MySQL中的基本SQL语句
标准SQL包含了4种基本的语句类别:
- DDL语句,数据定义语句,主要用来定义数据库,表名,字段,例如create,drop,alter.
- DML语句,数据操作语句,用来对数据记录的增删改查,还用来保证数据的一致性。主要有select,delete,insert,update语句。
- DCL语句,数据控制语句,用于控制不同数据对象访问级别的语句。定义了数据库、表、表、用户的访问权限和完全级别。常用的语句包括grant、revoke等
- TCL语句,事务控制语句,用来确保事务的特性。
CREATE TABLE建表语句
在介绍建表语句之前,先简单说明一下创建数据库的语句。


mysql> create database mytest; #创建数据库 Query OK, 1 row affected (0.00 sec) mysql> use mytest; #改变当前的数据库 Database changed mysql> select database(); #查看当前选中的数据库 +------------+ | database() | +------------+ | mytest | +------------+ 1 row in set (0.00 sec) mysql> select user(); #查看当前登录的用户 +----------------+ | user() | +----------------+ | root@localhost | +----------------+ 1 row in set (0.00 sec) mysql> show create database mytest; #查看创建数据库的语句,默认添加了字符集,会在字符集中介绍 +----------+-------------------------------------------------------------------+ | Database | Create Database | +----------+-------------------------------------------------------------------+ | mytest | CREATE DATABASE `mytest` /*!40100 DEFAULT CHARACTER SET latin1 */ | +----------+-------------------------------------------------------------------+ 1 row in set (0.00 sec) mysql> select version(); #查看当前数据库的版本 +------------+ | version() | +------------+ | 5.7.22-log | +------------+ 1 row in set (0.00 sec) mysql>
数据库创建之后,然后就是建表:
建表语句的作用就是在数据库创建一张二维表,因此在建表语句要指定每一个字段名(二维表中的列名),还有要指定对填入这些字段的数据的限制(约束条件),同时建表语句还可以指定这张表的字符集,以及之前规划好的索引等。 create table tb1( c1 int auto_increment primary key, c2 varchar(20) ); 创建了tb1表,表中有两列(两个字段), auto_increment: 指定字段c1为自增字段,mysql中一个表中只能有一个自增字段,且须为主键。 mysql> show create table tb1\G *************************** 1. row *************************** Table: tb1 Create Table: CREATE TABLE `tb1` ( `c1` int(11) NOT NULL AUTO_INCREMENT, `c2` varchar(20) DEFAULT NULL, PRIMARY KEY (`c1`) ) ENGINE=InnoDB DEFAULT CHARSET=latin1 1 row in set (0.00 sec) #查看建表语句,mysql会默认选择表的存储引擎和字符集 mysql> system ls /data/mysql/mytest/tb1.* /data/mysql/mytest/tb1.frm /data/mysql/mytest/tb1.ibd #在datadir对应的目录下面会生成对应的表结构文件tb1.frm,和数据文件tb1.ibd。
MySQL支持在建表时指定temporary参数,这样创建的表是临时表,临时表是基于会话级别的表。
#创建临时表,临时表使用show tables查不到其存在,但是可以查看表结构,也可以向临时表插入数据
mysql> create temporary table tb2(id int, info varchar(20)); Query OK, 0 rows affected (0.00 sec) mysql> show tables; +------------------+ | Tables_in_mytest | +------------------+ | tb1 | +------------------+ 1 row in set (0.00 sec) mysql> show create table tb2; +-------+--------------------------------------------------------------------------------------------------------------------------------------+ | Table | Create Table | +-------+--------------------------------------------------------------------------------------------------------------------------------------+ | tb2 | CREATE TEMPORARY TABLE `tb2` ( `id` int(11) DEFAULT NULL, `info` varchar(20) DEFAULT NULL ) ENGINE=InnoDB DEFAULT CHARSET=latin1 | +-------+--------------------------------------------------------------------------------------------------------------------------------------+ 1 row in set (0.00 sec) mysql> insert into tb2 values(1,"a"); Query OK, 1 row affected (0.00 sec)
#临时表的表结构存在于/tmp/目录下面
mysql> show variables like "tmpdir";
+---------------+-------+
| Variable_name | Value |
+---------------+-------+
| tmpdir | /tmp |
+---------------+-------+
1 row in set (0.01 sec)
[root@test3 tmp]# pwd
/tmp
[root@test3 tmp]# ls
#sql2966_99_0.frm
