

利用MySQL系统数据库做性能负载诊断

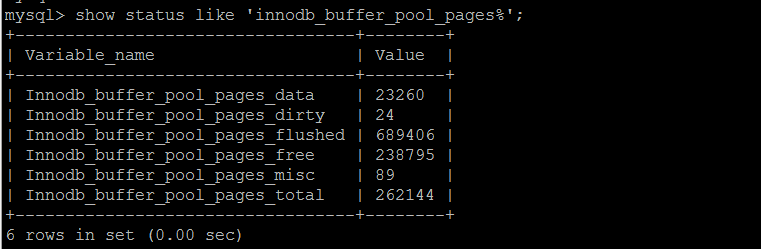
innodb_buffer_pool已占用内存的明细信息,可以按照库\表的维度来统计
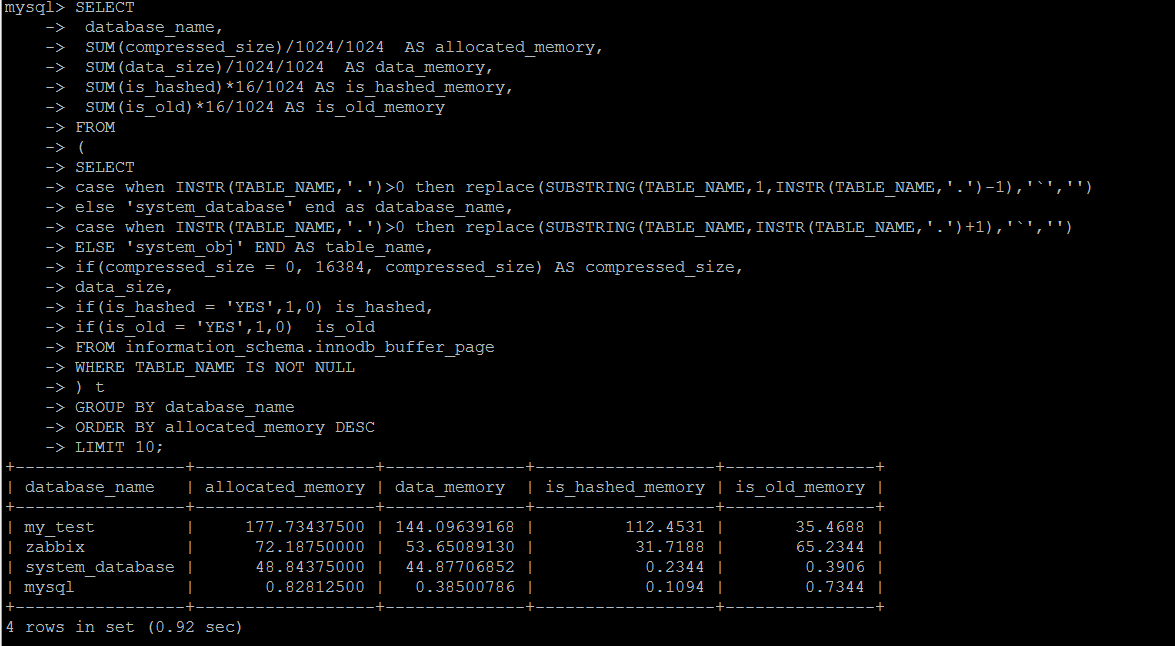

SET SESSION TRANSACTION ISOLATION LEVEL READ UNCOMMITTED ; SELECT database_name, SUM(compressed_size)/1024/1024 AS allocated_memory, SUM(data_size)/1024/1024 AS data_memory, SUM(is_hashed)*16/1024 AS is_hashed_memory, SUM(is_old)*16/1024 AS is_old_memory FROM ( SELECT case when INSTR(TABLE_NAME,'.')>0 then replace(SUBSTRING(TABLE_NAME,1,INSTR(TABLE_NAME,'.')-1),'`','') else 'system_database' end as database_name, case when INSTR(TABLE_NAME,'.')>0 then replace(SUBSTRING(TABLE_NAME,INSTR(TABLE_NAME,'.')+1),'`','') ELSE 'system_obj' END AS table_name, if(compressed_size = 0, 16384, compressed_size) AS compressed_size, data_size, if(is_hashed = 'YES',1,0) is_hashed, if(is_old = 'YES',1,0) is_old FROM information_schema.innodb_buffer_page WHERE TABLE_NAME IS NOT NULL ) t GROUP BY database_name ORDER BY allocated_memory DESC LIMIT 10;
缓存命中率统计及冷热数据变化
查询缓存命中率相关:
information_schema.innodb_buffer_pool_stats中的数据行数是跟buffer_pool_instance一致的
也就是每个一行数据来描述一个buffer_pool_instance,这里简单取和,缓存命中率取平局值的方式来统计
需要注意的是
1,modified_database_pages是实时的,就是内存中的脏页的数量,经checkpoint之后被刷新到磁盘,因此会时大时小。
2,pages_made_young和pages_not_made_young是累积的增加的,不会减少,就是MySQL实例截止到目前位置,做了多少pages_not_made_young和pages_not_made_young。
3,hit_rate在负载较低的情况下,没有参考意义,这一点很奇怪,低负载情况下,会发现很多buffer_pool的hit_rate是0。
反复测试的过程中突然意识到,hit_rate的计算,是不是以某个时间间隔为基准,统计这个时间段内请求的命中率,如果这一小段时间内没有请求,统计出来的hit_rate就是0。
4,与其他视图不通,information_schema.innodb_buffer_pool_stats中的数据会在服务重启后清零。
SELECT SUM(modified_database_pages) AS total_modified_database_pages, SUM(pages_made_young) AS total_pages_made_young, SUM(pages_not_made_young) AS total_pages_not_made_young, SUM(hit_rate)/COUNT(hit_rate)*1000 AS hit_rate FROM ( SELECT pool_id, pool_size, database_pages, old_database_pages, modified_database_pages, pages_made_young, pages_not_made_young, hit_rate FROM information_schema.innodb_buffer_pool_stats )t;
参考https://www.cnblogs.com/geaozhang/p/7276802.html这里对这pages_made_young和page_not_made_young,个人觉得解释的非常好。

这里低负载下的information_schema.innodb_buffer_pool_stats中的信息,hit_rate的值简直不可思议。
这个实例是4GB的内存,基本上没有访问量,hit_rate竟然出来好多值为0的情况。

相反在对当前实例做压力测试的时候,这个数据看起来才是正常的,包括modified_database_pages,pages_made_young,pages_not_made_young,hit_rate
这里用mysqlslap 做混合读写的压力测试
./mysqlslap -uroot -proot -h127.0.0.1 -P8000 --concurrency=100 --iterations=10000 --auto-generate-sql --auto-generate-sql-add-autoincrement --auto-generate-sql-load-type=mixed --engine=innodb --number-of-queries=10000
用python定时打印innodb_buffer_pool_stats
import pymysql import logging import time import decimal def execute_query(conn_dict,sql): conn = pymysql.connect(host=conn_dict['host'], port=conn_dict['port'], user=conn_dict['user'], passwd=conn_dict['password'], db=conn_dict['db']) cursor = conn.cursor(pymysql.cursors.DictCursor) cursor.execute(sql) list = cursor.fetchall() cursor.close() conn.close() return list def check_innodb_buffer_pool_stats(flag,conn_dict): result = execute_query(conn_dict, '''SELECT modified_database_pages, pages_made_young, pages_not_made_young, hit_rate FROM information_schema.innodb_buffer_pool_stats;''') if result: column = result[0].keys() current_row = '' if(flag<=0): for key in column: current_row += str(key) + " " print(current_row) for row in result: current_row = '' for key in row.values(): current_row += str(key) + " " print(current_row) if __name__ == '__main__': conn = {'host': '127.0.0.1', 'port': my_port, 'user': 'root', 'password': '***', 'db': 'mysql', 'charset': 'utf8mb4'} flag = 0 while 1>0: check_innodb_buffer_pool_stats(flag,conn) time.sleep(3) flag = 1
这样子看下来,这个统计还是比较正常的。
hit_rate的计算,是不是以某个时间间隔为基准,统计这个时间段内请求的命中率,如果这一小段时间内没有请求,统计出来的hit_rate就是0?
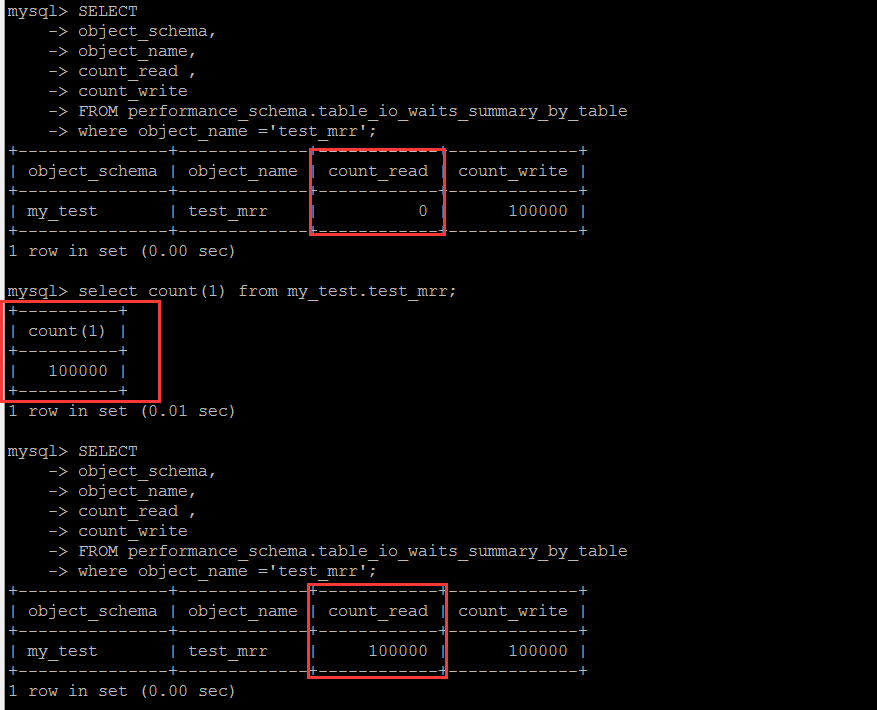
基于表的读写的行的次数统计,这是一个累计值,单纯的看这个值本身,个人觉得意义不大,需要定时收集计算差值,才具备参考意义。
以下按照库级别统计表的读写情况。


SET SESSION TRANSACTION ISOLATION LEVEL READ UNCOMMITTED ; SELECT database_name, IFNULL(cast(sum(total_read) as signed),0) AS total_read, IFNULL(cast(sum(total_written) as signed),0) AS total_written, IFNULL(cast(sum(total) AS SIGNED),0) AS total_read_written FROM ( SELECT substring(REPLACE(file, '@@datadir/', ''),1,instr(REPLACE(file, '@@datadir/', ''),'/')-1) AS database_name, count_read, case when instr(total_read,'KiB')>0 then replace(total_read,'KiB','')/1024 when instr(total_read,'MiB')>0 then replace(total_read,'MiB','')/1024 when instr(total_read,'GiB')>0 then replace(total_read,'GiB','')*1024 END AS total_read, case when instr(total_written,'KiB')>0 then replace(total_written,'KiB','')/1024 when instr(total_written,'MiB')>0 then replace(total_written,'MiB','') when instr(total_written,'GiB')>0 then replace(total_written,'GiB','')*1024 END AS total_written, case when instr(total,'KiB')>0 then replace(total,'KiB','')/1024 when instr(total,'MiB')>0 then replace(total,'MiB','') when instr(total,'GiB')>0 then replace(total,'GiB','')*1024 END AS total from sys.io_global_by_file_by_bytes WHERE FILE LIKE '%@@datadir%' AND instr(REPLACE(file, '@@datadir/', ''),'/')>0 )t GROUP BY database_name ORDER BY total_read_written DESC;
TOP SQL 统计
可以按照执行时间,阻塞时间,返回行数等等维度统计top sql。
另外可以按照时间筛选last_seen,可以统计最近某一段时间出现过的top sql
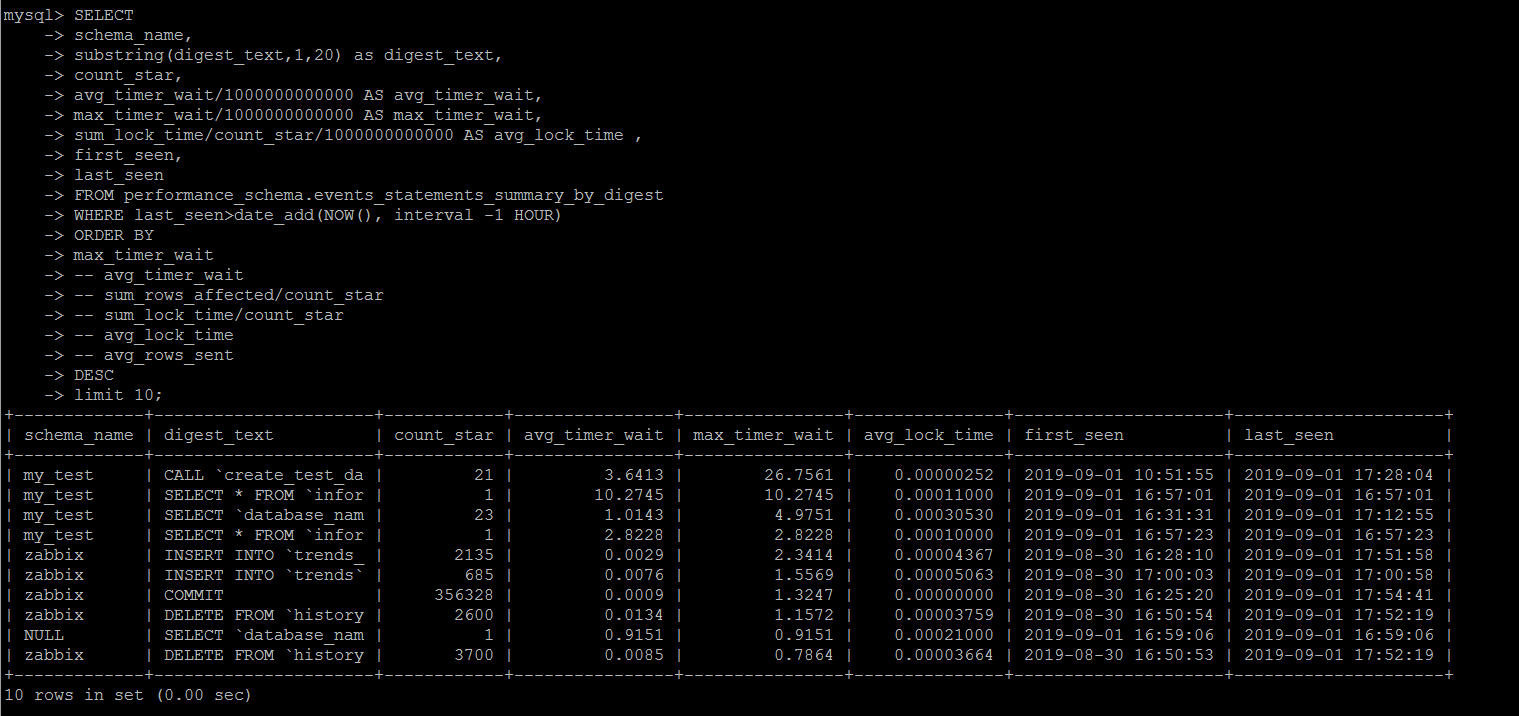
SET SESSION TRANSACTION ISOLATION LEVEL READ UNCOMMITTED ; SELECT schema_name, digest_text, count_star, avg_timer_wait/1000000000000 AS avg_timer_wait, max_timer_wait/1000000000000 AS max_timer_wait, sum_lock_time/count_star/1000000000000 AS avg_lock_time , sum_rows_affected/count_star AS avg_rows_affected, sum_rows_sent/count_star AS avg_rows_sent , sum_rows_examined/count_star AS avg_rows_examined, sum_created_tmp_disk_tables/count_star AS avg_create_tmp_disk_tables, sum_created_tmp_tables/count_star AS avg_create_tmp_tables, sum_select_full_join/count_star AS avg_select_full_join, sum_select_full_range_join/count_star AS avg_select_full_range_join, sum_select_range/count_star AS avg_select_range, sum_select_range_check/count_star AS avg_select_range, first_seen, last_seen FROM performance_schema.events_statements_summary_by_digest WHERE last_seen>date_add(NOW(), interval -1 HOUR) ORDER BY max_timer_wait -- avg_timer_wait -- sum_rows_affected/count_star -- sum_lock_time/count_star -- avg_lock_time -- avg_rows_sent DESC limit 10;
需要注意的是,这个统计是按照MySQL执行一个事务消耗的资源做统计的,而不是一个语句,笔者一开始懵逼了一阵子,举个简单的例子。
参考如下,这里是循环写个数据的一个存储过程,调用方式就是call create_test_data(N),写入N条测试数据。
比如call create_test_data(1000000)就是写入100W的测试数据,这个执行过程耗费了几分钟的时间,按照笔者的测试实例情况,avg_timer_wait的维度,绝对是一个TOP SQL。
但是在查询的时候,始终没有发现这个存储过程的调用被列为TOP SQL,后面尝试在存储过程内部加了一个事物,然后就顺利地收集到了整个TOP SQL.
因此说performance_schema.events_statements_summary_by_digest里面的统计,是基于事务的,而不是某一个批处理的执行时间的。
CREATE DEFINER=`root`@`%` PROCEDURE `create_test_data`( IN `loopcnt` INT ) LANGUAGE SQL NOT DETERMINISTIC CONTAINS SQL SQL SECURITY DEFINER COMMENT '' BEGIN -- START TRANSACTION; while loopcnt>0 do insert into test_mrr(rand_id,create_date) values (RAND()*100000000,now(6)); set loopcnt=loopcnt-1; end while; -- commit; END
另外一点比较有意思的是,这个系统表是为数不多的支持truncate的,当然它在内部,也是在不断收集的一个过程。
执行失败的SQL 统计
一直以为系统不会记录执行失败的\解析错误的SQL,比如想统计因为超时而执行失败的语句,后面才发现,这些信息,MySQL会完整地记录下来

这里会详细记录执行错误的语句,包括最终执行失败(超时之类的),语法错误,执行过程中产生了警告之类的语句。用sum_errors>0 or sum_warnings>0去performance_schema.events_statements_summary_by_digest筛选一下即可。
SET SESSION TRANSACTION ISOLATION LEVEL READ UNCOMMITTED ; select schema_name, digest_text, count_star, first_seen, last_seen from performance_schema.events_statements_summary_by_digest where sum_errors>0 or sum_warnings>0 order by last_seen desc;
Index使用情况统计
基于performance_schema.table_io_waits_summary_by_index_usage这个系统表,其统计的维度同样是“按照某个索引查询返回的行数的统计”。
可以按照哪些索引使用最多\最少等情况进行统计。
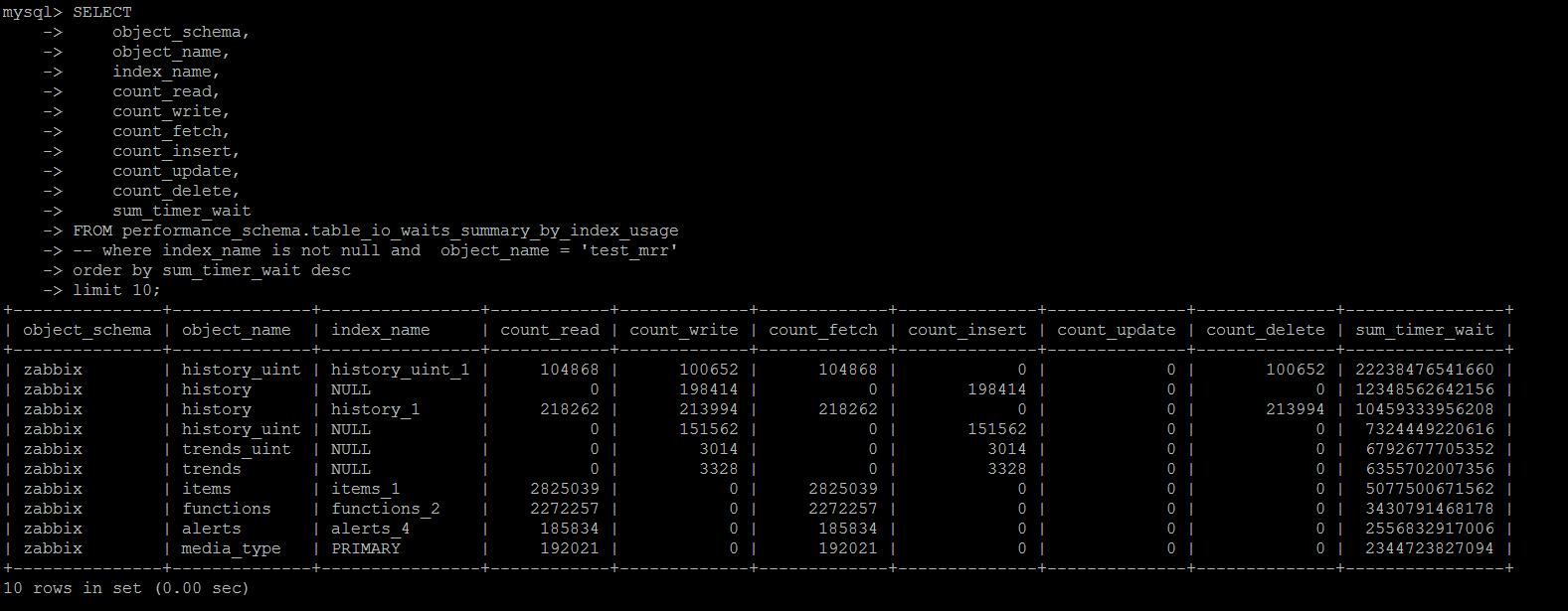
不过这个统计有一个给人潜在一个误区:
count_read,count_write,count_fetch,count_insert,count_update,count_delete统计了某个索引上使用到索引的情况下,受影响的行数,sum_timer_wait是累计在该索引上等待的时间。
如果使用到了该索引,但是没有数据受影响(就是没有DML语句的条件没有命中数据),将count_***不会统计进来,但是sum_timer_wait会统计进来
这就存在一个容易受到误导的地方,这个索引明明没有命中过很多次,但是却产生了大量的timer_wait,索引看到类似的信息,也不能贸然删除索引。
等待事件统计
MySQL数据库中的任何一个动作,都需要等待(一定的时间来完成),一共有超过1000个等待事件,分属不懂的类别,每个版本都不一样,且默认不是所有的等待事件都启用。
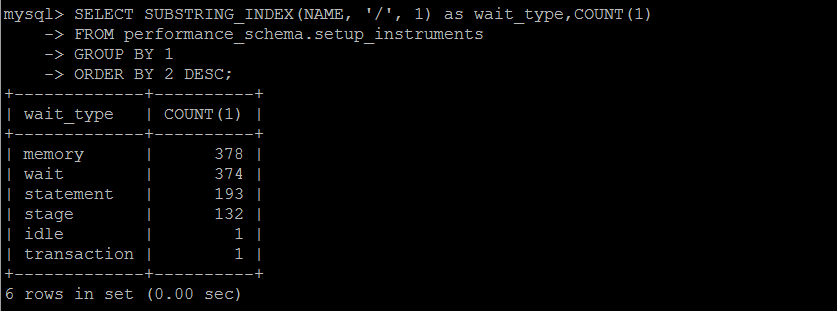
个人认为等待事件这个东西,仅做参考,不具备问题的诊断性,即便是再优化或者低负载的数据库,累计一段时间,某些事件仍旧会积累大量的等待事件。
这些事件的等待事件,不一定都是负面性的,比如事物的锁等待,是在并发执行过程中必然会生成的,这个等待事件的统计结果,也是累计的,单纯的看一个直接的值,不具备任何参考意义。
除非定期收集,做差值计算,根据实际情况,才具备参考意义。

SET SESSION TRANSACTION ISOLATION LEVEL READ UNCOMMITTED ; SELECT SUBSTRING_INDEX(NAME, '/', 1) as wait_type,COUNT(1) FROM performance_schema.setup_instruments GROUP BY 1 ORDER BY 2 DESC; SELECT event_name, count_star, sum_timer_wait FROM performance_schema.events_waits_summary_global_by_event_name WHERE event_name != 'idle' order by sum_timer_wait desc limit 100;
最后,需要注意的是,
1,MySQL提供的诸多的系统表(视图)中的数据,单纯的看这个值本身,因为它是一个累计值,个人觉得意义不大,尤其是avg_***,需要结合多方面的综合因素,做参考使用。
2,任何系统表的查询,都可能对系统性能的本身造成一定的影响,不要再对系统可能产生较大负面影响的情况下做数据的统计收集。
参考:
https://www.cnblogs.com/cchust/p/5061131.html
耐克的广告,竟然是这么的煽情
你能从一片空白里,看到可能吗?
有些人要看到证据,等有人做到了才敢出手。
但那些第一个行动的人,他们等过吗?
他们直接出手,不管有没有人做到过。
你能从一片空白里,看到可能吗?
不等别人,出手即证明。



【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· 从 HTTP 原因短语缺失研究 HTTP/2 和 HTTP/3 的设计差异
· AI与.NET技术实操系列:向量存储与相似性搜索在 .NET 中的实现
· 基于Microsoft.Extensions.AI核心库实现RAG应用
· Linux系列:如何用heaptrack跟踪.NET程序的非托管内存泄露
· 开发者必知的日志记录最佳实践
· TypeScript + Deepseek 打造卜卦网站:技术与玄学的结合
· Manus的开源复刻OpenManus初探
· AI 智能体引爆开源社区「GitHub 热点速览」
· 三行代码完成国际化适配,妙~啊~
· .NET Core 中如何实现缓存的预热?