etree解析html
解析html字符串,将字符串传递给etree.HTML()方法:

解析html文件,传递文件路径和解析器:

xpath方法
html.xpath()方法参数为xpath规则,选取html中的元素,返回为封装好的element对象
注意:xpath按次序选择,次序从1开始
示例:
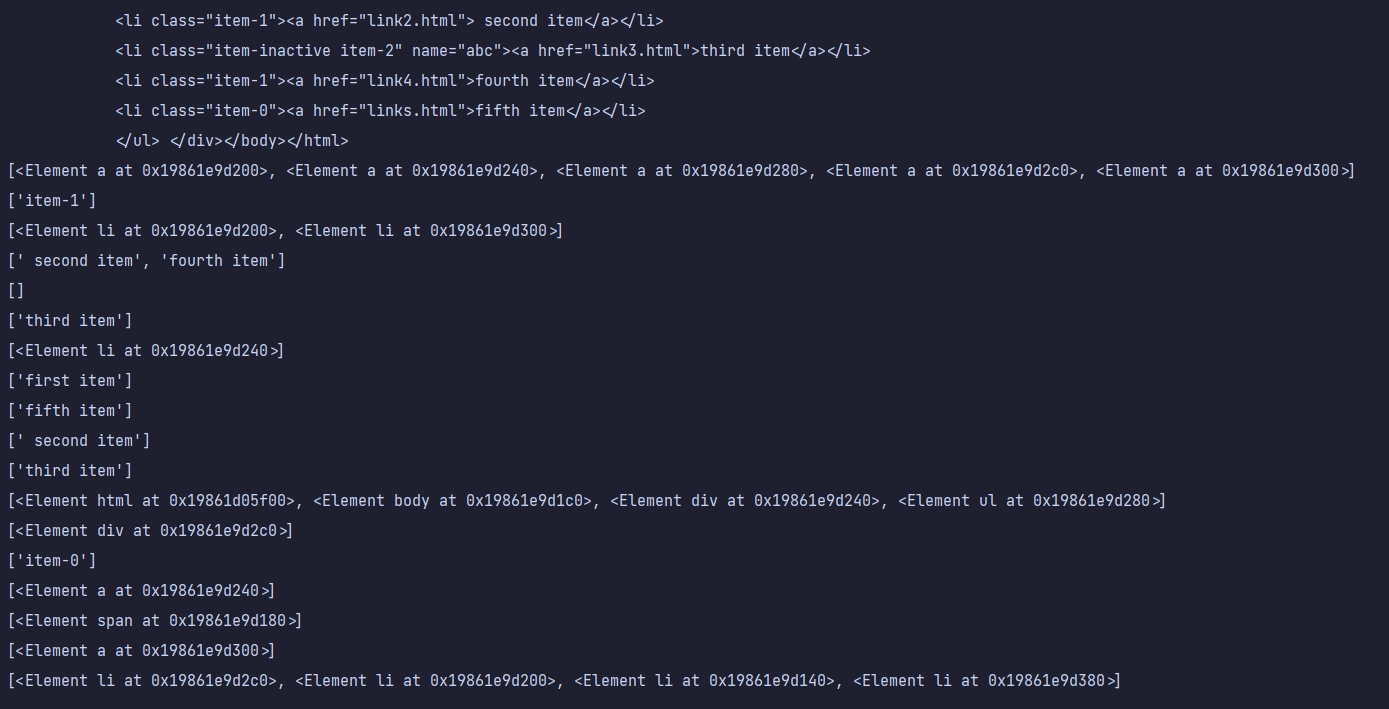
s = '''<div>
<ul>
<li class="item-0"><a href="link1.html"><span>first item</span></a></li>
<li class="item-1"><a href="link2.html"> second item</a></li>
<li class="item-inactive item-2" name="abc"><a href="link3.html">third item</a></li>
<li class="item-1"><a href="link4.html">fourth item</a></li>
<li class="item-0"><a href="links.html">fifth item</a></li>
</ul> '''
html = etree.HTML(s)
result = etree.tostring(html)
print(result.decode('utf-8'))
print(html.xpath('//li/a'))
# 特定节点父结果的class属性
print(html.xpath('//a[@href="link4.html"]/../@class'))
print(html.xpath('//li[@class="item-1"]'))
# 元素内容
print(html.xpath('//li[@class="item-1"]/a/text()'))
# 多值属性无法只用一个值来确定元素,需要使用contains内置方法
print(html.xpath('//li[@class="item-2"]'))
print(html.xpath('//li[contains(@class,"item-2")]/a/text()'))
# 多个属性确定一个元素用and连接
print(html.xpath('//li[contains(@class,"item-inactive") and @name="abc"]'))
# 按次序选取
print(html.xpath('//li[1]/a/span/text()'))
print(html.xpath('//li[last()]/a/text()'))
print(html.xpath('//li[position()<3]/a/text()'))
print(html.xpath('//li[last()-2]/a/text()'))
# 节点轴选取
# 祖先节点轴
print(html.xpath('//li[1]/ancestor::*'))
print(html.xpath('//li[1]/ancestor::div'))
# 属性轴
print(html.xpath('//li[1]/attribute::*'))
# 直接子节点轴
print(html.xpath('//li[1]/child::a[@href="link1.html"]'))
# 子孙节点轴
print(html.xpath('//li[1]/descendant::span'))
# 当前节点之后的所有节点轴
print(html.xpath('//li[1]/following::*[2]'))
# 当前节点之后的同级节点轴
print(html.xpath('//li[1]/following-sibling::*'))
结果如下: