
SQL Server SQL性能优化之--pivot行列转换减少扫描计数优化查询语句
原文出处:http://www.cnblogs.com/wy123/p/5933734.html
先看常用的一种表结构设计方式:
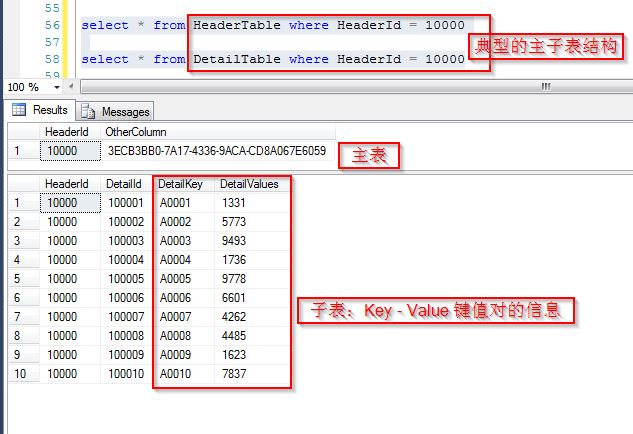
那么可能会遇到一种典型的查询方式,主子表关联,查询子表中的某些(或者全部)Key点对应的Value,横向显示(也即以行的方式显示)

这种查询方式很明显的一个却显示多次对字表查询(暂时抛开索引)
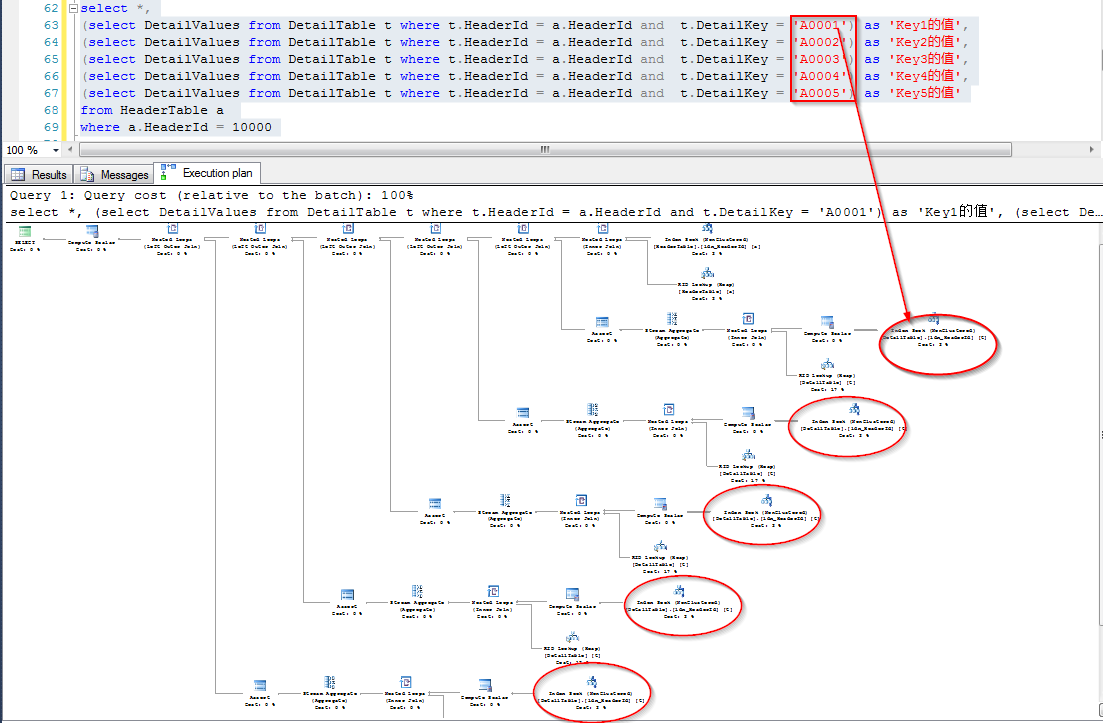
相比这种查询方式很多人都遇到过,如果子表是配置信息之类的小表的话,问题不大,如果字表数据量较大,可能就会有影响了。
这个查询目的是将”纵表”存储的结果“横向”显示,相当于横列转换的感觉了。
可以将子表的结果一次性将纵表的结果转换成横标,再跟主表连接,
然后得到一个最终一样的查询结果(格式),就能够减少子表的查询次数
这里将子表的结果“一次性将纵表的结果转换成横标”,是典型的行列转换操作
首先先看一下这里所说的一次转换成横标的这一步骤,需要借助pivot,一步一步来

然后看跟主表join之后,两种查询方式的整体查询结果
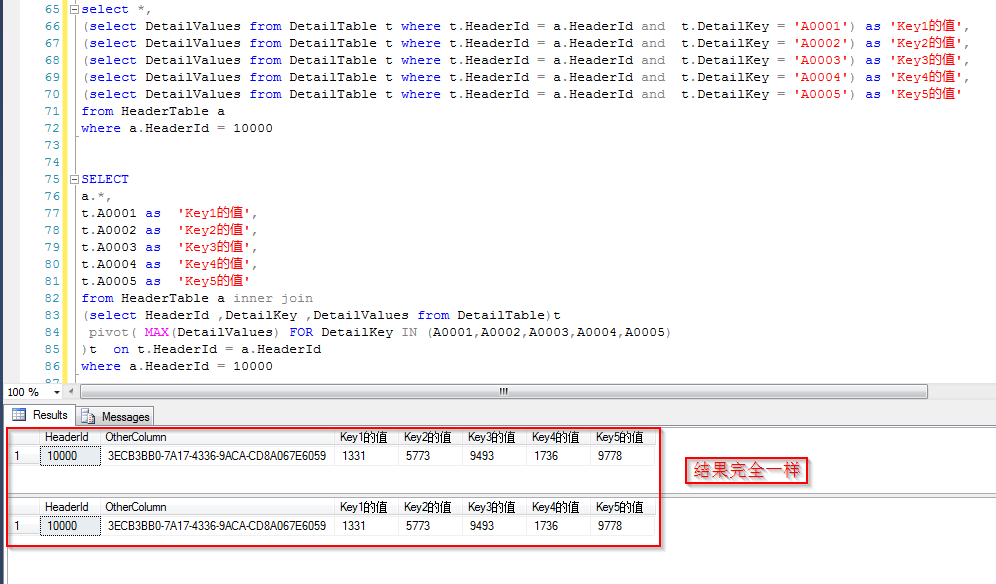
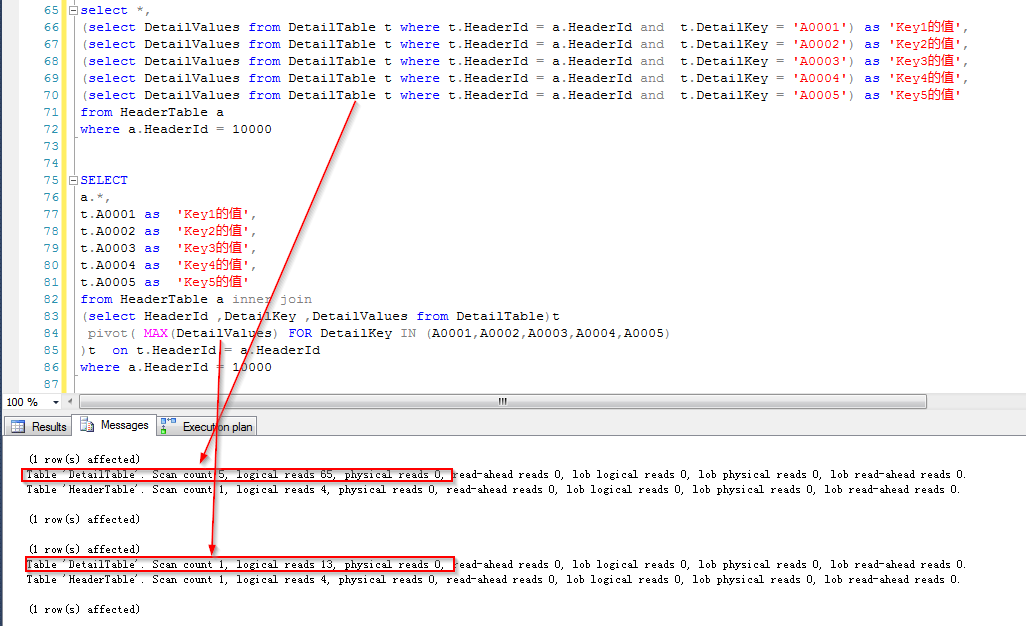
那么看一下后一种查询方式也即通过行业转换之后做join的执行计划,可以看到只对字表进行了一次查找(这里是index seek,但是暂抛开索引)
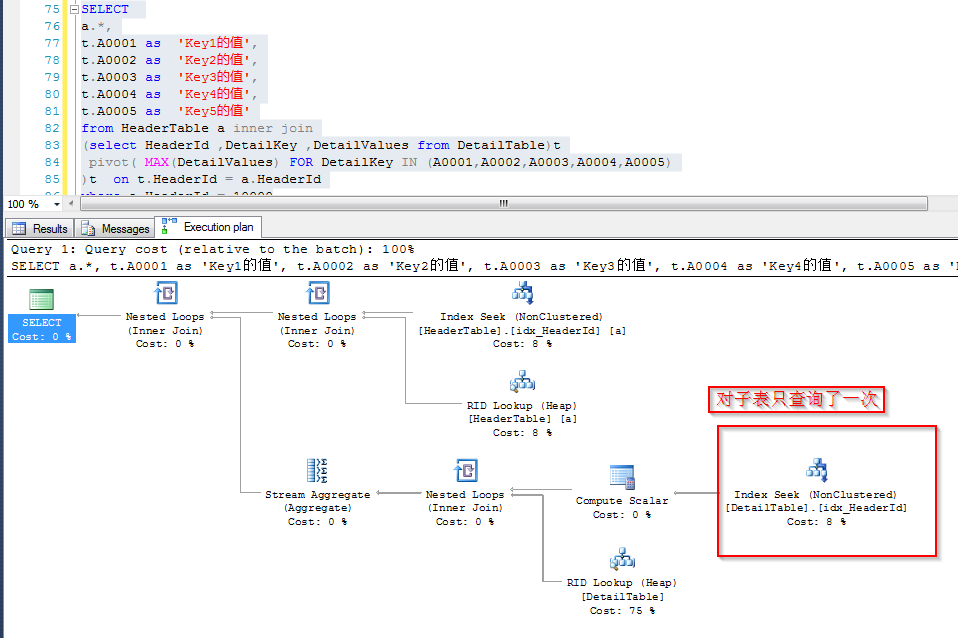
观察一下两条SQL的IO信息,可以发现,前者的Scan count是5,逻辑读是65,后者的Scan count是1,逻辑读是13,65=13*5。可见后者是一次性将表中的几个Key值读取出来的,而前者每个Key值读取一次表。
总结:
改写SQL是实现优化的思路之一,当然改写SQL技巧有很多种,本文仅对某一类典型查询提供一个改写思路,避免对一个表进行多次读取的方式来实现的查询。
通过改写一个常用的查询写法,从而实现一个等价的逻辑来减少对基表的读取次数来达到SQL优化的目的。
当然实际情况可能更加复杂,采用该思路改写的时候要注意针对SQL语句测试验证。
附上本文的测试脚本
