下 linux 对拍,感觉好奇怪,不如 windows。
发现 Dynamic Reachability 是原,复习了一下,这种 对询问分块 还是挺有意思的。
[HDU7301]King's Ruins
发现,可以花费 O(kn2/w) 的时间处理出每一个位置可以转移到/被转移到的位置。
具体的:
- 处理可以被那些位置转移:开 k×n(值域) 个 bitset,然后做一个前缀或。
- 处理可以转移到的位置:初始 reach[i]=(1<<n)−1。枚举维度,按照此维度权值从大到小排序,遍历,每次
reach[i] &= tmp, tmp.set(i)。
当然,仅仅得到这些肯定是没有做完的。
一个 naive 的想法:
处理出所有可以被转移到的位置之后,只保留可以被转移的最大的位置。
这样显然是假的,一个修复的尝试是考虑类似 [CCO2020] Shopping Plans,让一个点的后继转移(儿子)连边,即把这个转移树三度化(?)
但是发现三度化不了,因为不同于那道题目,这里在三度化的时候需要显式建边,那么实际上三度化和没三度化是一样的,没有本质差别。
注意到一个关键性质,即每次只关心 可以被哪些位置转移 的 dp 最大值,所以有一个分治做法:
对于
solve(l, r),先计算完 [l,mid],然后把 [l,mid] 按 dp 值排序(重标号),然后计算出 ∀i∈[mid+1,r] 可以被 [l,mid] 中哪些位置转移,执行 Findfirst() 就好。复杂度:T(n)=O(n2w)+2T(n2)=O(n2/w)
但是这个做法的问题在于,由于需要保证分治到 l,r 的时候,bitset 的复杂度是 O((r−l)2/w),所以 bitset 大小只能开到 O(r−l),但是 bitset 的大小必须是一个常数
一个别扭的解决方案是 solve(0, 2^n - 1),以保证每次使用的 bitset 的大小一定是 2 的幂次。
一个思考是对于 bitset<N> B(m), 发现 m 可以不是常数。但是问题在于不仅值域是变量,区间长度也是变量!
所以分治做法可以认为是 G 了。
有如下分块做法:
设块长 B
对于同一块内部点,采用 O(B2) 的暴力 DP
计算完一块之后,O(Bn/w+n) 处理出当前块内每一个点可以转移到的位置集合(遍历 1...n),然后类似 bitset 优化 bfs,O(n+Bn/w) 做完所有转移。
总复杂度 O(k(nB+n2/B+n2/w)),取 B=√n 就好。
Gym103687D The Profiteer
三倍经验:海亮 NOI 集训 传统 && 7068. 商店价格管理问题
复习了一下,发现我当时的写法居然假了!
修了修,问题出在整体二分的时候,初始应该 solve(1, n, 1, n + 1) 而不是 solve(1, n, 1, n),这样会导致答案不正确。
CF1767F Two Subtrees
好题!
子树 = dsu on tree 操作序列某一前缀,剩下一个二维莫队。
需要维护出现次数最大的最小数字,应使用 O(1) 修改,O√(n) 查询的根号平衡。
具体的,对值域分块,每一个块开一个桶维护块内出现 i 次的值有多少个,即 cnt[s][i] = \sum_{j\in s} occ[j] == i,这样可以同时维护 mx[s] 表示块内 maxocc
每次修改只需要改 occ 和对应块的 cnt,mx;每次询问,先找到 mx,然后找第一个块。
复杂度 O(nlogn√q)
bugs && 细节:由于两颗子树可能有重叠部分,所以给 cnt 分配空间的时候要乘 2.
Gym104337D Darkness II
好题!写了一个晚上没写出来,回家想了一下,在 明天早上 改了改总算是过了。
思路和代码都很小清新,但是需要想清楚了再写。感觉这样的体验还是很爽的。
首先注意到合并只有 O(n) 次,那么一个自然的想法是,每次加入一个矩形,然后找出所有可以合并的矩形,合并出一个新矩形;然后对这个新矩形执行同样的操作,直到无法再扩张。
经典地,只需要保证每次检查两个集合是否可以合并的时候,要么可以合并,一旦不可以合并立刻停止就可以保证复杂度。
首先找到只考虑和 [xl,xr] 有交的矩形。
将前面已经处理好的矩形在 x 轴上的区间拆成 log 个插入线段树。由于这 log 个区间的并就是原区间,所以 和原区间有交 等价于 和这 log 中的某个区间有交。
考虑线段树上维护两个 set, cur[rt] 存储所有插入的时候 xl <= l && l <= xr 的区间;sub[rt] 存储不满足 cur 的条件的区间,即在经过的线段树上的所有节点都 insert。
实际上,cur 维护了所有包含 [l,r] 的矩形,sub 维护了所有被 [l,r] 包含的。
新加入一个区间,设拆到线段树上节点 u1,u2,…,ux,途径线段树节点 v1,v2,…vy( v 包含 u),发现所求就是所有 sub[u] 和 cur[v]
容易证明这样一定可以检查到所有有交的区间,只需要证明对于每一个 u,都检查到了它的所有有交区间就好
和 u 有交,对于包含 u 的部分,已经被 cur[v] 检查完了;对于被 u 包含的部分,sub[u] 一定可以检查完;对于剩下的部分,由于 u 是线段树上的一个节点,所以一定会还是 sub[u] 的一部分。
考虑现在获得了一个 set,维护了 (yl,yr) 的二元组。
注意到这些二元组一定两两无交,不然就提前合并了。那么每次只需要二分出需要合并的区间即可。
考虑去掉 set 的 log。聪明一点,如果预先对所有矩形按照 yl 排序,然后按顺序插入,那么用 vector 代替 set,vector 里面的 [yl,yr] 区间一定不交而且有序。
每次只需要取出 vec.back() 进行检查即可,back() 不行就可以 break 了。
实际上不需要保证新矩形的 yl 始终比在 vector 里面的大(当前矩形已经经历的多次合并),只要按照 yl 排序插入就已经能够保证“不行就break”,因为合并只会变大,只会把这个条件变得更厉害。
总复杂度 O(nlogn)
8.9 ACM 欢乐赛
早上过来把昨天晚上 Gym104337D Darkness II 搞了。
下午给 zqm 讲了 Darkness II,补了补昨天总结,然后订正订正。
顺序:H→A→B→卡 C→看 FG→继续卡 C→放 C 猜 G结论→F→看D 并放弃→看E并被卡精度→回来卡 C!
- A Static Query on Tree:建虚树,剩下乱做。
- B ShuanQ:简单数学题
- F Two Permutations:分析分析,首先视作二维平面上行走的问题,思考思考,发现存在合法转移的点只有 O(n) 个,可以直接 map 辅助暴力 DP.
- G Link is as bear:被卡了一会儿。区间操作,还是在差分数组上进行分析,发现每次会把一段区间赋 0,两个端点异或上某一个权值。发现这个权值的组成和下表的奇偶性有关,感觉了一下,可以执行的操作挺多的。但是还是不太会做,猜测既然这个操作这么强,那么答案一定可以取到最大值,试了一下发现居然过了
- H Link with Running:第一眼的想法是 dijkstra,过程中维护健康值最大的一条边,然后从 n 贪心跳。但是这个贪心显然很假,很容易被骗。那么就需要把最短路图建出来,在 DAG 上跑 dp。存在环,由题目限制必然是 0 环,加一个 tarjan 就好。
C Alice and Bob
做了很久但是还是 WA!
首先发现如果 ∃a[i]>=2i 那么 win 麻了,然后发现如果 a[1]=1,a[2]>=2,这个时候也可以 win。
也就是说前面的数字可以给后面的数字挡刀,可以挡多少刀呢?认为只要 a[i]>0,那么就可以挡刀。
记 cnt[i] 表示 1…i,a[i]≠0 的个数,所以条件就是 ∃a[i]≥2i−cnt[i−1]。
但是这样是假的!因为很多情况下一个 a[i] 是无法挡刀的,比如在某一个没有人可以挡刀的时刻,后续用于挡刀的某一个 i 并不可以保留下来。
solution:
感觉还是比较巧妙。
结论:将一个数字 x 看作是 2n−x,A win 当且仅当 ∑≥2n
此时的操作相当于乘 2 并想要得到 2n。
如果满足条件,那么 A 一定可以分出两个集合,使得两个集合都 ≥2n−1。
如果不满足条件,那么 B 每次删掉大集合。
E Bowcraft
被卡精度了,破题!
设 fi 表示 i→i+1 的期望步数,设 gi=∑ij=0fi,答案是 gn−1
考虑如何计算 fi,对于一本书 (a,b),如果吃掉:
如果不吃,那么会随机抽一本新的,发现这个就是 fi, 所以
看到 min,套路地考虑二分,每次二分一个 fi,比较一下实际上计算出的 fi 的大小。这是一个 O(TNABC) 的做法,其中 C 表示二分次数。
由于 h(i,a,b)=α+(1−α)(fi+1)+(1−α)βgi−1,如果固定 a,那么 h 随着 b 变大而变大,所以计算的时候可以只枚举 a,然后二分出第一个取 f+1 的 b,复杂度 O(TNAlogBC)
这样复杂度是对了,但是问题是精度不够!
由于需要执行 n=1000 次这样的二分,虽然说每次是独立求解 fi,但是中间的计算过程 和 最后的加和还是无可避免的导致了精度的错误。
卡了卡发现实在卡不动,赛后发现精度已经做到了小数点后 2 位,但是要求 3 位!
如果不二分,转而使用迭代的方法,实践发现,这将是时间和精度的同时损失。
solution:
设答案是 dp[n]
转移形如 dp[i]=∑abmin{dp[i−1]+1,val(i,a,b)}
考虑类似 20230803 T3 地,对所有取 min 的方式进行一个枚举。
发现 val(i,a,b) 的大小关系取决于 a,b 而和 i 无关,所以可以把 (a,b) 排序,对于 min,那么每次取 val(i,a,b) 的一定是某一个非空前缀。
枚举前缀计算,dp 为其中的 min。(因为一旦取到并非实际转移的前缀,那么一定不优)
这样就不用二分了,精度好了很多,复杂度 O(TNAB)
D Dusk Moon
结论:坐标随机,则任意一个集合的凸包上期望只有 O(log) 个点。
那么线段树暴力维护凸包,每次 pushup 暴力合并。
每次询问问 log 个点的最小圆覆盖,这个是 O(log) 的。
upd:破题破题!计算几何滚出 OI!
8.10 伪模拟赛 1
上午打了一个假模拟赛:
8:05 开始
8:07 T1 一眼签到题
8:28 明白 T2 和 ABC211 Count Multiset 差异巨大,难以转化
8:40 T2 一个看起来正确的解法
9:00 T3 没有头绪
9:30 感觉 T4 不太可做
10:00 写完 T12 回到 T3
10:30 初步推完 T3 条件
11:00 T3 算重!!
