
pyquery.PyQuery
PyQuery有三种初始化的方式
- 提供一个html的字符串
- 提供一个url,pyquery使用requests.get(url).text方法获取,获取html的字符串
- 提供一个本地文件路径PyQuery(filename=’’)
find()
PyQuery对象可以直接被调用,传入css选择器即可,也可以调用PyQuery的find()方法,实现相同的效果,两种方式的查找范围都是当前tag的所有子孙标签
children()
作用与find()相同,查找范围仅限于当前tag的子标签
parent()
返回直接祖先结点
parents()
返回所有祖先结点,仍然是PyQuery对象,若想对所有祖先结点做出筛选,在parents()返回的对象上继续使用css选择器即可
siblings()
返回兄弟结点,可以继续使用css选择器
items()
当想要遍历PyQuery对象时,调用items方法返回一个生成器
attr()
pq.attr(‘class’) 可以获取class属性
也可以使用pq.attr.class_ 有个下划线
如果选中多个元素调用attr只会返回第一个元素的attr
text()
获取内部文本信息,会忽略内部的标签,但是会保留内部标签的文本信息
对打印为下图的pyquery对象使用text()方法
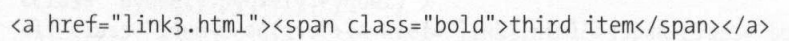
返回third item
<li class="item-0 active">12313<a href="link3.html"><span class="bold">third item</span></a></li>
会返回12313third item
如果css选择器选取了多个标签,text()方法会返回多个标签的文本信息
注:bs4中使用tag.string返回的文本信息同样会忽略掉内部标签保留文本信息,但是如果当前标签有文本信息,内部标签也有文本信息,会返回None;lxml的text()方法只会返回本标签的文本信息,内容标签及文本信息会全部被忽略。
html()
返回内部文本信息,不会忽略内部标签
选取多个元素时只会返回第一个的html内容
结点操作
addClass()和removeClass()
动态修改tag的class属性
attr(s1,s2)
修改s1属性为s2
text(s),html(s)
修改文本或者html为s
remove()
在tag上使用remove会删除掉当前结点
当选中多个元素时,会删除所有的元素
伪类选择器

第一个、最后一个,第二个,第三个及之后,偶数个,文本包含second的li结点。

