
一、图的存储结构
1.邻接矩阵
一维数组存储顶点,二维数组存储边
(1)无向图:

(2)有向图:
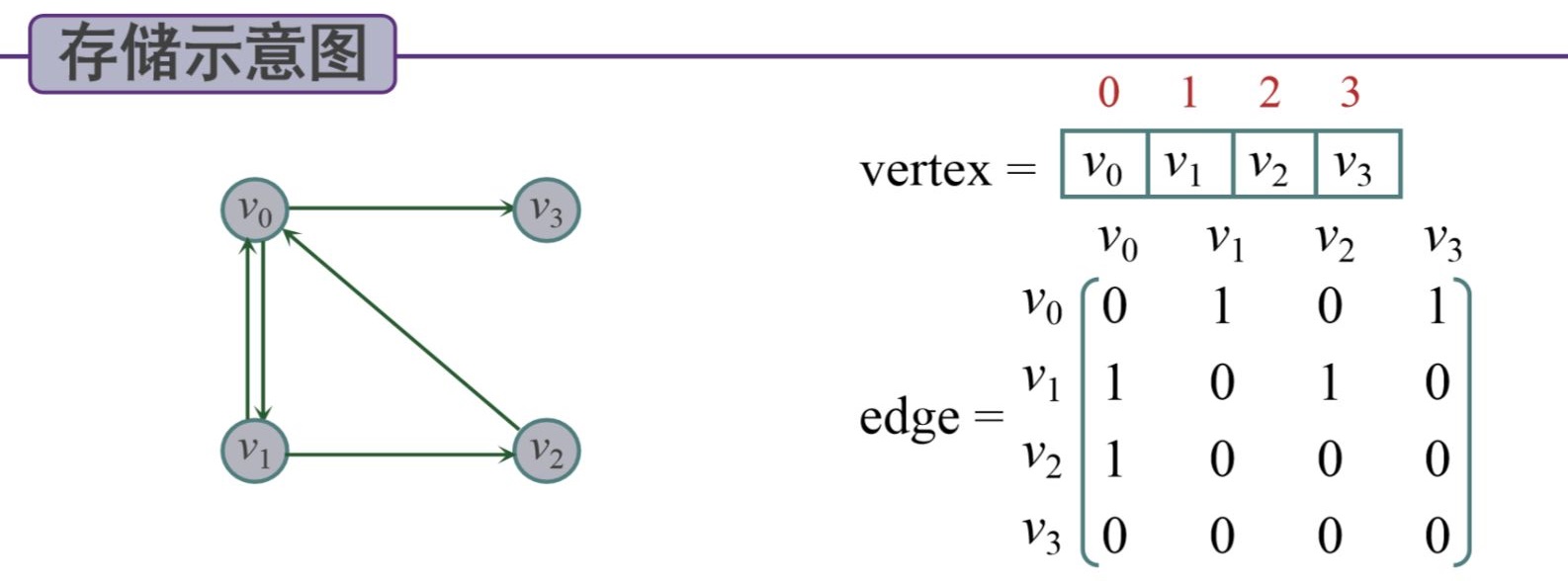
图的存储结构代码实现:
1 #define MaxSize 10 //假设图中最多顶点个数 2 typedef char DataType; //图中顶点的数据类型,假设为char型 3 typedef struct{ 4 DataType vertex[MaxSize]; //存放顶点的一维数组 5 int edge[MaxSize][MaxSize];//存放边的二维数组 6 int vertexNum,edgeNum; //图的顶点数和边数 7 }MGraph;
2.邻接表
顺序存储和链接存储相结合,类似于树的孩子表示法
(1)无向图:
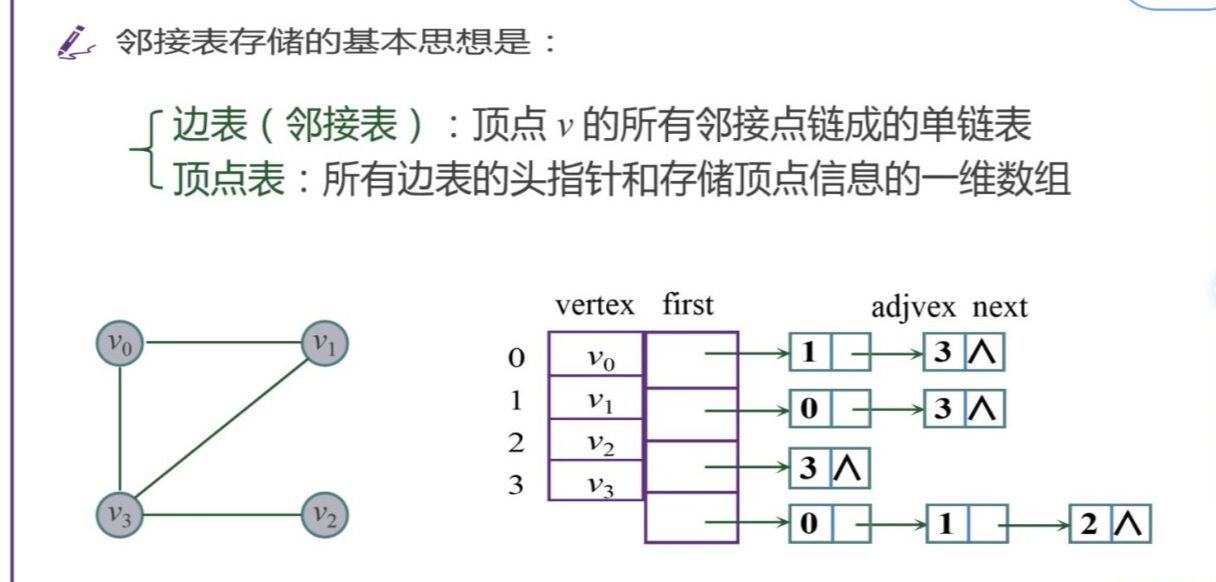
(2)有向图:
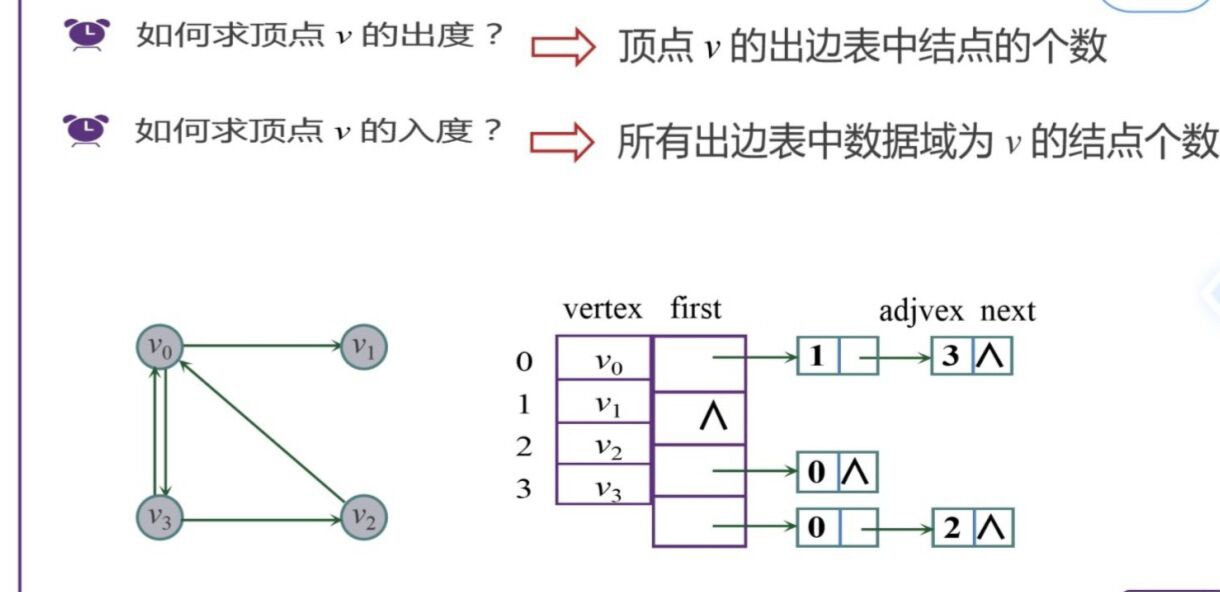
(3)带权图:

1 #define MaxSize 10 //图的最大顶点数 2 typedef char DataType; //定义图中顶点的数据类型,假设为char型 3 typedef struct EdgeNode{ //定义边表结点 4 int adjvex; 5 struct EdgeNode * next; 6 }EdgeNode; 7 typedef struct{ //定义顶点表结点 8 DataType vertex; 9 EdgeNode * first; 10 }VertexNode; 11 typedef struct{ //定义邻接表存储结构 12 VertexNode adjlist[MaxSize];//存放顶点表的数组 13 int vertexNum,edgeNum; //图的顶点数和边数 14 }ALGraph;
二、图的遍历
转载自30张图弄懂图的遍历方式
1.深度优先搜索——DFS
深度优先搜索是递归过程,带有回退操作,因此需要使用栈存储访问的路径信息。当访问到的当前顶点没有可以前进的邻接顶点时,需要进行出栈操作,将当前位置回退至出栈元素位置。
(1)无向图
(2)有向图
2.广度优先搜索——BFS
广度优先搜索类似于树的层次遍历,是按照一种由近及远的方式访问图的顶点。在进行广度优先搜索时需要使用队列存储顶点信息。
(1)无向图
(2)有向图
总结:图的遍历主要就是这两种遍历思想,深度优先搜索使用递归方式,需要栈结构辅助实现。广度优先搜索需要使用队列结构辅助实现。在遍历过程中可以看出,对于连通图,从图的任意一个顶点开始深度或广度优先遍历一定可以访问图中的所有顶点,但对于非连通图,从图的任意一个顶点开始深度或广度优先遍历并不能访问图中的所有顶点。