大概 11:10 结束。
T2 计算复杂度的时候,一直在算错,经常认为 数的和级别是 O(n2) 而不是 O(n3),经常认为会转移 ji 次而不是 min{m,ji},担惊受怕并浪费了一定时间。
被 T3 骗傻了。看到这种计数的题目,第一反应就是分析合法/不合法条件,然后根据分析出来的条件做 DP,做容斥之类;但是这道题提示我们不要忘记暴力枚举所有可能的情况暴力判定。。。
感觉 T4 有一定可做性,经由类似「AGC043C」Giant Graph 的分析,可以尝试转化成博弈论之类。分析分析发现始终没能用上题目给的性质,放弃了。
订正完之后来看,感觉这套题如果给他们考,他们大概可以 AK 吧。
这种一步天堑的感觉真是令人烦躁,还需要继续沉淀。
[ARC104D] Multiset Mean
伪模拟赛 T2
最开始以为可以套用 ABC211 Count Multiset ,但是不可以。
看到平均数,首先联想到一个经典套路
二分平局数。一个序列平均值 >=mid,等价于序列中所有数减去 mid 后,序列的和 ≥0
那么,计算平均数 =x 的答案,先把 [1,n] 都减去 x,那么需要选出来总和 =0。
那么,设 fi,j 表示考虑了值域 [1,i],选出数字总和为 j。
容易发现正负可以一样做,所以答案就是 ∑jfx−1,jfn−x,j
f 是一个多重背包,使用单调队列(当然这里由于是直接加和所以其实是前缀和)优化多重背包做到 O(n4)
CF833C Ever-Hungry Krakozyabra
伪模拟赛 T3
考虑如何判断合法。
发现合法不好判定,但是好像不合法好判定一点,所以考虑计算不合法方案数来容斥。
大力分析,设选中的数形成的集合 S,S 是有序的。
设 mn 是 S 可以得到的最小值,mx 是最大值,
- |S|>|R|
- |L|=|R|,S 补上 |R|−|S| 个 0 之后,
mn > R || mx < L - |L|<|R|
- (i)|S|=|R|,mn>R
- (ii) |S|=|L|,mn>R && mx<L
- (iii) |S|<|L|,|L|+1=|R|,mn>R && mx<L
注意上述和 R 比较的时候,应先将 S 补齐。
接下来剩下的事情诸如将 mn>R 和 mx<L 形式化成对应的条件之类,这里省略
但是上述方法的缺陷在于很容易计算重复,容斥是复杂麻烦的。
solution:
发现上面的算法其实很 nb,因为它看起来居然是 O(log)
另一方面,它也很扇贝,因为题目并不需要这样的复杂度。
利用插板法,发现 S 只有 (279) 种,所以可以枚举然后暴力判定合法。判定合法可以老实简单地爆搜,一旦搜到上下界都不顶就 win 了,由于只有当顶住上/下界的时候才会往下搜,所判定合法的复杂度是 O(log)
吐槽:
发现合法不好判定,但是好像不合法好判定一点
这句话的意思是判定合法的条件是难以形式化并方便计数的,他隐含的逻辑是只能暴力枚举判定,所以复杂度高。
但是这样的思维用久了,便不假思索地认为复杂度高了。
但是如果是真模拟赛肯定还是不一样,真模拟赛肯定会写暴力的,可能暴力一写就明白了。
[SEERC2018] Inversion
伪模拟赛 T4
思考了一下逆序对的性质,诸如置换环之类,不太行。
然后联想到两道题:
- 「AGC043C」Giant Graph:发现独立支配集和博弈论必胜必败的定义一样
- CF1620F Bipartite Array:发现题目连边方式和这道题一样。
第一道题提示我们考虑博弈论,但是不可以。
第二道题提示我们考虑上升子序列,因为类似二分图的单侧集合,独立支配集集合内部没有边,所以一定选的是一个上升子序列。
可惜的是,由于被博弈论误导了,执着于 2x 形式的贡献,GG 了。
solution:
考虑一个上升子序列,它是独立的,但是什么时候支配呢。
考察里面相邻两个数字 p[l]=u,p[r]=v,他们支配了 (l,r) 中 p[x]≤u 和 p[x]≥v 的点。
自然考虑如果存在 i∈(l,r),p[i]∈(u,v),由于是上升子序列,所以这个序列的所有点都和 i 没有边,所以 i 也应该是支配集的一部分。
所以,一个集合是独立支配集,等价于它是极长上升子序列。
那么还原排列 DP 即可
[Gym102759L]Steel Slicing 2
非常巧妙的转化。
注意到一个矩形所有 hi,li 相同,且如果只考虑 h,那么切的刀数就是 hi!=hi+1 的数量。
把这样的位置对应的形状叫做凹点,那么答案的上界就是凹点个数。
先只考虑横着砍。
现在考虑能不能一刀砍掉两个凹点,条件是:i+1<j,hi=hj,minjk=i=hi,这个可以用单调栈找到所有这样的对
现在还可以竖着砍,发现存在两者冲突的情况。
将所有可以砍的刀视作一个点,有冲突的点连边,肯定会得到一个二分图。
那么,对于这个二分图,需要求的是最大独立集 = 点数 - 最大匹配。由于这道题目的性质,可以贪心求。
那么,答案就是 凹点数量 - 最大独立集
省略一点代码细节。
Hyperregular Bracket Strings
Gym104128L Proposition Composition(20230213 T3 加边) 的儿子题。感觉挺有意思。
发现如果所有区间都不相交,那么爽死了。
如果两个区间相交但是不包含,那么可以拆成三个无交的区间。
但是如果两个区间存在包含关系,那么事情一下子就难崩起来了,多种关系重叠交错,直接 G 大。
用力分析,我们发现一个非常厉害的性质:设 Si 表示 i 被哪些区间覆盖了,对于 Si 相同的下标形成的等价类,每个等价类内部为合法括号序列,且条件充要。
并不需要像 Gym104128L Proposition Composition 一样启发式分裂,因为不是强制在线,只需要使用 集合 HASH 的 trick,每次区间异或即可。
[AGC046E] Permutation Cover
nb 题
记 ax 是最小值,ay 是最大值。
首先,如果 ax×2<ay,那么 G 了,因为必然存在一个 y 被其他的 y 挡住而取不到 x
否则,对于 ax×2≥ay,可以这样构造:
令 S 是所有 at=ax 的集合,放置形如 [K]∖S,S,[K]∖S
即构造两个有重叠的排列,重叠的部分是 S。这样的话,可以让 i∈S,ai−1; i∉S,ai−2,当 |S|=K 的时候显然有解。
让字典序尽量小,使用增量法。
考虑当前已经有了一个 |P|>K 的满足条件的序列 P,模仿上述的构造方式,我们需要重复某一个后缀。
枚举这个重复后缀长度为 len,考虑其对应的 [K]∖S 的放置需要满足的条件。
先把这些数字对应的 a 减 1。依旧记 ax 是当前最小值,ay 是最大值,那么
- ax×2≥ay,那么这 K−|S| 个数字的放置没有限制
- ax×2<ay−1,GG
- ax×2=ay−1,与之前不同的是,现在这 K−|S| 个还不固定,如果把所有 a=ay 都放在 a=ax 的前面,这时就获得了在本次操作结束之后的末尾加上 a=ay 的权利,那么相当于是对 ay−1。所以此时唯一的限制是 ay 放在 ax 前面,贪心放就好
每次取枚举长度得到的增量中字典序最小的一个添在末尾,复杂度 O(K2∑a)
8.11 自习
早上过来看着 zjk 的数学题并不是很想动,于是决定去补 7 月份的总结。
补的时候,发现一些当时没有注意到的问题,也发现自己即使再做原题,也有不会的,掌握程度待考量。
晚上很困,听了一点 SA。
[ABC257Ex] Dice Sum 2
好题!比较对胃口,带一点推柿子,带一点 trick。
假装选择抽 a1,a2,…,ak,考虑计算其期望值
其中, x(i) 表示第 i 个色子扔出的值的随机变量
式子套了一个 E,将其按照定义展开
又记 x(i)=16∑jai,j,y(i)=16∑j(ai,j)2−x(i)2−ci,那么
现在的问题变成了:
给定 n 个向量 (x(i),y(i)),从中选出 k 个,这些向量加起来得到 (X,Y),求 X2+Y 最大值
首先,有用的 (X,Y) 定然构成一个上凸包。
发现最阻碍的点在于这个 X2,如果变成 X 的线性组合,那么就好做很多。
具体的,如果答案的形式为 CX+Y,也就是 ∑Cx(i)+y(i),那么只需要拿出 cx+y 的前 k 大就好。
进一步地,对于上凸包上的一个点 (Xi,Yi),(不同与 x(i),y(i)) 发现一定存在一个 C,使得 CXi+Yi 就是 cxi+yi 前 k 大之和。
分析对 C 的要求,需要满足 $CX_i + Y_i > \max_{j > i} CX_j + Y_j, CXi+Yi>maxj<iCXj+Yj
考虑 i−1,i,i+1,化开,发现 −slope(i−1,i)>C>−slope(i,i+1),由于是凸包,所以不必考虑其他的限制
那么其实就对应了 用斜率为 C 的直线且凸包切点为 i 的情况,这样的 C 可能有多个。
这个点卡了我 1h
所以,如果枚举 C,选出 cx+y 的前 k 大,计算 X=∑x(i),Y=∑y(i),可以找遍凸包上对应的所有 Xi,Yi
C 是实数,无法枚举,考虑怎么样的 C 是有意义的。
发现如果两个 C 对应了同一个方案,那么显然没有意义,所以 C 的改变必然需要引起选择的替换。
使得本来选择 x(i),y(i),之后选择 x(j),y(j) 的 C 只有 O(n2) 种,所以现在有了一个 O(n3logn) 的暴力。
此时如果把 x(i),y(i) 看成是 k,b,问题变成求 max(kC+b 前 m 大值和),这当然不可以李超树。
但是这个暴力显然很蠢,因为变化一个 C 对于方案的改变是 O(1) 的,所以可以把所有可能的 C 从小到大排序,顺次枚举并改变方案即可。
初始的方案应当是 x(i) 最小的方案。
复杂度 O(n2logn2)
CF1208F. Bits And Pieces
ai| (aj & ak)=C(ai) & aj & ak+ai
枚举 ai,贪心求取前半部分。
首先枚举 C 的最高位 2x,需要判定的是是否存在 j≠k,j>i,k>i 使得 aj,ak 是 2x 的超集,如果存在就将 2x 加入 ans
假如对于 ans,每次检查是否存在 aj,ak 是 ans+2x 的超集。
需要计算 mx[S] 表示 ai 是 S 的超集的最大 i,并同时维护一个 mx2 表示次大值。执行一个 SOSDP 就好
[2018 集训队互测 Day 1]完美的集合
被卡爆了,一晚上写不对。
对于选中的 k 个集合,我们需要找一个观测点 x
由于条件的形式是 dist(x,y)×vy,所以对于一个集合,合法的 x 构成一个联通块,那么,这 k 个联通块的交也是联通块。
这很点边容斥,所以点边容斥。
需要计算 x 能够观测到的点形成的联通块中完美集合个数,这个是经典联通块 DP。完美集合要求的最大值可以看作是没有观测点,即没有限制然后计算。
计算出来后,根据是点/边,贡献 +/- C(可选集合个数,k)。可选集合个数可以在 DP 过程中设一个 g。
剩下的问题是,模数是 523,如何计算 C(n,m)
仿照扩展 lucas 的思路,如果把 n!,m!,(n−m)! 里面 5 的幂次拆掉,剩下的部分就有逆元了。
⌊n5⌋! 可以递归,问题在于后面的部分。
常规的东西搞不了的就上多项式。
设 fn(x)=∏ni=1[i⊥5](x+i),意图求其 0 次项的值。
注意到 f10k(x)=f5k(x)f5k(x+5k),所以我们考虑分治/二进制拆分一类做法,下面考虑二进制拆分。
设 n=5k,如果不是那么 n!=(n−1)!n 递归到 n−1
发现 f5k(x)=f5(lowbit(k))(x)f5(k−lowbit(k))(x+5×lowbit(k)),所以我们预处理 pow[i]=f5×2i(x)
思考一下 f(x)→f(x+5k),是一个二项式定理展开的形式,由于 5k 包含 5,所以只需要保留前 23 项的值即可。
所以所有的 f 只需要保留前 23 项进行计算,可以暴力卷积。
记 P=523,预处理是 O(lognlog2P)=O(Nlog2P) 的,(log P = 23) 计算一次 fn(0) 也是 O(Nlog^2P) 的,求解 ⌊n/5⌋! 要递归 O(N) 层,所以这一部分复杂度是 O(N2log2P)
综上,总时间复杂度为 O(N3+N2M+N3log2P)
8.12 模拟赛 5
同时被爆/qd
今天这场, T1 4h soha 一个假算法,消愁。
上次 pyb 让打那场,我畏畏缩缩不敢搞的 T4,被 div3 乱切了。
二者分别反映出 实力的不足 和 心态的问题,杂念太多,懦夫!