#临时表的数据文件在MySQL5.7之后由专门的文件存储
mysql> show variables like "innodb%temp%";
+----------------------------+-----------------------+
| Variable_name | Value |
+----------------------------+-----------------------+
| innodb_temp_data_file_path | ibtmp1:12M:autoextend |
+----------------------------+-----------------------+
1 row in set (0.00 sec)
#临时表有专门的存储引擎
mysql> show variables like "default%tmp%";
+----------------------------+--------+
| Variable_name | Value |
+----------------------------+--------+
| default_tmp_storage_engine | InnoDB |
+----------------------------+--------+
1 row in set (0.00 sec)
#临时表只对当前会话有效,当前会话断开,临时表会自动删除,在其余的会话也看不到临时表。
mysql> insert into tb2 values(1,"a");
ERROR 1146 (42S02): Table 'mytest.tb2' doesn't exist
mysql>
crate table语句还有很多参数可以使用,这些只是基本的用法,可以查看官方文档,也可以查看work bench中的介绍。
删除数据库和表
#删除数据库 mysql> drop database mytesti; Query OK, 0 rows affected (0.00 sec) #删除表,和表结构一起删除 mysql> drop table tb1; Query OK, 0 rows affected (0.02 sec) #删除表中的所有记录,但是不删除表结构 mysql> truncate tb4; Query OK, 0 rows affected (0.04 sec) #delete用来删除表中的数据 mysql> delete table tb2; ERROR 1064 (42000): You have an error in your SQL syntax; check the manual that corresponds to your MySQL server version for the right syntax to use near 'table tb2' at line 1 mysql> delete from tb2 where c = 1; Query OK, 0 rows affected (0.00 sec)
修改表结构
#创建如下表 CREATE TABLE IF NOT EXISTS tb2 ( id INT, NAME VARCHAR (20), email VARCHAR (50) ); #查看表的结构如下: mysql> desc tb2; +-------+-------------+------+-----+---------+-------+ | Field | Type | Null | Key | Default | Extra | +-------+-------------+------+-----+---------+-------+ | id | int(11) | YES | | NULL | | | NAME | varchar(20) | YES | | NULL | | | email | varchar(50) | YES | | NULL | | +-------+-------------+------+-----+---------+-------+ 3 rows in set (0.00 sec) #修改表名 // ALTER TABLE OLD_TB_NAME RENAME [TO] NEW_TB_NAME; mysql> alter table tb2 rename to tb3; Query OK, 0 rows affected (0.00 sec) // TO可以省略 mysql> alter table tb3 rename tb2; Query OK, 0 rows affected (0.00 sec)
#修改字段数据类型(把id字段的int类型修改为varchar类型)
// ALTER TABLE TBNAME MODIFY 字段名 新属性
ALTER TABLE tb2 MODIFY id VARCHAR(10);
mysql> desc tb2;
+-------+-------------+------+-----+---------+-------+
| Field | Type | Null | Key | Default | Extra |
+-------+-------------+------+-----+---------+-------+
| id | varchar(10) | YES | | NULL | |
| NAME | varchar(20) | YES | | NULL | |
| email | varchar(50) | YES | | NULL | |
+-------+-------------+------+-----+---------+-------+
3 rows in set (0.00 sec)
#修改字段名 (把上面的id字段名修改为user_id)
ALTER TABLE TBNAME CHANGE 旧字段名 新字段名 约束条件;
#需要注意的是这种方法不仅可以修改字段名,还可以修改字段的数据类型。
ALTER TABLE tb2 change id user_id varchar(10);
#增加字段
//ALTER TABLE 表名 ADD 新字段名 date FIRST|AFTER 字段A名。 first表示新加的字段在A的前面,after表示在A的后面。
ALTER TABLE tb2 ADD birth date; #默认的新增字段是在最后插入的。
mysql> desc tb2;
+---------+-------------+------+-----+---------+-------+
| Field | Type | Null | Key | Default | Extra |
+---------+-------------+------+-----+---------+-------+
| user_id | varchar(10) | YES | | NULL | |
| NAME | varchar(20) | YES | | NULL | |
| email | varchar(50) | YES | | NULL | |
| birth | date | YES | | NULL | |
+---------+-------------+------+-----+---------+-------+
4 rows in set (0.00 sec)
#删除字段
//ALTER TABLE 表名 DROP 字段名;
ALTER TABLE tb2 DROP user_id;
#字段排序:
ALTER TABLE TBNAME MODIFY 字段1 数据类型 FIRST|AFTER 字段2.
