
PostgreSQL流复制同步参数与synchronous_standby_names设置
PostgreSQL的流复制,从整体上看,可以粗分为同步与异步两种模式,其中涉及的主要参数包括synchronous_commit和synchronous_standby_names
主节点synchronous_commit参数设置
synchronous_commit
事务提交模式,类似于MySQL的innodb_flush_log_at_trx_commit参数,对应着事务提交后返回给客户端提交成功的时机,可以是off, local, remote_write, remote_apply, or on
不同的值意味着可以在不同的时机反馈事务提交成功的标记,也对应着不同的安全级别,同时影响着事务提交等待的时间。
特定的实用命令,如DROP TABLE,被强制按照同步提交而不考虑synchronous_commit的设定。这是为了确保服务器文件系统和数据库逻辑状态之间的一致性。支持两阶段提交的命令页总是同步提交的,如PREPARE TRANSACTION。
##单实例模式
1. synchronous_commit=off
设置成off表示提交事务时不需等待相应WAL数据写入本地WAL日志文件即可向客户端返回成功。当数据库宕机时最新提交的少量事务可能丢失,但数据库重启后会认为这些事务异常中止。
设置成off能够提升数据库性能,因此对于数据准确性没有精确要求同时追求数据库性能的场景建议设置成off。
2. synchronous_commit=on / local
单实例下设置成 on或local均表示提交事务时需等待相应WAL数据写入本地WAL日志文件后才向客户端返回成功。设置成on理论上事务是绝对安全的,但相对与off需要略微多一点额外的耗时。
##复制模式
1. synchronous_commit=off
含义同上,表示提交事务时不需等待本地相应WAL数据写入本地WAL日志文件即可向客户端返回成功。
2. synchronous_commit=local
含义同上,表示提交事务时需等待相应WAL数据写入本地WAL日志文件后才向客户端返回成功,但是不会关心从节点的情况。
3. synchronous_commit=remote_write
如果没有设置synchronous_standby_names,remote_write跟单实例下synchronous_commit=local含义相同如果设置了设置了synchronous_standby_names:
当流复制主库提交事务时,需等待备库接收主库发送的WAL日志流并写入备节点操作系统缓存中,才向客户端返回成功,此时备库的WAL还在备库操作系统缓存中,。
笔者认为这种提交模式在数据安全的情况下,实际上已经足够了。
除非一个事物提交之后,在standby节点WAL日志固化之前的wal_writer_delay(默认200毫秒)这个间隔内,同时发生这两个事件:1,主节点磁盘故障导致数据损坏;2 ,standby节点操作系统发生宕机。才有可能造成数据丢失,其实概率已经非常非常低了
4. synchronous_commit=on
如果未设置synchronous_standby_names,on跟单实例下含义相同
如果设置了synchronous_standby_names,on跟单实例下含义不同,此时表示流复制主库提交事务时,需等待备库接收主库发送的WAL日志流并写入WAL文件,也即主备的WAL日志同时落盘之后,之后才向客户端返回成功。
5. synchronous_commit=remote_apply|
如果未设置synchronous_standby_names,remote_apply等同于on,跟单实例下含义相同。
表示流复制主库提交事务时 ,需等待备库完成相应的WAL日志的apply才向客户端返回成功。
也就是说从数据需要接收主节点WAL日志,并且完成了WAL的“翻译”工作,主备数据完全一致的情况下才返回事务提交成功的标记
与synchronous_commit相关的其他参数:
wal_writer_delay
异步提交时,也即synchronous_commit=off时,经过wal_writer_delay(默认200毫秒)之后会自动将wal日志持久化
fsync
默认On,如果该参数开启,PostgreSQL服务器将通过发出fsync()系统调用或各种等效方法(参见wal_sync_method)来确保更新被物理地写入磁盘。这确保了在操作系统或硬件崩溃后,数据库集群可以恢复到一致状态。
虽然关闭fsync通常可以提高性能,但在电源故障或系统崩溃的情况下,这可能会导致无法恢复的数据损坏。因此,只有当您可以轻松地从外部数据重新创建整个数据库时,才建议关闭fsync。
commit_delay
类似于MySQL的group commit原理,设置commit_delay会在执行WAL刷新之前添加时间延迟。 如果系统负载足够高,使得在给定时间间隔内有更多事务准备提交,这可以通过允许更多事务通过单个WAL刷新来提高组提交吞吐量。
然而,这也会增加延迟,最多为每个WAL刷新的commit_delay。 因为如果没有其他事务准备提交,延迟就是浪费的,所以只有在至少有 commit_siblings其他事务活动时才会执行延迟, 当要启动刷新时,如果fsync被禁用,则不会执行延迟。
如果未指定单位,则将其视为微秒。 默认commit_delay为零(无延迟)。 只有超级用户和具有适当SET权限的用户才能更改此设置。
从节点的standby_names设置
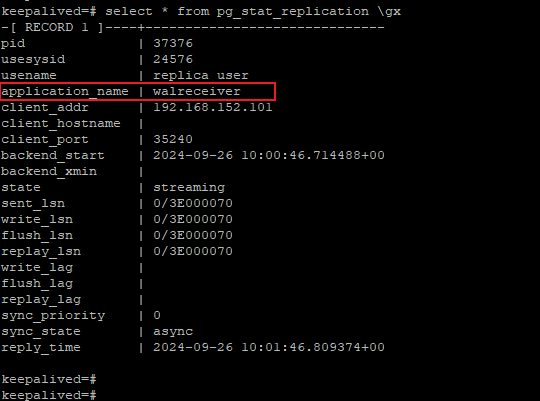
在synchronous_standby_names指定的备用节点的名称,备用服务器可以通过查询pg_stat_replication视图中的application_name字段来得到。
如果未明确设置application_name,则将使用备用服务器的cluster_name(在PostgreSQL 12及更高版本中),但是默认情况下postgresql.auto.conf是不包含application_name,cluster_name也是空的,所以这个application_name只能是默认字符串walreceiver,而walreceiver是不具备实际意义的。
1,在从节点postgresql.auto.conf添加application_name信息
在搭建流复制的过程中,使用pg_basebackup会备份主库的之后,备份文件中会自动生成一个postgresql.auto.conf的文件,这个文件中包含了primary_conninfo和primary_slot_name。
默认是不包含application_name信息的,所以流复制启动之后,主节点上看到的是一个walreceiver的通用的名字
primary_conninfo = 'user=replica_user password=123456 channel_binding=disable host=1.1.1.1 port=1234 sslmode=disable sslcompression=0 sslcertmode=disable sslsni=1 ssl_min_protocol_version=TLSv1.2 gssencmode=disable krbsrvname=postgres gssdelegation=0 target_session_attrs=any load_balance_hosts=disable'
primary_slot_name = 'pgstandby_slave01'
以上是postgresql 16版本的pg_basebackup生成的备份文件中的postgresql.auto.conf,默认情况下primary_conninfo中是不包含application_name的
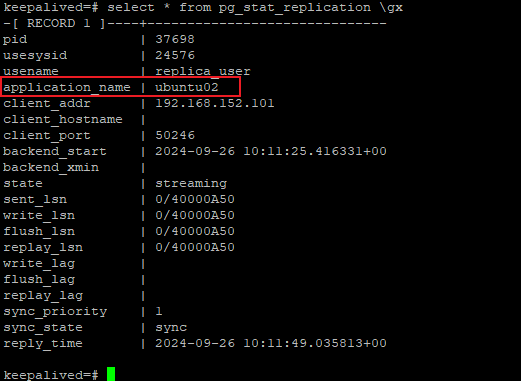
可以通过再primary_conninfo连接串中增加一个application_name=ubuntu02来标识(当前)从节点的standby_name,比如如下
primary_conninfo = 'application_name=ubuntu02 user=replica_user password=123456 channel_binding=disable host=1.1.1.1 port=1234 sslmode=disable sslcompression=0 sslcertmode=disable sslsni=1 ssl_min_protocol_version=TLSv1.2 gssencmode=disable krbsrvname=postgres gssdelegation=0 target_session_attrs=any load_balance_hosts=disable'
primary_slot_name = 'pgstandby_slave01'
2,设置cluster_name参数
除了上述在postgresql.auto.conf配置文件中添加application_name属性信息之外,也可以从节点上设置postgresql.conf中的cluster_name参数
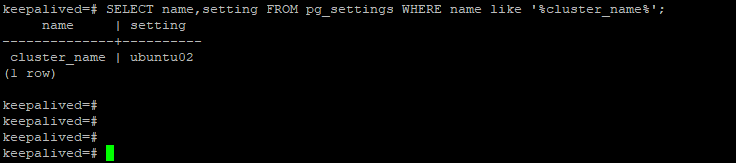
在使用pg_basebackup默认生成的备份文件中,无须在postgresql.auto.conf添加application_name信息,主节点也能识别到从节点的application_name为这里配置的cluster_name。
synchronous_standby_names设置
该参数指定流复制中需要同步复制的服务器列表,需要配置standby服务器的名字,也即主从运行正常情况下,主节点上的pg_stat_replication系统表中的application_name信息,至于什么是standby服务器名字,以及如何设置standby服务器名字,上面也做了阐述,几种典型的synchronous_standby_names设置方式:
1,设置WAL日志强同步至某个节点
设置当前节点与ubuntu02节点wal日志写入成功后,返回客户端提交成功
synchronous_standby_names = 'ubuntu02'
2,设置WAL日志强同步至N个节点中的某M个节点
按照指定节点的顺序,WAL至少强同步至两个节点
synchronous_standby_names = 'FIRST 2 (ubuntu02,ubuntu03,ubuntu04)'
按照指定节点,无顺序要求,WAL至少强同步至两个节点
synchronous_standby_names = 'ANY 2 (ubuntu02,ubuntu03,ubuntu04))'
如果当前节点在事务提交的时候,synchronous_standby_names中的节点未达到当前节点synchronous_commit设定的要求,则当前事务会被挂起,直至满足synchronous_standby_names中设定的要求
其他修改synchronous_commit提交模式的方式:
单个事务,事务级别: SET LOCAL synchronous_commit = ''
Session级别: SET synchronous_commit = ''
User级别: ALTER USER someuser SET synchronous_commit = ''
Database级别: ALTER DATABASE SET synchronous_commit = ''
实例级别: 修改postgreql.conf的synchronous_commit = ''
参考:
https://www.crunchydata.com/blog/synchronous-replication-in-postgresql
https://pgpedia.info/s/synchronous_standby_names.html

 浙公网安备 33010602011771号
浙公网安备 33010602011771号