一步一步,一步一步。
T1 构造题
我的思考是,对于排列,那么会构成若干置换环,剩下的问题是可能部分置换环上面没有 0 导致启动不了
由 swap pass 知道随意交换两个置换环上的点,置换环会合并
但是这样不能应用到不是排列的情况,因为在生成初始置换环的时候,方案是多样的。
考虑强行修补,首先随便指认方案得到初始的置换环集合,然后找到可以通过调整匹配方案而直接合并置换环的部分,剩下的就可以上前述算法了。
需要维护一点东西,使用启发式合并啥啥的。
问题在于找可以直接合并的部分的顺序,比如,三个环 ABC,AB,AC,BC 都可以合并,但是 AC 不可以合并。其中只有 C 现在可以启动,如果不小心先花费代价合并 A,那就 G 了。
能不能找到方法使得 AB 先合并?也就是说,先不在意是否合并的两者中某一者必须有 0。
这样思路是对的,但是这意味者需要检查很多对,无论是检查 (环,环),还是直接考虑 ai 相同的位置之间的关系,都有 O(n2) 对,数据水可以通过。
所以 G 大了。
solution:
考虑连有向边 ai→bi。
一定存在欧拉路,对于含 0 的联通块,是若干个环套环之类的形式,但是无所谓,都可以通过 0 换掉。对于不含 0 的,花费 2 的代价,先把某一个 0 借过来,然后还回去。
发现上面实际上优化了我做法中寻找合适置换环的过程。
构造题,没事就连边!!!
T2 图论题
我的思考是,假如 m=n(n−1)2 即最后形成了一个竞赛图
倒着做,首先 nlogn 找出一条哈密顿路,然后把上面已经是强联通的合并起来(缩点后,哈密顿路实际上也可以拓扑排序求出)
每次相当于获得了将某一条边重定向的权利,如果这条边在某一个强联通分量内,那么就不动;否则,改成从哈密顿路后面到前面,然后暴力合并强联通块。
问题在于如何处理 m≠n(n−1)2 的部分。
需要找到初始的时候,强联通块数量的最小值,并把可以被补成强联通的块合并,这样就可以执行上面的贪心了。
solution:
下面有向图的补图,是将这张图视作无向图之后的
结论:当 n≠2 时,若补图连通,则原图一定可以补成一张强连通图。这是因为,考虑补图的一棵生成树,则非树边对应的路径可以覆盖所有树边;每次取一条非树边并将其覆盖的路径连成环即可。
注意只需要找出联通块并合并就好,这条边具体定向的方案是不关心的。
std:只需要对于每一个点,找到其在补图上的某一条边,这样就可以找出联通块了。那么,拿出原图度数最小的点 r,对于和 r 有边相连的部分,已经找到一条边了,不用管;对于和 r 没有边的,暴力枚举。由于 r 度数是最小的,借助类似 三元环 计数的复杂度计算方法,复杂度是 sqrt?
陈子墨:
由于缩点之后哈密顿路实际上也可以拓扑排序求出,仔细分析,实际上,哈密顿路上的点一定可以是按照出度从大到小排序的。
这是因为,假如我已经对排序后前 i 个点构造了哈密顿路,如果有边 i→i+1,那么赢麻了;如果有边 i+1→i,那么我直接认为 i 和 i+1 在同一个强联通块,首先 i+1 如果向上一个强联通块 [x,i] 连边,那么对于 j∈[x,i],不考虑到 [i+2,n] 的边,他们的度数必然比 i 小,考虑 [i+2,n],发现必定是 j∈[x,i+1] 都向他们连边,不然 i+1 和 i 还是会合并,所以度数关系始终不满足条件;如果边 i,i+1 在补图上,那么直接补成 i→i+1
已经拉出一条哈密顿路,观察上面的分析过程总的条件就是,如果存在一条跨过 (i,i+1) 的从右往左的边,那么 i,i+1 就可以合并。
T3 数据结构题
很有意思的数据结构,充分考察选手的数据结构素养
首先考虑 LIS ≤k 的部分分,设 St 表示 fi=t 的点集(点 (i,ai) ),发现 St 一定是单调不增的,且 St 一定在 St−1 的右上方。
每次操作认为是删除一个点然后加入一个点。
对于删除操作,会使得一些 St 降低到 St−1,这样的降落只会发生至多 20 次,且由于 S 点集单调不增的性质,可以使用平衡树找到所有这样的点。
对于加入操作是类似的,由于点集无交,所以 FHQ Treap is fine.
考虑 LIS>k 怎么办,现在的问题出在可能加入一个段之后,上升次数太多。
注意到加入一个点,maxLIS 最多增加 1,所以我们考虑如果当前 maxLIS=k,那么这个点就暂时存放起来不加入;如果某次删除操作使得 maxLIS<k,那么再使用存放在 set 的点,加入到 =k 的时候立即收手。
复杂度 O(nklogn)
AMPPZ2014 The Cave
U 群看到的题,觉得很有意思
给定一棵有 n 个节点的树,相邻两点之间的距离为 1。请找到一个点 x,使其满足所有 m 条限制,其中第 i 条限制为
dist(x,a[i])+dist(x,b[i])<=d[i]。
实际上要求 ∀i,x 到路径 (ai,bi) 的距离 ≤dist(ai,bi)−di2
暴力的想法是考虑线段树打标记之类,考虑了一下发现不会。
solution:
考虑调整法。
首先随便尝试一个节点作为 x,比如 1
此时,对于第 i 条限制,1 至少需要向这条路径走 max(0,dist(1,ai)+dist(1,bi)−di2) 步。
需要走的步数最多的那一条限制,让 1 走对应步数到 x
此时可以发现,如果这个点合法,那么完事儿了;如果这个点不合法,那么说明无解。
说明:x 显然不可以往子树外走;x 不需要往子树内走,因为当前取的是限制最大的。限制分为三类,x 子树内的,经过 x 的,x 子树外的,第一、二种已经解决了,第三种希望 x 尽量往上走,所以 x 不可以往子树内走。
综上 x 不会动。所以充要。
8.14 自习
前半个上午用于订正考试题目,并和 陈子墨 讨论了一下 T2 的另一种实现的原理。
上午后面做 Paimon's Tree 啥的。
下午做 SA,并发现一个重要细节, s[i] - 'a' + 1 的 +1 is very important.
晚上比较仔细地学了一下正牌广义 SAM,虽然没太懂
Paimon's Tree
考虑钦定路径 (u,v),最优秀的方案一定是往其他位置塞垃圾。计算此时的答案,不可以做从 u 开始的 DP,这样相当于是钦点了第一个点就是 u,这显然是错误的。
需要执行的是区间 DP,设 ft,i,j 表示已经染色了 t 个点,(u,v) 路径上第 i 个点到 j 个点已经染色的最大值。
每次转移要么染色 i−1/j+1,要么判定一下能不能塞垃圾。
于是获得了一个枚举叶子,一共 O(n5) 的做法。据说可以卡过去
考虑优化,当前 DP 到 u,v, 发现难点在于需要知道 u,v 的哪些子树可以塞垃圾。
改设 ft,u,v,0/1,0/1 表示 u,v 没有/有被染色,如果没有被染色说明 (x,fx) 还没有分配 a。
对于 ft,u,v,k,可以染色(已经染色/没有染色)的点数(可以塞垃圾)是 n−siz[u]−siz[v]+popcount(k)
钦定每次在边 (fu,u) 上放 a,一定是先 (t,fu,⋆,1)→(t,u,⋆,0)→(t+x,u,⋆,0)+at+x+1⟶(t+x+1,u,⋆,1),这样就实现了把垃圾塞到 subtreefu∖subtreeu
一个疑问是为什么不可以往 subtreeu 里面塞垃圾,这是因为最优答案的端点一定是两个叶子。
复杂度 O(n3)
[CF1508C]Complete the MST
分析一下补图联通块,剩下随便搞搞。
8.15 hzl 字符串
上午听了 AC 自动机,觉得讲得太慢了,效率太低。
晚上 CF 挂了,不想写题,补了补 7 月总结。
[CF1525F]Goblins And Gnomes
复习了二分图有关定理知识。
8.16 hzl 字符串
对 SAM 比较熟悉,上午选择性听了一点。
搞明白了 后缀树 对于 SA 和 SAM 的中介作用以及辅助思考的作用
SAM 写吐了,感觉晚上脑子不是很清醒。
摆烂了。
[AGC046D] Secret Passage
小清新题目,但是很妙,本来以为看懂了,写题解的时候才发现没完全懂。
然后想了好久为什么可以直接 +fi,j,k 而不用考虑到达这个状态的方案数,然后想起来题意就是算这个,本来就不关心前面的方案数。
之后仍然在理解 DP,但是理解不了!
