Urllib
request
Urlopen
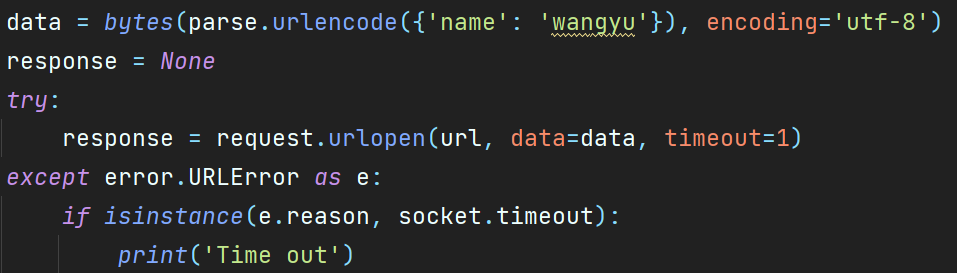
Urlopen()来访问一个url,额外参数data可以用来设置url请求中的参数,timeout用来设置超时
Request对象
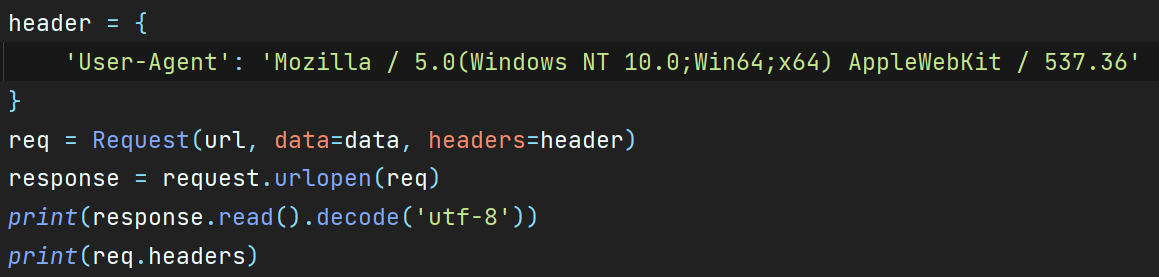
Urllib.request.Request对象,构建更强大的请求,可以设置请求头
Handler类
Urllib.request中还有各种handler类,借助handler使用build_opener()方法构建opener对象,使用opener.open()方法打开一个url,urlopen就是urllib库封闭好的opener对象,觉handler有

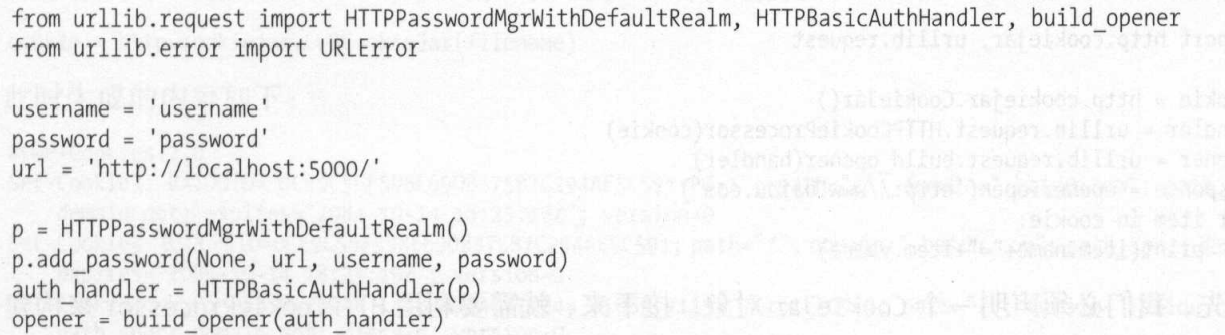
认证案例:
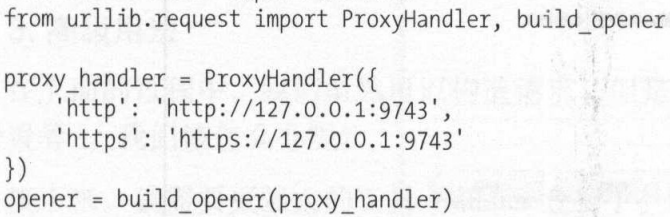
代理案例:
Cookie案例:
获取文本样式

存储为文件

可以对cookie对象使用load()方法读取本地的cookie文件
error
URLError
Error模块的基类,request模块的所有异常均可以使用这个类捕获,e.reason是产生异常的原因

HTTPError
URLError的子类,处理http异常,e.code返回状态码,e.reason同上,e.headers可以返回请求头
parse
Urlparse
参数有urlstring、scheme、allow_fragments
Scheme用于在url中没有协议部分时指定一个默认的类型,例如http或者https
Allow_fragments为false时忽略锚点部分
解析一个完整的url的每个部分

结果如下

Fragment为锚点用于定位
特殊情况:当url中不包含params和query时,fragment会被解析为path

结果ParseResult可能是一个namedtuple,可以使用索引的方式或者属性的方式获取内容

Urlunparse
Urlparse的对立方法,参数为一个可迭代对象,必须包含有url的6个部分,没有的部分可以用空字符串代替,不然会报错

结果如下:

