
追踪SQL Server执行delete操作时候不同锁申请与释放的过程
一直以为很了解sqlserver的加锁过程,在分析一些特殊情况下的死锁之后,尤其是并发单表操作发生的死锁,对于加解锁的过程,有了一些重新的认识,之前的知识还是有一些盲区在里面的。
delete加锁与解锁步骤是怎么样的?什么时候对那些对象,加什么类型的琐,加锁与索引的关系是怎么样的,什么时候释放锁?整个过程锁是如何参与整个delete操作过程表的?
这里通过一个非常简单的delete语句,来分析一条delete执行过程中加解锁的过程。
测试表创建
用一个最最简单的例子做了跟踪,对锁的申请和释放,有了更清晰的认识,这个过程非常有意思,看完之后会非常清晰地认识到delete语句执行过程中加解锁的步骤是怎么样的。
如果对一个SQL加解锁的步骤不清楚,解决死锁,只能说经验,或者说是靠蒙、亦或靠优化SQL地去减少死锁的可能性(天下武功,唯快不破)。
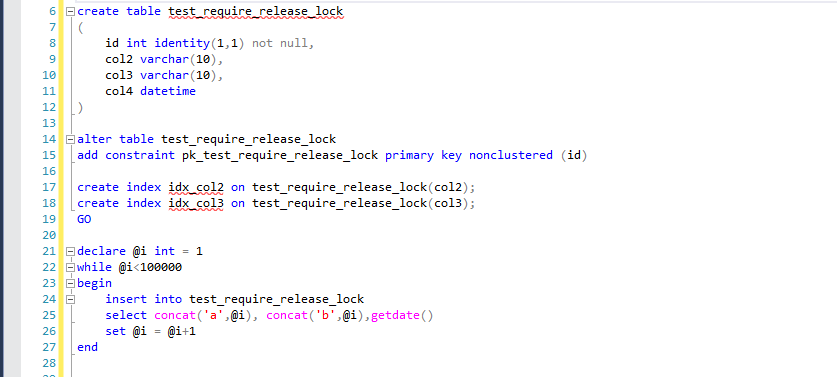
如下脚本,创建测试表,待用。
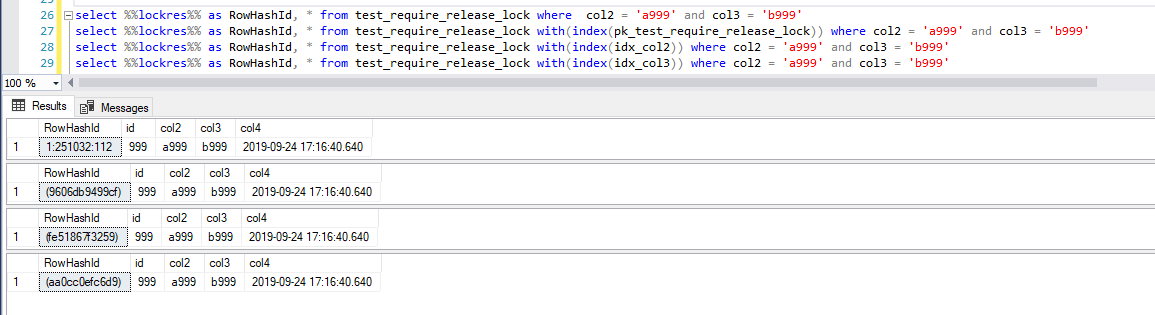
跟踪的测试删除sql语句为:delete from test_require_release_lock where col2 = 'a999' and col3 = 'b999',where条件的目标数据是1行,条件是用到where的第一个筛选条件的索引。
测试数据的基本信息
先拿到一些基本的信息对象id,索引Id,key值等物理Id(RowHashId)等等,这些Id稍后会清晰地展示在profile跟踪日志中,能帮助我们去了解到底在什么对象(数据行,索引行)加什么类型的锁。
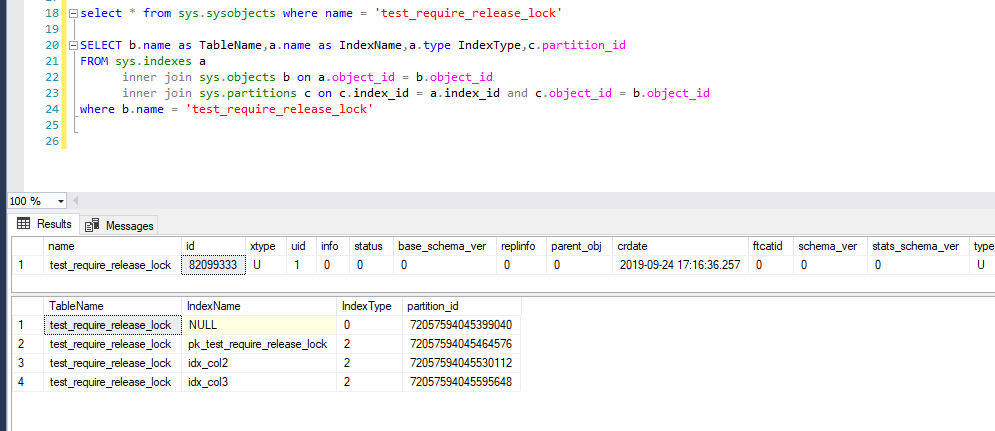
当前值得物理地址(RowHashId)
Profile跟踪日志
如下是profile跟踪出来的delete from test_require_release_lock where col2 = 'a999' and col3 = 'b999'语句执行过程中表级别锁的申请和释放
我只能说:这个case包括数据,是反复测试各种情况之后,最最简单的一种情况了,稍微复杂一点的情况,对于一行数据的删除,加解锁的过程至少要两屏才能显示出来。
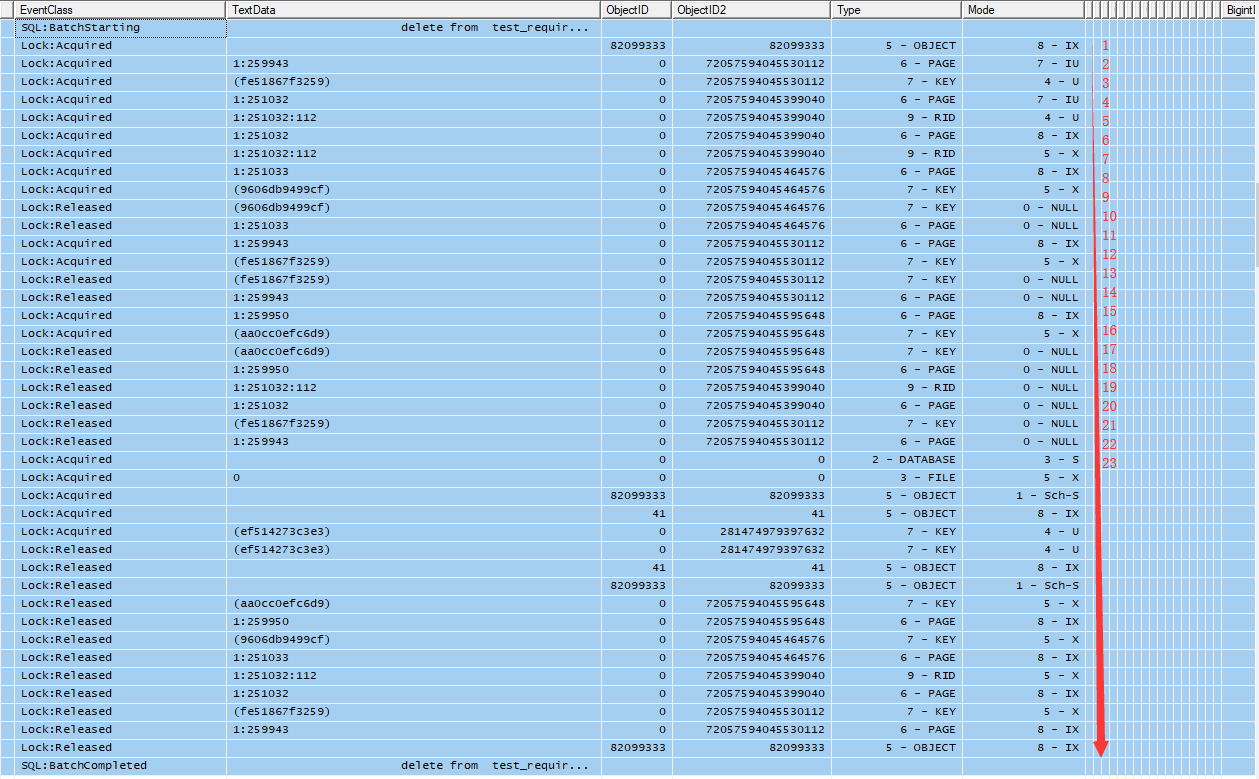
加解锁过程分析
这个过程可以大致分为3个阶段,仅仅执行一条数据删除的delete语句,就有37步之多,为了简化这个过程,这里只看删除过程中,数据/索引行上的加解锁信息,如图所示的前23步。
阶段1:根据where条件查找数据的物理Id,也即RID,这个过程是IU/U锁。虽然执行的是delete,此过程不删任何数据,只是根据条件,找到数据的RID
阶段2:依次删除数据行和索引行,也即依次删除RID,主键索引,多个索引键索引,这个过程涉及到第一步的IU/U锁转换IX/X以及新申请IX/X锁
阶段3:(删除完成)依次释放之前步骤申请尚未释放的锁
如下是profile中这个过程中每一步的说明
阶段1:
1,申请基表82099333上意向IX锁
2,申请目标行索引字段col2(fe51867f3259)所在page的IU锁
3,申请目标行索引字段col2(fe51867f3259)Key级别的U锁
4,申请目标所索引字段col2(fe51867f3259)对应的RID所在page的IU锁
5,申请目标所索引字段col2(fe51867f3259)对应的RID行的RID的U锁
阶段2
6,升级4申请的IU锁成IX锁
7,升级5申请的U锁成X锁 ***删除RID行,也即数据行
8,申请6(已经申请到的)RID对应的主键索引(9606db9499cf)所在page的IX锁
9,申请主键索引的key级别的X锁(9606db9499cf),***删除主键行
10,释放9申请的锁
11,释放8申请的锁
12,申请目标行索引字段col2 (fe51867f3259)所在page的IX锁
13,申请目标行索引字段col2(fe51867f3259)Key级别的X锁,***删除col2上的索引行
14,释放13申请的锁
15,释放12申请的锁
16,申请目标行索引字段(fe51867f3259)对应的Col3字段(aa0cc0efc6d9)索引所在page的IX锁
17,申请目标行索引字段(fe51867f3259)对应的Col3字段(aa0cc0efc6d9)索引Key级别的X锁,***删除col3上的索引行
阶段3
18,释放16申请的锁
19,释放17申请的锁
20,释放6申请的锁
21,释放7申请的锁
22,释放4申请的锁
23,释放5申请的锁
24~37 释放其它锁
从中可以看到,锁的申请的简化过程是,或者其规律是:
1,根据查询条件,依次申请查询字段所在Page以及字段key本身的IU/U锁,因为这个阶段是找数据(找到加IU/U),而不是直接上来就删数据,所以是IU/U锁
2,根据nocluster index 找到RID,从IU/U升级RID锁称IX/X,进行数据行的删除
3,依次删除主键索引,col2上的索引,col3上的索引,进行索引行的删除
4,依次释放加锁信息,此过程于加锁相反(先page再Key),依次释放KEY/RID和Page上的锁(先key再Page)
如果是聚集索引表,会用聚集索引Key提到RID,省略RID这一步的锁操作。
从这里可以看到,没有聚集索引的表,主键索引跟普通的非聚集索引并无二致,最终还是要使用RID来定位数据。
这里还能够得到另外一个结论:因为这里的主键索引是nonclustered的,因此该表还是数据堆表,既然是堆表,定位数据的还是RID,因此多了依次RID的锁维护动作
以上跟踪了一个最简单的delete执行过程中的加锁的步骤,其实情况可以更复杂:
1如果where条件用不到索引,
2如果where条件之一筛选出来的多行,继续用另外的条件筛选,
3如果使用聚集索引筛选,
4如果where条件筛选后仍旧有多行数据
5如果where条件无法命中任何一行
6如果采用多个非聚集索引筛选后merge结果
稍微复杂一点的情况,涉及到的锁都呈指数级增加,原本我以为很清楚sqlserver在执行delete操作的加锁过程,其实还有很多细节,没有注意到。
加解锁是一个复杂的过程,即便是单表,也会涉及不同的索引以及数据行,为此并不难理解,为什么对于单表,除了where条件不一致,为什么会出现死锁的原因。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号