最后找到了另外一篇博客的解释,觉得很正确。
把这个操作转化一下:
- 从 set 中取出若干个数字放在当前序列的头部
- 将当前序列前两个中某一个插入 set,另外一个删掉
再精简一下:
- 从 set 中拿出两个数字放前面,此时操作等价于从 set 里面选一个数字删掉
- 从 set 中拿出一个数字,此时操作等价与替换掉 set 中某一个
- 向 set 中插入一个
由于 set 里面只会有 0/1,所以可以用二元组 (c0,c1) 表示
尝试设 fi,j,k 表示处理到后缀 [i,n],set 中有 j 个 0, k 个 1 的方案数
但是问题是怎么计算答案,怎么避免算重。不会,哈哈。
solution:
在上述的 DP 过程中计算答案是困难的,可以先 O(n3) 把所有合法状态搞出来,设 gi,j,k=0/1。
然后啊啊啊啊啊啊啊想破头都不明白怎么计算答案的方案数的。
inc(f[i][j][k], f[i + 1][j][k]);
if(j && s[i] == '1') inc(f[i][j][k], f[i][j - 1][k]);
if(k && s[i] == '0') inc(f[i][j][k], f[i][j][k - 1]);
if(g[i][j][k]) inc(ans, f[i][j][k]);
显然不同的三元组能够得到的串是不同的,而一组三元组可以得到的串的个数可以 DP 求解,具体来说,倒着 DP,同时为了防止算重,我们强制要求 1 的后面只能添加 0,0 的后面只能添加 1,这样转移是 O(1) 的。
—— tzc_wk
稍微观察一下就能发现,任一时刻,我们剩下的东西必然是一段定死了的后缀,加上一些可以任意塞位置的 0 与 1。考虑任意一个由上述时刻生成的串,就会发现它与该后缀的最长公共子序列长度即为后缀长度,且还剩余一些 0与 1。
于是考虑模拟最长公共子序列的过程。设 fi,j,k 表示长度为 n−i+1 的后缀,所有与其 LCS 就是该后缀本身,且多余 j 个 0、k 个 1 的串数。
问题是会不会存在某一个被生成的串,使得存在多个后缀和他的 LCS 都是那个后缀。
这样的情况会不会已经被 j 和 k 限定了呢,似乎限定不了。
但是如果仔细观察上面的转移,就会发现我们不会在 s[i] 前面放数字,所以一个生成的串,只会在最长的满足条件的后缀的位置被计算到。
这样就不会算重。
8.17 可乐赛+伪模拟赛 2
早上多睡了 30min,今天上午反而很困
开场 F,发现是神必最短路,分析分析分析到 8:40 总算是会了,9:20 左右过了
然后脑子就有点晕乎乎了,看了一眼榜去做 A,一眼秒了,但是死活写不对,有如下 bug:
- 没有计数好数字不能有前导 0 的情况
- 使用 s[i] 作为数位 DP 上界,实际上应该是
s[i] - '0' - dp 初值写
f[]=1,实际上由于是 AC 自动机,有重复,应该inc(f[], 1)
赶紧看 H,感觉脑子太蚌,第一眼看过去啥想法都没有,洗了把脸回来发现是 sb 题。
看到 wyx 切了 E,去写 E。
分析了一下发现是 set 优化 bfs / 线段树优化建图 sb 题,然后开始写。
随着代码的展开,题目给出的 x,y 不断将我绕晕,于是我光荣的记错了题目(本来是看对了的),认为如果一个人无路可走,这个时候也是 Happy End
然后发现自己的代码瞬间变成了 rubbish,然后啥都不会了。
又想了 20min, 趴了 5min,决定去看其他的题目。发现剩下的题目思路都很简明,除了 G 看起来是个奇怪的贪心,但是都不想打了。
回到 E,发现题目读错啦。交上去 20pts,傻眼了。最后的时间一直盯 E,打了个暴力随便造了点数据好像都是对的。
赛后发现原来是 E 的中文翻译错了,虾头。
下午比较迅速地订正了并学习了一下 PAM,晚上打伪模拟赛。
对于自己的实力又有了一定信心。
一眼把 T1 秒了,线段树萌萌题,没啥好说的。
感觉 T2 方案数挺多的,先对着矩阵分析了一下,发现有点困难;然后对着生成的序列分析,思考如果随便指定一个 a1,a2,…an,此时 an+1,…an+m+1 需要满足什么条件。
记 mx=maxa1…an, 对于 an+1 而言,感觉只要 ≤mx 就可以调整调整。一共有 m 个限制,记 mx2=maxan+1…an+m+1,发现 mx2≤mx
知道实际上 mx2 应该等于 mx,猜测结论是只要 mx2=mx,那么一定存在一个矩阵可以生成这个序列。
有题解,偷懒偷偷看一眼验证一下,虽然结论确实是正确的,但是不小心把后面的拉格朗日插值结论看到了,下次一定。
也许后面的插值结论自己做也能做出来:
答案柿子是 ∑ki=1in+m+(i−1)n+m−(i−1)nim−(i−1)min
记 Sk(n)=∑ni=1ik,这时自然数幂和的定义式。
只关注 ∑(i−1)nim 咋办,二项式定理一下:∑(nj)(−1)n−jSj+m(k)
由扰动法,知道 Sk(n) 是关于 n 的 k+1 次多项式,前面加系数都无所谓,所以上式是关于 k 的 n+m+1 次多项式,插值即可。
T3 一眼秒了,但是出现了很多意料之外的细节问题,30min 啪啪啪敲完,调了 100min /ll,犯了如下错误:
- 对于边上颜色 ≥3 的处理,此时应该为必定有贡献,合适的处理方式是赋值为一种没有出现过的颜色,不合适的是打标记。
- 对于边上颜色只有一种时,次大值的值应该为 -inf
- 对于询问的某一个端点恰好在分治中心的情况
- 将 query 放到某一个
vec[v],找到 v 对应的 rt 之后,应当 swap(vec[v],vec[rt]) - 维护最大值和次大值的时候,一定要保证二者选取的颜色不同。由于更新的时候可能会使用同一颜色更新多次,所以不要将最大值次大值选为同一个颜色。
T4 树
upd 8.19 终于写出来了。
- 1h:17 号晚上推 DP 并想到凸函数合并,并想了一点细节
- 30min:18 号上午理了理思路
- 3h:18 号下午写出
错得离谱的version 1 并发现 version 1 错得离谱 - 2h:18 号晚上写出不那么错的 version 2 并发现 version 2 的重大错误。
- 1h:18 号晚上写出比较正确的 version 3 并发现平衡树相关操作出现问题
- 1h:19 号下午成功定位问题
- 20min:19 号晚上修复问题,AC!
这样估下来,前前后后花了 9h 左右的时间才写出来这道题,虽然说中间 3h 左右的时间(写 version1 的时候) 状态不太好,但是其他时间都是比较集中的。
最后删调试行的时候,发现调试相关的东西写了 4kb....
在不断调试,不断解决问题的过程中,看到输出的信息逐渐如臂指使,一步步逼近正确,我好像抓住 OI 之美的一瞥,梦回和 OI 的初遇。
version0:
首先有一个显然错误的贪心,即认为最优情况下 ∀au+av=z(u,v),然后可以顺理成章地发现如果令 a1=x,那么剩下所有点的权值就已经确定了,那么总权值一定是关于 x 的一次函数形式,随便做??
想一想就发现很假。
version1:
贪心不了,考虑 DP。设 fu,i 表示 au=i,子树最大权值和。
fu,i=∑maxz(u,v)−ij=0fv,j
啊啊啊乱搞一通,发现对这个式子没啥办法,最优秀只能做到 O(nz),也并没有发现有其他的可行的 DP 方式。
观察发现叶子节点的 f 是一个正比例函数。
(这样观察的手段还出现在 [APIO2016] 烟火表演、二叉树)
每次可以认为是把 fv 做一个前缀最大值,然后翻转区间 [1,z],然后对应位置合并。
画了画图,感觉合并出来应该是凹函数(实际上应该是凸函数,这里分析错了),这个结论也比较符合上面贪心,即答案在左右两个端点取到。
立马想到了之前一个对顶堆维护凹函数的题目,发现这个方式不太适合,那么直接上平衡树把!
当然选用 FHQ 平衡树,小清新,容易写,没有奇怪的 rotate。
思考一下平衡树节点维护啥东西比较好,直接维护 DP 值肯定是不太合适的,那么要么是维护区间的斜率,即 d[i]=fu[i]−fu[i−1],当然也可以维护斜率的变化量,即维护斜率变化的端点,这样看起来要优美一点。
发现如果维护斜率变化的端点细节可能有点麻烦,无脑一点决定维护斜率,即平衡树上每一个点 [vl,vr,dlt] 代表 d[vl…vr]=dlt。
肯定采用启发式合并。
考虑区间翻转操作怎么办,发现如果对 [vl,vr] 翻转似乎有点麻烦,然后开始发电:
由于我是启发式合并,所以每次允许遍历一遍小的平衡树上的所有点,所以干脆暴力把小的平衡树上面的节点提取出来,然后挨个翻转,这样前缀最大值看起来也非常好做。
这显然是在发电,首先的问题是,如果 rt[u] 的平衡树是小的,那么岂不是意味着需要把 rt[u] 翻转?
假如通过打标记之类的方式处理了这个问题,考虑“重儿子”,多少都得把里面所有点提出来做前缀 max 吧!复杂度一下子就垮了!
重要细节1:启发式合并,大小的判定应该是在于平衡树上节点个数,也就是分段函数的分段点个数,所以平衡树上注意维护节点个数而不是代表的区间长度。
重要细节2:由于平衡树里面只维护了差分数组,想要计算值需要 fu,0。
细节3:(平衡树常识?)在平衡树上查询 前 z 个的前缀和 的时候,定位到节点 u 使得 vl[u]≤z≤vr[u] 时,
ls[u]也应当被计入
细节4:spilt 的时候,应当把包含 x 的节点包含,在判断时有一点考量。
细节5:(正解不需要)将前缀和 ≤0 的部分赋值成 0,注意可能会将平衡树某一个劈成两半,这里还需要一个小心的二分。
细节6:应当把 [lim[u]+1,inf] 部分的 dp 值补全,可以防止一些奇奇怪怪的错误。
代码没有写出任何 bug!完美地实现了我的想法!但是这个想法太假了!
version2:
需要打 rev = z 的标记,对于一个标记, swap(t[x].vl, t[x].vr), t[x].vl = z - t[x].vl + 1, t[x].vr = z - t[x].vr + 1; 看起来不错。
重要细节7:由于需要 dealcorner,需要找到平衡树最左边的节点 lmost,路上一直往左走并 pushdown,所以 swap(ls, rs) 的时刻需要考量。
由于要 reverse,所以应当先 shrink_to_fit(rt[v], z),即只保留平衡树节点 ≤z 的部分。
由于要合并,所以如果只保留 lim[u] 的部分会好很多,这里也来一个 shrink。
于是,现在的流程:
calc(v, z)来计算 f[u][0]shrink_to_fit(rt[v], z)prefixmax(rt[v]), reverse(rt[v], z)shrink_to_fit(rt[v], lim[u])- 启发式合并
细节 8:所有涉及到 merge 的函数都可能改变 rt[v],所以传参的时候应当取引用
经过一通调试,终于发现它居然是 凸函数!!!
version3:
对于凸函数而言,前缀 max 就是把后缀 d 值 ≤0 的部分砍平。
为了节约,循环利用已经写好的 prefixmax,决定先 reverse,然后把前缀 d 值 ≥0 的部分砍平。
突然发现很多操作都好写了很多,现在的流程:
shrink_to_fit(v, z)rev(rt[v], z), prefix(rt[v])f[u][0] += f[v][0] - t[rt[v]].sumshrink_to_fit(v, lim[u]);- 启发式合并
这是一个正确的流程,距离 AC 只剩下如下细节:
重要细节 9:每次 insert 的时候,可能会把边角的 2 个节点拆成 4 个,每次拆完之后应当把到根的一条链都 pushup,因为把拆出来的点合并回去的时候可能直接合并到根节点上,即使不合并到根节点,由于当前节点的值已经改变了,所以无论怎么说都是应该 pushup 到根的。所以平衡树上还需要维护 f,思考发现,只需要在每次 pushup 的时候让子节点认父亲,就可以处理 merge/spilt 操作之后换父亲的问题。
细节 10(平衡树常识?):每次执行区间加法的时候,由于 vl,vr 只代表了一个节点,不能代表一个子树,所以应该是
sum += siz * ad,还需要维护一个 siz。
8.18 自习
上午调昨晚 T3 并写昨天总结。
T4,之前有道类似的凹函数合并的模拟赛题,当时使用的是对顶堆维护啥啥的,好象是因为操作比较简单之类,但是找不到了。
找到的一个比较类似的题目是 [APIO2016] 烟火表演,虽然说这道题当时不会做。
17 号晚上大概想了 1h 左右,想了一点代码细节,但是 18 号起来就忘了。
18 号又想了很久的代码细节,但是中午吃了饭,打完球就忘了。
下午自己又推了推,想了很久的代码细节,决定自己乱写一个试试。
状态略困,慢悠悠地写完了,然后一直调一直调哈哈哈哈哈。
17:20 左右,发现假了。
吃晚饭的时候想了想咋修,发现不太可修,想了想重构。
吃完饭回来准备写的时候感觉自己又忘记了一点细节,但是暂且不管。
晚上继续冲,发现一个致命错误是我应该把 reverse 之后 >=0 的改为 0。
还是没有调完。
8.19 模拟赛 6
9:30 终于搞出来 T1 结论。
10:30 t2 MLE??? 摆烂
10:45 T34 有点怪
11:05 猜一个 T3
11:30 发现看错 T4 值域了,瞬间可做了?!
感觉不管打模拟赛还是做题的时候都应该有信心一点,感觉很多时候不是做不出来,是感觉不可做然后并没有做到用力分析。
T4 最开始一直以为值域是 1e9,所以一直在思考一些其他的算法,比如说经由切比雪夫距离,类似把圆放在圆心,把一个矩形放在矩形的中心,那么走的就是一个折线段之类。
最后的时间才看到值域是 2e5,那么果断考虑扫描线,发现十分可做!但是没有时间了,拼手速打了 20pts 暴力。
T4 订正的时候,把 yl 和 yr 搞反了。。。。当然这都是小问题。
晚上回家,随便玩了玩,玩 xxx 心态被打炸了,于是去调昨天没调完的 T4,本来就已经临门一脚,很快就调出来了/hanx,这道题的总结写在了 8.17 号的位置。
8.20 晚自习
先做了一下 [ARC113F]Social Distance。
然后在看 [2018清华集训] 如何优雅地求和,感觉自己的生成函数素养实在匮乏,看啥都看不懂/fn。问题不大,慢慢来。
[ARC113F]Social Distance
首先有一个假的 min-max 容斥做法:(令 S=1,2,…n)
看起来很愉快啊,因为一个集合里面的 max dis 显然只需要考虑左右两个。
这样的错误在于,我们实际上枚举的是二元组集合 {(i,j)|i∈S,j∈S},所以应该枚举的是 n2 级别个元素的子集,那么这样复杂度就错了。
可以想到这样一个转化,E=∑iP(X=i)=∑P(X≥i),记 f(z) 表示 min≥z 的概率,答案就是 ∫f
考虑对于一个固定的 z 怎么做,常规的 DP 很难避免需要记录 ai=j 的问题来判定 ai+1 可以是啥,但是有如下一个高明的转化:
对于每一个 i,ai 从 [xi−1−(i−1)×z,xi−(i−1)×z] 均匀随机,求使得 a 递增的概率
此时自然想到离散化,得到序列 v1,2,…2n,设 fi,j,k 表示在前 i 段放了 a1,2,…j 使得其递增,第 i 段放了 k 个的概率。
转移,要么考虑放到后面, fi,j,k→fi+1,j,0,要么把 j+1 放到本段。
这首先要求 j 包含这段,其次,均匀随机选 aj 使得取到本段的概率是 段长 / j 值域长,最后,要保证递增,类似树的拓扑序的结论,概率是 1k+1
这样,固定 z,就获得了一个 O(n3) 的做法。
考虑如果 z 不固定咋办,∏值域长 是常数可以提到最后除,发现 v 一定形如 −bz+a 的形式,那么段长也是关于 z 的一次式,n 个一次式子相乘并线性组合啥啥的,得到的是一个关于 z 的 n 次多项式。
所以,f(z) 是一个关于 z 的多项式,如果可以把多项式每一项系数求出来,那么答案就是 ∑ni=0fi(∫zzi),这个是简单积分。
这当然是可以的,只需要略微修改转移,每次需要多项式乘法,算一算是 O(n4)
这样复杂度看起来太厉害了!说明做法是假的。
问题出在,随着 z 的变化,如果 vi 和 vj 的大小关系变化了,那么 段长 对应的单项式的系数之类可能就会改变。
但是注意到 i,j 使得 vi,vj 大小关系变化对于每一个 i,j 只会发生一次,所以不同的序列 v 只会有 O(n2) 个,可以对于每一种都算一遍对应的答案。
复杂度 O(n6)
8.21 自习 + 伪模拟赛 3
晚上打伪模拟赛,感觉状态并不是很好。
T1
开场给 T1 搞了一个 O(nmlogm) 的 DP 上去,打表出来发现对于 j∈(mi,mi−1],dp[⋆][j] 的值是一样的,手动证明了一下发现确实是这样
考场上将复杂度错误的分析成了 O(n√mlogm),又注意到很多转移可以合并起来做,认为卡常可过。
但是,借由 CF1801F Another n-dimensional chocolate bar 的复杂度分析,这个复杂度实际上是 O(nm0.75),压缩后的转移数量打出来在 2e4 左右,未来可以通过。
所以 T1 只有 70pts。
solution:
设 f(S) 表示钦点 S 集合不合法的方案数,其中 S∈[n−1],表示 ai,ai+1 是否合法。
由二项式反演(容斥原理),ans=∑(−1)|S|f(S)
由于是在序列上做,所以钦点不合法的是一段一段的区间,那么对这个序列 DP。
设 dp[i] 表示前 i 位的答案,即 ∑S∈[i−1](−1)|S|f(S),每次增加一个段并乘上对应长度的容斥系数。
发现一个不合法段长度只有 O(logm),那么爽死了,预处理 gi 表示长度为 i 的不合法段方案数。
复杂度 O(nlogm)
这个 DP 其实是对 g 做 exp,那么也可以上多项式全家桶做,但是常数巨大。
T2
给 T2 搞了一个自认为很正确的构造,即搞出一个 dfs 树,然后妄图不使用任何的反祖边,构造出一组解。
发现如果两个点如果不是祖孙关系就可以乱跳,思考什么时候会找错。
关注到 同一深度只有一个点 的点集,称为关键点,认为只需要先把这些点干掉,剩下就可以随便配对。
问题出在,由于为了干掉一个关键点,需要把从 根(1) 到这个点的路径都干掉,所以可能导致一些本来度数为 2 的度数为 1,然后求大。
solution:
题目让求新定义哈密顿路,尝试套用竞赛图哈密顿路。发现可以套用。
T3
首先,一个递增序列对应 n! 个原序列 a
一个差分序列 a′ 唯一对应一个递增序列
一个可重集 i∈[1,m],∑cnti=n,∑icnti≤m,对应 (ncnt1,cnt2,…cntm) 个差分序列。
先给总方案数除一个 n!,那么一种方案的系数只剩下一个可重集排列数。
那么是经典“搭楼梯”DP,只要保证每次新增一段的时候,就可以确认这一段的长度,那么这个 DP 就是好的。
问题是知道了 fi,j 表示 i 个数和为 j 的方案数,如何计算答案。
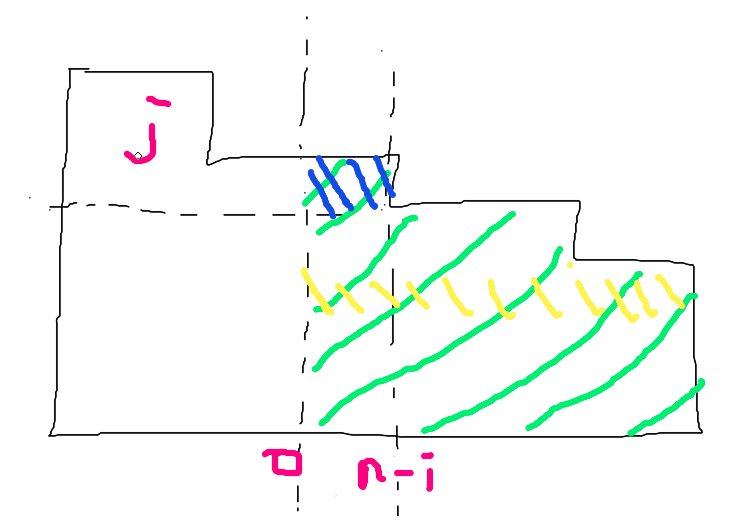
假装现在在计算 Eo,对于 DP 出来的一个阶梯,a′′o 的值是绿色部分,我们计算绿色部分的方法是通过期望线性性,拆成计算蓝色部分的和,即考虑用若干条平行于 x 轴的直线 y=1,2,3,4,… 去切这个阶梯。
对于图中的情况,贡献就是 fi,j×(o−(n−i))×gi,j,其中 gi,j 是为了把矩形拼完,可以倒着做一遍 f。
一个担心是,是否应该给 o−n+i 乘上一个 高度差 的系数,比如对于上图的黄色部分,是否算的不对呢?
观察一下转移就会发现不会,这部分会在 fi,j+ki 这个 k 被计算到。可以这样做是因为并没有新增段,贡献系数是一样的。
T4
原题 keep xor low,题解省略。
清华集训2016 如何优雅地求和
回顾了一下泰勒展开相关,exp 的组合意义,斯特林数一套。
看到组合数+多项式,一定要思考下降幂多项式!这个是在 联合省选A 组合数问题 里面学到的
题解1:将多项式写成牛顿级数的样子,发现牛顿级数的系数可以二项式反演用点值求,然后这个过程是个卷积,剩下随便推推柿子。
题解2:先 多项式点值表示转多项式下降阶乘幂表示
点值的 EGF = 下降幂多项式系数的 OGF × e^x,然后随便随便做。
CF960G Bandit Blues
推柿子部分很简单,学习了多项式全家桶和求第一/二类斯特林数行/列,这里简单写,加深印象
求逆:递归求,假设求出了 modx⌈n2⌉ 的逆 G,真的逆是 H,那么 H−G≡0(modx⌈n2⌉),平方一下,由于 (G−H)j 和 (G−H)i−j 至少有一项 ≤n2,所以 (G−H)∗(G−H)≡0(modxn)。那么 G2−2GH+H2≡0,同乘 F,卷积有分配律,且 FH≡0, H≡2G−FG2,NTT。
积分和求导是简单的。
ln:F(x)=lnG(x),求导 F′=G′G,套一个求逆,结合积分和求导
exp:F(x)=eG(x),取对数 lnF−G=0,换数域到多项式域,设 f(F)=lnF−G,递归做,先求 modxn2 下的 F,套牛顿迭代,在 F0 处进行泰勒展开,分析一下发现只有泰勒展开前两项有值,写出来发现其实就是牛顿迭代的形式。
k 次幂:ln 一下,乘 k,exp 回去。可以通过平移多项式的方法使得其符合 ln 和 exp 的定义。
第一类斯特林数行:对于第 n 行其生成函数就是 x 的 n 次上升幂,可以暴力分治 nlog2n 求。
第一类斯特林数列:单个轮换的生成函数是 F(x)=∑ni=1(i−1)!xii!,做多项式 n 次幂,就是 [in] 的 EGF
第二类斯特林数行:通项公式是卷积的形式,{nm}=1m!∑i(−1)m−i(mi)in
第二类斯特林数列:单个的生成函数是 F(x)=∑∞i=1xii!=ex−1,仍然做 n 次幂,就是 {in} 的 EGF。
注意上面两个求列的时候,最后的答案都要除一个 n!。
比如,对于第二类斯特林数而言,这是因为 Fn(x) 就是 i 个有标号物品放到 n 个有标号盒子里的指数型生成函数,那么除掉 n! 就是 i 个有标号物品放到 n 个无标号盒子里的指数型生成函数。
另外,expF(x)=+∞∑i=0Fi(x)i! 就是 i 个有标号物品放到任意多个无标号盒子里的指数型生成函数(exp 通过每项除以一个 i! 去掉了盒子的标号)。这其实就是贝尔数的生成函数。
TopCoder 13444 CountTables
斯特林数反演:f(n)=∑k{nk}g(k)⇔g(n)=∑k(−1)n−k[nk]f(k)
设 g(m) 表示行互不等价,m 列的方案数:(cm)n_
设 f(m) 表示行列都不等价,m 列的答案:
即枚举分成了 i 个互不等价的集合,然后将 m 列分配进 i 个等价集合。
上反演即可。
8.22 模拟赛 7
上午状态不太好,考试的时候前面半截脑子卡卡的。
时间线忘记了,感觉 4 道题,节奏确实有点快,需要更为高明的做题技巧。
T1 是傻波,T2 考场上想到了正解的一大半,但是没有给区间去重,T3 考场上想到正解的一半,没有想到直接枚举起始边就是对的,T4 考场上暴力没有时间打了,比较可惜。
由于数据比较水,所以这场暴力分算下来有 260 左右,没有拿到,需要反思一下。
看到 result 的时候是及其自闭的,被各路神仙掉起来打,再一次有了前路渺茫的感觉。
后面发现其实很多都是暴力分,而自己距离正解的距离也并不遥远,感觉心态就好了很多。
晚上一直在盯着 T4 看,T4 可以说是集合幂级数大杂烩了,很厉害。
T4 大度一点
条件容易转化为删成若干个边双,单点 O(3n) 的做法是容易的。
solution:
给出的图一定是 一些边双,里面某一些点挂了若干子树 + 森林,称前面部分方案数为 noforest, 后面部分方案数叫做 forest。不管怎么说,得先把 noforest 算出来吧。
forest 是可以算的,是 tree 的集合幂级数 exp(O(n22n)),tree 也是可以算的。
设 e[S]=2cnt[S],其中 cnt 表示 S 的导出子图的边数,那么有 e 就是 noforest 和 forest 的无交并
只要做一个子集逆卷积就可以了,这也是 O(n22n)
剩下最后一步,需要把 nof 里面的 tree 砍掉,设 gi,s 表示 ≥i 的点都在边双内的图的方案数,初始令 gn,s=nofs
需要排除掉 i 有一个子树的情况,需要计算的 tree 使得 i 是根,假装已经会做这个问题。
仍然可以用子集卷积处理.
由于 max A 的约束,会多一个 n 的复杂度,这部分 O(n32n)
总复杂度 O(n32n)
tree 也是可以 O(n22n) 的,由于还有上述的要求,是每次新加入一个点 i 并给 i 选一点子树
for(int i = 0; i < n; ++ i) {
for(int s = 0; s < (1 << i); ++ s)
tmp[s] = mul(tree[s], cnt[msk[i] & s]);
exp(tmp, tree + (1 << i), i);
}
注意到长度为 2i 的 exp 复杂度是 i22i,加起来也是 O(i22i)
集合 exp 有两种实现方式,一种是老老实实 exp,另外一个是 std 给出的类似分治的做法。
void exp(int a[], int b[], int n) {
b[0] = 1;
rep(i, 0, n - 1) conv(a + (1 << i), b, b + (1 << i), i);
}
conv 表示对 a,b 子集卷积并贡献到 c
子集逆卷积有两种实现方式,一种是老老实实 逆卷积,另外一个是 std 给出的做法。
类似 清华集训 主旋律 的最后一步:
写到这里,就可以很清晰的发现,如果令 f=−f,那么 nof 就是将 forest 和 g 子集卷积的结果
注意如果直接认为 forest 是 tree 的 exp,按照 主旋律 的分析,知道实际上差了 -1 的容斥系数,所以这里已经取成负数了。
8.23 自习
昨天晚上总算是睡得早了手机玩得少了一点,今天早上起来感觉确实不太一样。
感觉可能这个脑子也和肌肉一样,有超量回复的原理,狠狠的创完脑子之后还需要认真地休息。
上午把昨天 T4 搞明白了,把上次伪模拟赛 T34 补了
中午打球打太投入了下次一定,下午睡了一会儿,起来补了补欠了好几天的总结
晚上有点摆,摸了一会儿/cy。
就这一次。
8.24 模拟赛 8
上午状态不错,下午有点困,晚上不错
8:20 写完 T1
9:00 T2 想法
9:40 过前 3 个样例
10:00 test4/fn 边界 case 好多
10:40 结束 T2
11:30 T3 还是不会
最后打 T4 k = 1/2 的暴力的时候电脑突然死机了,无所谓了
感觉这把状态不错,打的时候比较集中。
考完出来并没有觉得自己的分数有啥优势,以为 T2 切的人应该不在少数,而自己 T3 T4 只有暴力分
看完题解觉得这把有点 G,因为 T4 做法不难,感觉要过一车人了;T3 很有感觉但是没有做出来,非常可惜。
yr 下午发了 cq 的榜,看全榜有点惊讶,本来以为人均 250+,没想到 T2 卡了很多人
增加了信心,觉得并不是没有希望,只要别被繁花蒙蔽双眼。
T2
大力分析画图分析画图。
没想到最后还是有一个边界 case 想错了,可以接受,可以理解
T3
第一眼看到这种从子树里面选一个的,立马想到了 escape through leaf 这道题
先打了 n^3 暴力,然后观察到这个式子看起来就是让我们枚举每一条边并计算贡献的。
简单画图,发现可以类似换根的计算,那么得到了一个 n^2 的做法
考虑将一个点 x 的贡献和准备求答案的其祖先 i 独立开,设一些前缀和啥啥的。
拆完发现,一个点 x 贡献形如 Axs2i+Bxsi+Cx,有二次项,那完蛋了。
后面的时间,验算了一下这个柿子有没有推正确,是正确的,有点拔剑四顾心茫然
想不到这个题还可以咋做,剩下的时间也不多了,滚去 T4。
solution1:from bxy /bx
记 si=∑j∈subtree(i)aj,U=si,A=∑ai,换根 y 到 x 的时候,Δ=wx[(U−sx)(A−U+sx)−sx(a−sx)]=wx(−U2+(2sx+A)U−2Asx)
如果 −2Asx 不存在,那么就可以愉快地将 U 也提出来,括号里面就是一个一次函数,就可以李超树了
令 U=A−U,发现括号里面变成了:
非常简练的式子!非常震撼!
至于这样的思路是如何想到的,bxy 大概是对式子比较敏感,在还没有发现会推出二次项的时候,就提前令 U=A−U;更容易理解的话,就是坚定信念,认为这道题肯定是这个做法,那么剩下的唯一道路就是去除常数项,那么只能想法设法凑系数。
solution2:std
大意是考虑对于一对 i,x,只有 ∑p∈Ti∑q∉Tiapaq(f(p,x)+f(x,q)) 的计算会受到影响,然后推推式子,尽可能地把不变量拆走,然后会比较顺利地得到一个一次函数。
T4
反思一下 T4 为啥没有想到,大概是 8.5 日订正 里想奈 的时候,由于自己的做法可以过,所以并没有认真学习 solution 中提到的这种更为通用的 hash 做法,导致考场上的思维一直是在构造某一个操作。
思考了单位根等等,但是都不可以/fn
正解考虑记 cnt[i][j] 表示数字 j 在前缀 i 中出现的次数,那么一个 l,r 合法当且仅当 cnt[r]−cnt[l] 每一项 modk 下相等
给 cnt 上个 hash,剩下一个莫队
[AGC040D] Balance Beam
人类智慧,不可思议!
明天写。
后天写。
upd 8.27 哈哈,大后天写的。
非常神奇,首先注意到 A 可以抓到的是一个前缀 B,问题是最大化可以抓到的前缀长度
考虑一个 时间-距离图,表示走到 i 需要的时间。
那么 a 能够抓到 b 当且仅当两条折线存在交点,问题等价于不断尝试将折线 B 向下平移直到和 A 折线只有一个交点,此时 B 折线和 x 轴交点值就是对于当前的 B 折线,A 可以抓到的最大前缀长度。
怎么样才能最大化与 x 轴的交点值呢?
注意到 (n,∑a) 是定点,那么问题等价于从 (n,∑a) 出发,想要尽快地下降到 0。
考虑下降过程对应的上升过程是:从 y=0 开始,走一段 B,直到走到 A 和 B 的交点,开始走 A,一直走到 (n,∑a)。
注意到当 x>A和B的交点 后,可以有 ai>bi;交点之前,可以有 ai<bi(这个是令人误会的描述)
贪心的思考,将序列按照 max{a,b} 排序,能否认为最优解一定是 max{a,b} 的一段后缀呢?发现是可以的。
所以,只需要枚举 B 的零点在 [i,i+1],然后二分对应后缀长度使得 bi+sufsum>=∑a,贡献答案即可。
复杂度 O(nlogn),注意 0 点可能不是整点的细节。
8.25 模拟赛 9
8:20 T1 idea
9:00 过大样例,但是大样例未免太水了
9:10 结束 T1 对拍,但是似乎没有造出有强度的数据。。。
9:30 T2 idea
10:20 T2 idea 假得离谱
11:30 修好调完
这场最大的失误在于 T2 一个假做法浪费了 1h,以及在做 T2 过程中出现的心态问题。
做 T1 的时候心态还是比较正常的,比较集中;
自从 pyb 问了一下我的情况,整个人就感觉很有压力了。杂念太多,境界不够,也许最后阻挡我成功的就是 day1 状况良好, day2 心态虚浮。
不知道能不能学到省选,说不定 NOIP 挂翻了,当然这都是以后的事情。
T1:写错了一个小细节,subtask,100->9,好活。
由于这个细节比较小,随机数据不好弄到,没有拍到,G。
T2:
pyb 没问之前,做 T2 就有一点着急了,因为觉得自己 T1 做得有点久,T2 做慢了就 G,而且这个 T2 看起来不难。
然后违背了一个至关重要的原则:
think twice, code once
而是采用边写边想,这种方式对于一些垃圾的 ABC 题可能是可以,但是这时模拟赛,哥。
最后总算得到正确的做法:分析过程,简化成求解拓扑序固定的值的方案数,将 DAG 简化成树,做树形 DP。
std 不太一样,大意是由于拓扑序固定,然后可以直接做 DP 之类。
upd 树形 DP 的复杂度不小心假了,还是某位不知名的高一大佬帮忙指出,难怪跑这么慢,修了修。
T3 石樱旅行
很厉害的题目,部分分引导正解的典范。由于懒得写题解了,所以截了图方便以后看
T4 完美的算数教室
线段树区间合并题。

合并的时候注意讨论 res.r = l.r + r.r 这种情况。
8.26 模拟赛 10
8:30 发现自己的 T1 写了一个超级假算法
9:00 不能用 s 判
9:40 大样例 3 为什么不对!
10:20 垃圾题。
10:45 打完 T2 90pts
10:50 T3 idea
11:30 1 2 5 14 42 132 到底是啥序列/fn
12:00 卡 特 兰 数
虽然说 T1 题目有问题浪费了 80min 左右,但是事实上 T1 写的并不是正解。
感觉可能是差点沉淀,T1 居然不会判定一条边是否在 s→t 的最短路上,先是用 dis[s][u]+w==dis[s][v] 判,发现不太行,居然认为用 dis[u][t]==w+dis[v][t] 判定就可以了,纯傻波一。
T2 纯消愁,比较迅速的想到了正确的思路,但是贪心的起点应该是 1ll<<21,而不是从 ⋃ai 开始,并认为只要先处理掉 ⋃ai 的超集,其他选的数字不会 >⋃ai
T3 底力不够,推某一段的贡献系数的时候,最开始自己推出来是双阶乘,这个是没有考虑到第一行应当有序;然后打表找规律,看到 1 2 5 14 42 这样明显的卡特兰不知道,然后还错误地将卡特兰数的通项背成了 (2nn)n,纯消愁,不知道自己把通项公式重新自己推一遍吗,推这个很难吗?
当然也有时间压迫的问题,导致当时硬是反应不过来卡特兰数是啥。后面冷静下来,决定不打表找规律自己推,发现是括号序列方案数,那不就是卡特兰/fn
T4 没有时间了,只看了题面。感觉 4 道题真的太快了,前面只要多调一会儿,后面就没有时间了。
希望可以在正式赛之前暴露尽可能多的问题出来,早早查漏补缺。
T4 [WC2011] 拼点游戏
画图可以发现选择的必然是所有上升段的左右端点。
而一次操作是将一个 上升段的右端点p 和 下一个上升段的左端点q 靠近,那么会同时减少两方面的权值。由于要保证操作之后两端点不会重合,且顺序关系不变,所以最多可以让权值减少 a[p]−a[q]−minq−1i=p(a[i]−a[i+1])
想到这里没想了,其实已经差不多了,感觉应该再多想想,别怕想错。
solution:
这里出现了差分相关的贡献,同时注意到修改操作也是区间加法,那么自然放在差分序列上考虑,令 di=ai+1−ai,i∈[1,n−1]
那么 ans1=∑(d>0)d,对于一段下降段 [l,r],第二个人可以减少的权值是 ∑dri=l−maxri=ld(注意这部分的 d 都是负数)
由于一次操作只会操作两个端点,所以考虑用 set 维护所有的下降段 [l,r],然后一个区间的贡献插入到权值线段树,类似主席数求 k 大地回答第二问即可。
8.27 晚自习
调完了昨天的 T4,补了昨天的总结,写了大前天的 [AGC040D] Balance Beam
和大家交换了一下关于 9 月份以及未来学习的意见。
秒了 「JOISC 2022 Day1」监狱,但是没写。
8.28 自习
上午本来说写 监狱 的,但是感觉线段树要打吐了,不想写,觉得多项式比较有意思,学习了一点多项式
下午给 zqm 讲了 图论题。
晚上做了一点题有点犯困,开始比较悠闲地思考,最后在推 [EGOI2021] Lanterns / 灯笼,挺有意思的 DP
「CF438E」The Child and Binary Tree
设 fi 表示权值为 i 的二叉树数量,gi 表示 c=i 是否存在。
那么 fn=1+∑i+j+k=nfifjgk,设 F,G 是对应 OGF,也就是 F=1+F2G
考虑运用求根公式(如果你因为「不可求逆」而感到困惑,不妨临时将运算视为分式域上的运算,即形式 Laurent 级数)或直接对其牛顿迭代即可。
—— aleph1022
(没看懂,但是不管)
求出来 F=1±√1−4G2G,发现取正号的时候不满足 f0=1,所以舍弃
求逆要求常数项非 0,做一个分子有理化,F=21+√1−4G
CF755G PolandBall and Many Other Balls
学习了两种方法:
倍增 NTT
据说是套路。
设出生成函数,有 Fn=(1+x)Fn−1+xFn−2,发现可以实现一个类似线性递推的形式,可以实现 (n−1,n−2)→(n,n−1),考虑能否实现 n→2n
发现 Fa+b=FaFb+xFa−1Fb−1,带入 a=b=n,F2n=F2n+xF2n−1
简单推导一下,发现可以做到 (Fn,Fn−1,Fn−2)→(F2n,F2n−1,F2n−2)。
那么可以直接套倍增 FFT。
这样类似的对于多项式进行倍增操作的还出现在 完美的集合
特征方程求通项
特征方程是什么? - 知乎用户的回答 - 知乎 讲得非常厉害
这个东西就和 2022 HL 暑假集训 的特征值、特征多项式有了联系,回去看了一眼发现发现我已经看不懂我写的东西了,不管了/hsh
这其实就是 7 月份水土集训的时候看的有点迷迷糊糊的 [Gym100299J]Captain Obvious and the Rabbit-Man 所需要的关键
简单说一下,对于一个 k 阶常系数线性递推 a(n+k)=∑ki=1cia(n+k−i),其特征方程是 λk−∑ni=1ciλk−i=0
由于 xxx,如果这个特征方程的 k 个特征根无重根,那么对于 ∀i∈[1,k],a(n)=λni 是原线性递推的一个特解,这个是容易验证的。
由于是线性递推,所以 λn1,λn2,…,λnk 的任意线性组合 ∑ki=1αiλni 也是一个解
回到这道题。
Fn=(1+x)Fnn−1+xFn−2,其特征方程是 z2=(1+x)z+x,解出来两个特征根:
设通项 Fn(x)=c1zn1+c2zn2,又知道 F0=1,F1=1+x,可以解出 c
带回通项:
由于 z2 常数项为 0,所以 zn+12≡0,去掉 z2 项,化简成:
可以模仿集合幂级数 exp/ln,暴力计算 exp/ln,可以发现这样复杂度是 O(m),所以对应的多项式快速幂也可以做到 O(m),当然这个是卡常技巧。
O(mlogm)
8.29 模拟赛 11
8:07 T1 idea
8:30 T1 run 4s...let's believe.
9:30 脑子被 T2 转晕了,集中,乐在其中。
10:10 脑子清醒了
11:00 T2 写不对!GGG
11:20 i'm sb,把 solve(rs) 写成 solve(ls)
12:00 T3 idea,but i have no time even code nature A.
昨天晚上玩得有点晚导致略微犯困 总体状态不错,打的时候心态很好,没有因为 T2 比较绕而笋干爆炸。
虽然 T3 时间再给多一点也不太能切,T4 时间多一点也不太能切,但是 T2 花费 3h 着实有点久,应当控制在 2h 内,这样才有 T34 高档暴力的机会。NOIP 应该也不会这么难?
晚上订正 T4,本来以为应该挺好弄,但是被一个细节卡了半天 qwq
T1:分治我的超人,本来以为复杂度是假的,手造几个极限数据发现跑 4s 左右那么还行就没管了。
下午分享的时候发现居然是真的,意料之外~
std:
发现难点在于模数不是质数导致可能不存在逆元,那么套路地考虑将模数质因数分解,那么就有逆元了,这里并不需要 CRT 合并。
这个方法是我没有想到的点,感觉自己的数学方面有点不成体系,找时间再搞搞。
T3 夏虫
设 fx 表示从 x 开始需要买多少次,那么答案是 ∑ri=lfi+(r−l+1)×(n−1)
简单分析,可以发现 设 Lx 是 a1,a2,…,ax 的后缀最大值集合,Rx 为 ax,ax+1,…an 的前缀最大值集合,那么 fx=|Lx⋃Rx|−1
然后不小心把路走歪了:
- 考虑一个值 v 什么时候可以出现在 Lx⋃Rx 中,发现如果 v 是全局最大值,那么对于所有的 x 都是可以的;如果 v 是全局次大值,设全局最大值出现在 p1,p2,…,pm,发现区间 x∈[1,p1−1]∪[p1+1,p2−1]… 都是可以的
- 考虑一个数 ai,首先可以暴力递归求出 li,ri 表示 x∈[l,r] 可以取到 i
- 那么如果没有交换操作的话,只需要对 li,ri 区间加,然后前缀和即可以回答询问。
- 考虑交换 ax,ax+1,会产生影响的是:不妨设 ax<ax+1
- 设交换后 l′x+1,r′x+1=x+1,y
- ∀i∈[x+2,rx+1],li=x+2,i≥y, li=x+1
- ∀i∈[L,x−1],ri=x, ri=x−1
- 当然还有 x,x+1 两个数
- 发现上述操作都可以平衡树暴力维护集合 L[j],R[j] 分别表示所有 li=j,ri=j + 线段树维护区间加减求和 实现
上述做法码量很大且有肉眼可见的细节。
solution:
大意是,直接考虑 x,x+1 会出现在那些 Li∪Ri 中,发现是一个区间。
具体的:

(这里贺了 sol 的图,但是 fzoi 看不见外图床,问题不大)
T4 万分之一的光
并不简单的题。
可能是比较经典的技巧,对于这种树上 DP 选点顺序的题,一般都可以转化为对边进行定向。
类似的题目有 CTS2022D1T2。
然后顺理成章地设 fu,i,gu,i 分别表示 u 子树,向内/外有 i 个点可以到达,最大价值。同时对应 (u,fau) 的定向方案。
粗糙的转移:fu=∏max(fv,gv)+au,gu=∑∏sgv∗fU∖s
顺理成章地设一个 hj,k 表示钦定最终 u 有 j 个点可以到达(不管子树内外),子树内有 k 个的最大价值,然后考虑不断加入子树进行合并。
复杂度 O(n3),有一点细节。
8.30 模拟赛
9:00 T12 不会,fk
10:00 T3 可做,T4 不太会,滚回 T12
10:30 T2 idea
10:50 T2 无大样例, let's believe
11:30 T3 我纯 sb
对于这场很不满意。
首先 T1 打了 2h+ 才走,本来最开始猜测的是如果有两端 0 就赢不了,手模发现这样也可以赢之后,就准备猜测 2n,但是一直没敢。
其次,T2 傻波题,想了一会儿 Hall 定理发现没太会分析,然后走了贪心的路,发现贪心很难,上厕所的时候想起一句话:“没事多连边”,但是一直没有想到链接 a,b。直到 10:30 的时候,也没有想到链接 a,b,而是链接的 a,i,b,非常傻波。
再有,T3 本来觉得自己肯定可以做出来的题,觉得这个纯板子的题,结果算了半天没算出来,有点失望。明明是能力范围内的题,Meet in the Middle 没有想到吗?想过,按度数排序不知道吗?看到题目第一眼就知道要排序;为什么没有做出来呢?