Urlsplit
没有params部分的urlparse,params部分会合并到path部分、
Urlunsplit
类似于urlunparse方法
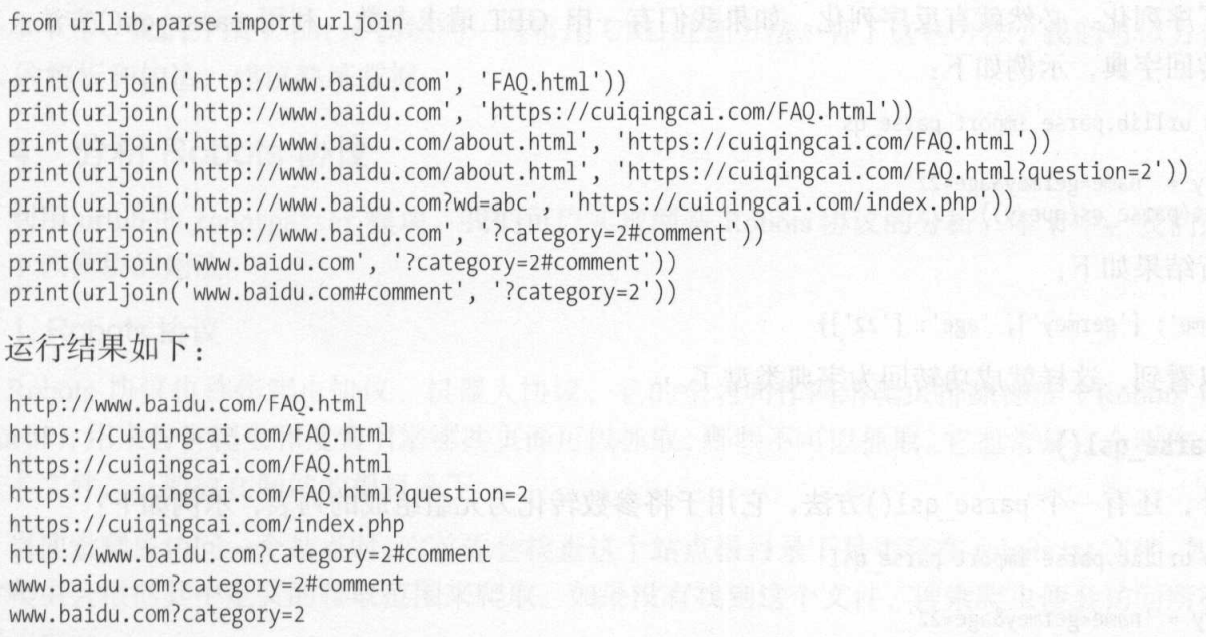
Urljoin
提供两个url参数分别为base_url和new_url,方法将分析base_url的scheme、netloc和path部分补全new_url缺失的部分,返回new_url
示例如下:
Urlencode
提供一个存储着query的dict,返回为get请求下的query序列样式

结果如下:

Parse_qs
反序列化get查询参数为dict

Parse_qsl
反序列化为元组组成的列表

Quote
将中文字符转化为url编码

结果如下:
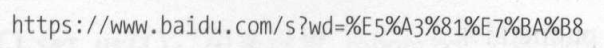
其实也可以直接向url中加入中文然后经quote转化
Unquote
将url编码后的结果进行还原

结果如下:

Robotparser
RobotFileParser(url=’’)
只需要传入robots.txt的url即可,当然也可先声明对象后使用set_url()设置,下一步必须使用read()进行读取和分析,之后可以使用can_fetch()来判断是否可以抓取
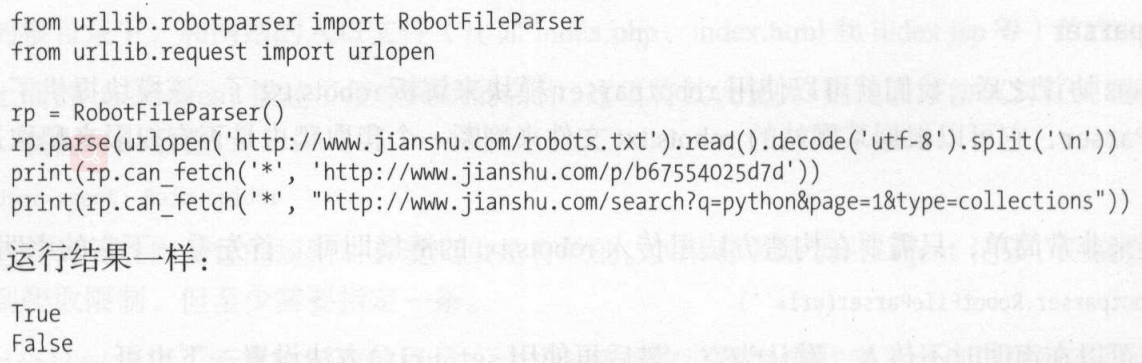
Parse()传入robots.txt的某些行来进行分析,之后同样可以使用can_fetch()判断
Can_fetch(),参数为user-agent和要抓取的url,返回true或false
Read样例:
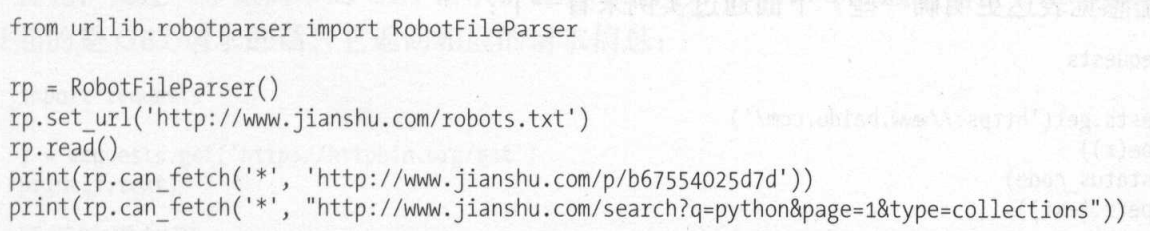
运行结果为True和False
Parse样例: