
sqlserver 存储过程中使用临时表到底会不会导致重编译
曾经在网络上看到过一种说法,SqlServer的存储过程中使用临时表,会导致重编译,以至于执行计划无法重用,
运行时候会导致重编译的这么一个说法,自己私底下去做测试的时候,根据profile的跟踪结果,
存储过程中使用临时表,如果不是统计信息变更导致导致的重编译,并不会导致重编译,
但是现实情况下,对于一些特殊的情况,即便是统计信息没有更新,又确实会出现每次运行都重编译的情况,
存储过程中使用了临时表,什么情况下会重编译,什么情况下不用重编译?
为了弄清楚这个问题,查阅了大量的资料,才把这个问题弄清楚,这里特意记录下来,
希望武断地认为存储过程中使用了临时表就会导致重编译的这个观点得到纠正。
首先进行下面的测试,我们知道,导致临时表重编译的因素之一就是统计信息的变化,统计信息的变化依赖于往临时表中写入的数据量,
首选我要控制插入临时表中的数据量不超过统计信息更新而导致重编译的阀值,先排除统计信息的变更导致重编译,
看看仅仅是多次运行SP,是否因为存储过程中有了临时表而会产生重编译
--首选创建一个表,供存储过程中测试使用 create table test1 ( id int identity(1,1), name varchar(50) ) --插入10000条测试数据 insert into test1 values (NEWID()) go 10000 --创建一个存储过程,其中存储过程中定义了一个临时表,根据参数,往临时表中写入数据 create proc testRecompile(@i int) as begin create table #t (id int,name varchar(50)) insert into #t select id,name from test1 where id<@i select * from #t end
那么就开始运行这个SP,然后监控profile,看看第一次运行,以及除了第一次运行之后,到底有没有发生重编译
--第一次运行,代入参数1 exec testRecompile 1 --第二次运行,代入参数2 exec testRecompile 2
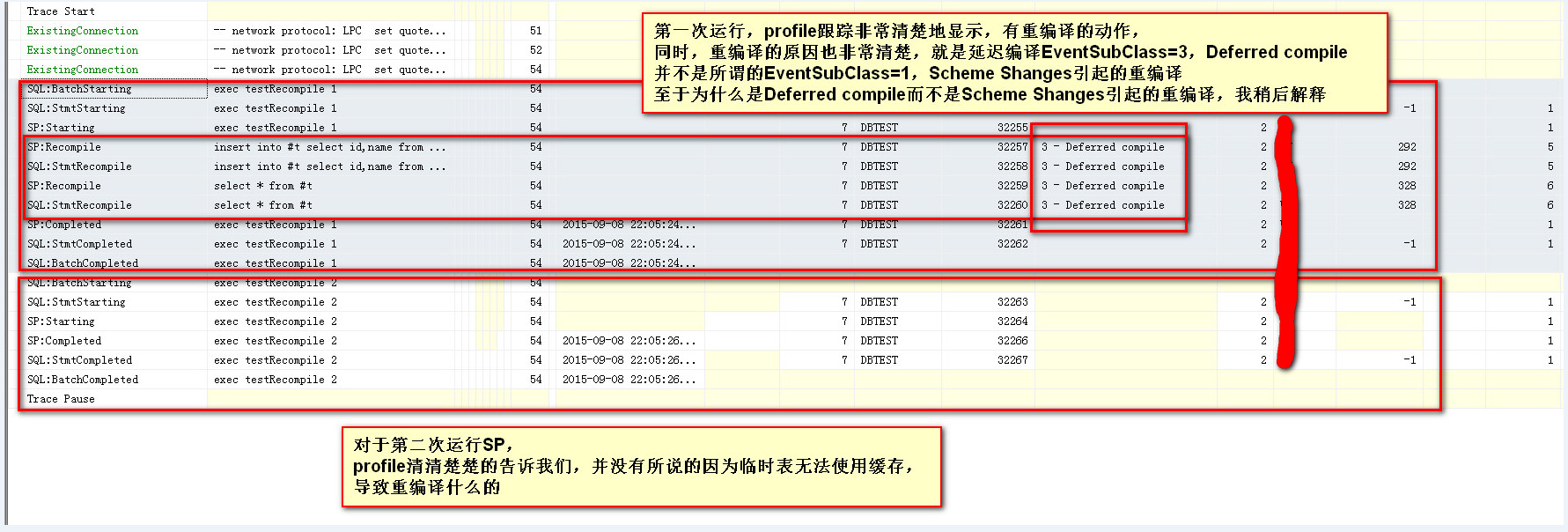
下面是profile的截图,可以很清楚地看到,第一次运行之后,再次运行SP的时候,没有发生重编译的动作,也就是说重用了第一次的执行计划缓存
这里解释两个问题,
1,第一次运行的时候,为什么不是因为架构更改导致的重编译,而是Deferred Compile?
2,第二次运行的时候,为什么没有重编译,因为临时表是每次运行的时候创建的啊,肯定是更改了架构(change schema)了,为什么没有重编译?
首先,说明第一个问题,
1,第一次运行的时候,当存储过程testRecompile编译的时候,
插入语句(insert into #t select id,name from test1 where id<@i)和查询语句(select * from #t),
因为#t表还没有被创建,因为这两句并没有被编译,
编译的时候的执行计划并没有完全完成,
当这个存储过程执行的时候,临时表才被创建,此时才真正的开始编译临时表对象的语句,这个编译的过程是执行的时候完成的,而不是纯粹的编译阶段完成的
所以这是Deferred Compile,也即是运行时才进行的编译,就是所谓的延迟编译(Deferred Compile)。
2,第二个问题,重新运行临时表的时候,按道理,因为创建了临时表,必然导致架构的更改,为什么没有重编译?
这个是因为,存储过程中使用了临时表,对临时表的使用是引用其“名称”(比如这里的#t),而非ID(从临时数据库中查询sys.sysobjects)
虽然多个会话同时运行这个SP的话,每个会话都会生成一个临时表,每个会话生成的临时表的ID都是不同的,
但是要注意的是,存储过程中并没有直接使用临时表对象的ID,而是临时表名字本身,
第一次运行之后,缓存的执行计划与第二次运行时一样的,所以第二次运行这个SP可以重用这个第一次生成的执行计划,
上面说了,在某些情况下,存储过程中使用临时表会导致重编译,这是在什么情况下发生的呢?
因为在某些情况下,要先生成临时表,然后以动态sql的方式去执行一段有临时表参与的sql,此时对于临时表的引用是引用其ID,而不是名称
这个要归结于对于临时表的调用方式,当存储过程中定义了临时表,用sp_executesql的方式调用的时候,这两种执行sql的方式相当于新建了会话,
此时因为不同回话之间,同一个临时表生成的ID是不同的,此时才会导致存储过程中发生sechme change的重编译
上代码
create proc testRecompile2(@i int)
as
begin
create table #t (id int,name varchar(50))
insert into #t select id,name from test1 where id<=@i
exec('select * from #t')
end
DBCC FREEPROCCACHE
--第一次运行,代入参数1
exec testRecompile2 1
--第二次运行,代入参数2
exec testRecompile2 2
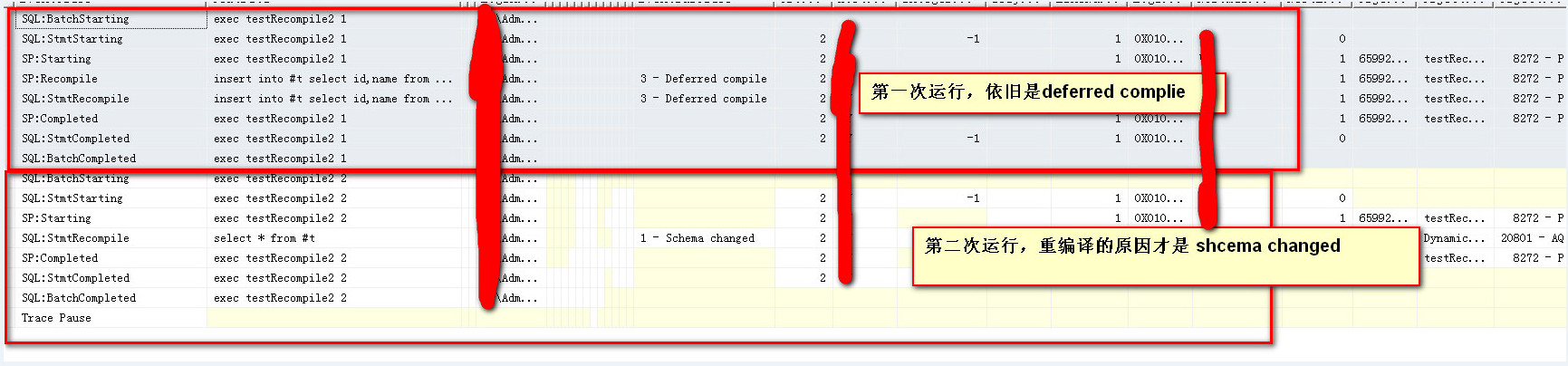
在存储过程中创建了临时表,执行的时候到底发生不发生重编译,取决于你怎么使用这个临时表
以sp_executesql的方式执行临时表的sql的时候,才会发生因为schema change导致的重编译,
因为这两种方式执行sql,相当于新建会话去执行sql,此时对于临时表的引用,是引用临时表生成的ID,不同会话之间的临时表对象的ID是不同的,所以无法重用执行计划,会发生重编译
另外,对于临时表的另一种导致重编译的因素就是统计信息,对于统计信息变更导致的重编译,就不多说了,这个不仅仅会发生在临时表上,普通的物理表上也会因为统计信息变更导致重编译,不止是临时表,唯一的区别就是,导致临时表与物理表统计信息变更的阀值是不一样的
另外,对于统计信息变更导致的重编译,就不多说了,这个不仅仅会发生在临时表上,普通的物理表上也会因为统计信息变更导致重编译,不止是临时表,唯一的区别就是,导致临时表与物理表统计信息变更的阀值是不一样的
我们知道
这个也很容易验证,临时表统计信息更新的阀值依赖于临时表中数据的变化幅度,这个阀值如下
If n < 6, Recompilation threshold = 6.
If 6 <= n <= 500, Recompilation threshold = 500.
If n > 500, Recompilation threshold = 500 + 0.20 * n.

 浙公网安备 33010602011771号
浙公网安备 33010602011771号