create table HeaderTable ( HeaderId int , OtherColumn varchar(50) ) create table DetailTable ( HeaderId int, DetailId int identity(1,1), DetailKey varchar(50), DetailValues int ) declare @i int = 0 while @i<1000000 begin insert into HeaderTable values (@i,NEWID()) insert into DetailTable (HeaderId,DetailKey,DetailValues)values(@i,'A0001',RAND()*10000) insert into DetailTable (HeaderId,DetailKey,DetailValues)values(@i,'A0002',RAND()*10000) insert into DetailTable (HeaderId,DetailKey,DetailValues)values(@i,'A0003',RAND()*10000) insert into DetailTable (HeaderId,DetailKey,DetailValues)values(@i,'A0004',RAND()*10000) insert into DetailTable (HeaderId,DetailKey,DetailValues)values(@i,'A0005',RAND()*10000) insert into DetailTable (HeaderId,DetailKey,DetailValues)values(@i,'A0006',RAND()*10000) insert into DetailTable (HeaderId,DetailKey,DetailValues)values(@i,'A0007',RAND()*10000) insert into DetailTable (HeaderId,DetailKey,DetailValues)values(@i,'A0008',RAND()*10000) insert into DetailTable (HeaderId,DetailKey,DetailValues)values(@i,'A0009',RAND()*10000) insert into DetailTable (HeaderId,DetailKey,DetailValues)values(@i,'A0010',RAND()*10000) set @i=@i+1 end create index idx_HeaderId