甚至,T4 最开始在思考平面最近点对相关做法,已经想到了分块,然后块内块外分开算,但是凭借这一种奇怪的直觉把这个想法给否了,非常傻波,去想了一些分治类做法发现都不太行。
所幸考场心情始终比较平静,算是通过了心态的考验?
只是换了一种炸心态的表现罢!自从被 T1 搅麻 1h 左右的时候,就有了些许摆烂的心情了,这样的心态也是不对的。
摆烂和暂时放弃 T1 这两种状态是应该被区分的,后者是严格执行策略,是积极拿分的。
考场心态调整不到最好怎么办?硬实力怼,两方面都应该着手。
题解没啥好写的,都是傻波题。
T4 代码写错了一些傻波细节,容易写错的地方都没写错。
调 T4 的时候,发现 O2 优化是非常厉害的,他可以将算出来但是没有用到的 code 直接删掉!(这就导致虽然交上去的时候 O(qn2) 的暴力没有删,但是由于暴力所算出来的结果没有被使用,所以被 O2 优化掉了!)
搞明白这个点花了很久的时间,导致晚上没做啥事/hsh
8.31 自习
有点给自己放假了,但是问题不大。
[EGOI2021] Lanterns / 灯笼
打着灯笼都找不到的好题,状态优化的经典!做得很高兴
首先有一个傻瓜 DP,fl,r,s,已经走了山脉 [l,r],并且使得高度集合 s 合法的最小代价。
发现一个区间合法的充要条件是 [minri=lhi,maxri=lhi]⊂s
观察一下转移,发现集合 s 可以认为一直都是某一个区间一步一步扩大的,即规定每次新增的区间都必须和现有的合法区间有交才可以转移。容易发现这样转移和原本的是等价的。
那么自然可以改设状态 fl,r,u,v 表示走了 [l,r],合法区间 [u,v]
状态数还是有点多,进一步思考哪些状态是可以省略的。
思考为什么我需要记录 l,r,这是因为可能同一个 [u,v] 对应多个 [l,r] 但是我并不知道是哪一个。思考为什么我需要记录 [u,v],因为这关系到转移的合法性。
聪明地,改设 fx,y 表示当前 [l,r]=[px,py],[u,v]=[ax,by] 的最小代价。这是因为,对于一个 x,y,对应了一个实际可以走的区间 [L,R],这个状态实际上代表了刚刚所有 l∈[L,min{px,py}],r∈[max{px,py},R] 的 DP 状态,同时也标记到底是哪两个灯笼得到了当前的合法区间。
然后可以随便写写转移,发现很单调队列优化之类的。注意这里必须采用小根堆而不是简单的队列。
CF878E Numbers on the blackboard
看错题了。。。以为既可以是 x+2y,也可以是 2x+y。
知道每一个数字的贡献系数是 2 的次幂,整个过程是对于当前的序列分成多段,每一段是一直合 x+2y|2x+y,然后递归下去做。
对于小块的话,肯定考虑正数合在一起,每一个正数段需要做一个 DP 来决定合并方向,负数肯定单独开,假如正数段很厉害,也可以考虑向前和负数段合并。
问题是,由于有两种方向还有段的合并,所以非常麻烦,不知道那个 DP 应该怎么做才好。。。
solution:
哈哈,只有形如 x + 2y 的合并方式。
我们合并一定是先从前往后合并为若干个块,然后再从后往前依次将每一个块往前合并,最后合并成一个块。所以我们就先只进行第一类合并,第二类合并可以直接将后面的块的数的权值乘上 2。
假设我们前 i 个数已经合并成了若干个块,考虑加入第 i+1 个数,如果新开一个块它的权值就是 1,否则就是 2l+1,其中 l 是上一个块的长度。
- 如果 a[i+1]>0,那么我们肯定将 i+1 合并到前一个块中。
- 如果 a[i+1]≤0,我们就新开一个块存它。
注意将 i+1 合并到前一个块中的时候,可能导致前一个块的和也变成正数,此时我们需要一直往前合并直到剩余一个块或该块和为负数。
询问是 trivial 的,可以离线处理。
「NOI2020」超现实树
一个比较歪打正着的理解题解的方式:
注意替换操作只能在叶子做,一些只有单个儿子的玩意也是做不了的,那么感性一下,觉得比较使得答案是 NO。(所以考虑不可以总司令)
思考一下如果给的是单个完全二叉树,发现一条长链可以秒掉,这时因为出现了完全二叉树有而链没有的叶子。
尝试对于给定的一个树的集合,考虑找一个 ∉grow(T) 的树出来,即考虑判不合法,称我们在构造的树叫做 boss
boss 是很厉害的,不可以是集合中某一个颗树的子集。
boss 特立独行,对于每一个棵树,得存在某一个叶子不会出现在 boss 中,那么贪心一点,我们发现 boss 是一条链多好的。
既然 boss 可以是一条极长链,发现对于所有不是 “链树” 的树已经被秒掉了,可以直接把这部分从给定的森林中删除,因为没有用。所谓的 链树 指的是每一个节点都满足 min{siz[ls],siz[rs]}≤1 的树。
按照这个理论,实际上应该只保留所有的链,但是这样显然是不可以的,因为 boss 不仅可以比树少叶子,还可以多叶子,所以应该保留链树。
所以似乎那些不是链树的玩意能秒又不能秒,仔细考察他们能够阻挡多叶子的情况吗?
想了一想发现还是不行,这是因为多叶子的极限情况一定形如 boss = 链树,而这些非链数无法变成链树。
很愉快的,图中只剩下链树。
而经过上面的思考,发现必须能够把每一种 链树 都能够表达出来才合法。
考虑所有链树合并在一起形成的树,考察树上的每一个点 u,如果存在某一个链树使得 u 是叶子,那么皆大欢喜,否则(根节点没有被“逮住”)需要满足:
- 存在一个链树,使得 u 只有左儿子,并递归左儿子。否则会被 boss = 1…u+rs hack
- 存在一个链树,使得 u 只有右儿子,并递归右儿子。否则会被 boss = 1…u+ls hack;
- 存在一个链树,使得 u 左右儿子都有,且左儿子是叶子,并递归右儿子,否则会被 boss 是合并后的树 + 这个不存在的左儿子 hack
- 存在一个链树,使得 u 左右儿子都有,且右儿子是叶子,并递归左儿子,否则会被 boss 是合并后的树 + 这个不存在的右儿子 hack
对四种情况,合并的时候建立四叉树以确保所有情况下成立。
正经的题解思考路径:Karry
AGC033D Complexity
先设一个傻波 DP,然后发现答案值域很小,于是 交换答案和状态
发现复杂度还差一点,感性理解发现决策点单调。
TopCoder 12158 SurroundingGame
经典最小割
9.1 自习
上午帮 czl 看 CF1175G Yet Another Partiton Problem,自己也复习了一下这道斜率优化毕业题。
ABC290EX Bow Meow Optimization
没有想象中的难。
设 d 表示每一个点的 |x−y| 的系数,容易发现对于每一个物种, d 是单谷,所以 a 应该呈现单峰的放置方式
猜测如果把猫狗两个单峰放在一起之后,最优的情况也应该是单峰。经过交换法证明,是正确的。
可以考虑 DP 了,当然不可以考虑只从某一边开始 DP,这样是难以迎合上述性质的。
尝试做这样一个 DP,按照权值从小到大排序后,可以设 fi,j,k 表示放了 i 只猫狗,前缀放了 j 只狗,前缀放了 k 只猫。(后缀放了 cat−k 只猫)
转移形如:
if (c[i].scd)
f[i][j][k] = min(f[i][j][k], f[i - 1][j - 1][k] + c[i].fst * abs(k - (m - k))),
f[i][j][k] = min(f[i][j][k], f[i - 1][j][k] + c[i].fst * abs(cat - k - (m - (cat - k))));
else
f[i][j][k] = min(f[i][j][k], f[i - 1][j][k - 1] + c[i].fst * abs(j - (n - j))),
f[i][j][k] = min(f[i][j][k], f[i - 1][j][k] + c[i].fst * abs(dog - j - (n - (dog - j))));
算答案的时候,枚举 j,k 表示分界点的位置即可。
但是这样是错误的,经过 assert,发现会在 n/m 存在奇数的时候挂掉。这是为什么呢?
solution:
首先还有一个贪心结论:对于 n,m 都是偶数的情况,发现两边一定是各有 n2 只狗,各有 m2 只猫,即答案一定在 f[n+m][n/2][m/2]。
对于存在奇数的情况,先把最大值放在最中央,就可以变成偶数的情况,这样放最大值是可以证明正确的。
分析一下,对于仅 n 是奇数,最优解是通过 f[n+m−1][n/2][m/2] 放一只狗转移到的 f[n+m][n/2+1][m/2] 且仅有这一个状态可以转移到它,但是如果最后一只动物是猫,那么就坏了。
也就是说,上述的贪心,”猫狗两个单峰放在一起之后,最优的情况也应该是单峰“,只在 n,m 都是偶数的情况下成立,所以需要特判一下。
这个问题纠结了我 70min 往上走...
这样是 O(n3) DP
solution2:
更进一步地研究 solution 中给出的额外的贪心结论,对于左侧而言,右侧的猫狗数量是固定的;对于右侧也是。所以两侧的贡献是独立的。
对于一侧,把这个问题放在二维平面上考虑,视作是一条从 (0,0) 走到 (n2,m2) 的折线。
画画图,可以发现 ∑d=2×n2×m2,是一个定值。而我们的目的是 ∑da 尽力小,考虑给大的 a 分配小的 d。
考虑如下的贪心过程:我们从中心开始往两侧填。假如目前这个是狗,且右边能放(即右边数量 <n2),那就放右边,代价为右边猫的个数乘上 ai;假如这是猫,且左边能放,那就放左边,代价为左边狗的数量乘上 2ai
对应到二维平面上,就相当于从 (n2,m2) 倒着走,对于代表右侧的二维平面,尽快往左走;代表左侧的二维平面,尽量往下走。在之前对于 ∑d 的分析中,我们可以理解为什么系数是 2ai,并理解这个贪心的正确。


【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· 地球OL攻略 —— 某应届生求职总结
· 周边上新:园子的第一款马克杯温暖上架
· Open-Sora 2.0 重磅开源!
· 提示词工程——AI应用必不可少的技术
· .NET周刊【3月第1期 2025-03-02】