on HeaderTable(HeaderId) create index idx_HeaderId on DetailTable(HeaderId) create index idx_DetailKey on DetailTable(DetailKey) select *, (select DetailValues from DetailTable t where t.HeaderId = a.HeaderId and t.DetailKey = 'A0001') as 'Key1的值', (select DetailValues from DetailTable t where t.HeaderId = a.HeaderId and t.DetailKey = 'A0002') as 'Key2的值', (select DetailValues from DetailTable t where t.HeaderId = a.HeaderId and t.DetailKey = 'A0003') as 'Key3的值', (select DetailValues from DetailTable t where t.HeaderId = a.HeaderId and t.DetailKey = 'A0004') as 'Key4的值', (select DetailValues from DetailTable t where t.HeaderId = a.HeaderId and t.DetailKey = 'A0005') as 'Key5的值' from HeaderTable a where a.HeaderId = 10000 SELECT a.*, t.A0001 as 'Key1的值', t.A0002 as 'Key2的值', t.A0003 as 'Key3的值', t.A0004 as 'Key4的值', t.A0005 as 'Key5的值' from HeaderTable a inner join (select HeaderId ,DetailKey ,DetailValues from DetailTable)t pivot( MAX(DetailValues) FOR DetailKey IN (A0001,A0002,A0003,A0004,A0005) )t on t.HeaderId = a.HeaderId where a.HeaderId = 10000

 浙公网安备 33010602011771号
浙公网安备 33010602011771号