#更改表的存储引擎:
ALTER TABLE 表名 engine = "存储引擎名"
#删除外键
ALTER TABLE 表名 FOREIGN KEY 外键别名。
insert插入数据
insert用于向表中插入数据。
#默认插入所有的字段 insert into tb2 values(1,"a"); #插入指定的字段 insert into tb2(id) values("3"); #一次插入多个数值 insert into tb2 values(4,"c"),(5,"d"),(6,"e"); mysql> select * from tb2; +------+------+ | id | NAME | +------+------+ | 1 | a | | 3 | NULL | | 4 | c | | 5 | d | | 6 | e | +------+------+ 5 rows in set (0.00 sec) mysql>
update更新数据
update更新语句一般于where条件句联合使用。
mysql> update tb2 set name = "b" where id =3; Query OK, 1 row affected (0.02 sec) Rows matched: 1 Changed: 1 Warnings: 0 #如果不使用where条件语句限制,则更新表中所有的行
select查询
在查询之前先导入MySQL官方提供的employeeso库数据。
下载地址:https://github.com/datacharmer/test_db/archive/master.zip
方法:直接下载zip压缩包,然后直接导入employees.sql文件即可
导入的表,各个表之间的关系如下:
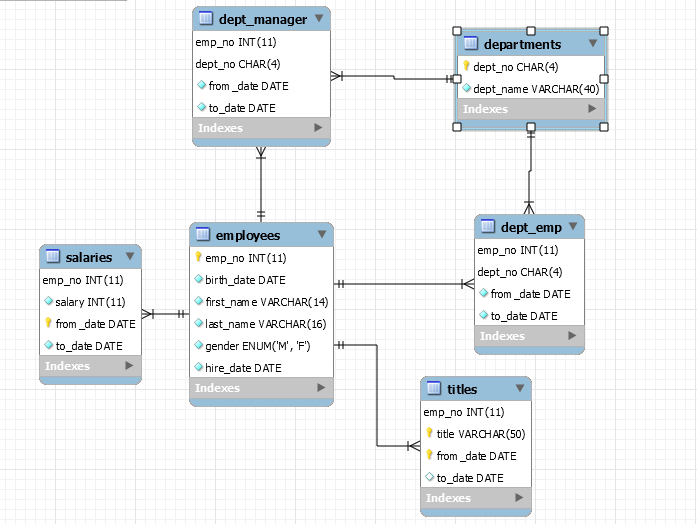
单表查询
mysql> select * from employees limit 1; +--------+------------+------------+-----------+--------+------------+ | emp_no | birth_date | first_name | last_name | gender | hire_date | +--------+------------+------------+-----------+--------+------------+ | 10001 | 1953-09-02 | Georgi | Facello | M | 1986-06-26 | +--------+------------+------------+-----------+--------+------------+ 1 row in set (0.00 sec) mysql> select emp_no, concat(first_name, " ", last_name) as full_name, gender from employees limit 1; +--------+----------------+--------+ | emp_no | full_name | gender | +--------+----------------+--------+ | 10001 | Georgi Facello | M | +--------+----------------+--------+ 1 row in set (0.01 sec) #查询可以使用*号代替表中所有的字段,也可以使用对应字段的字符,只查询出对应的要查询的字段。 #concat函数,就是连接字符串,在这里和as结合,连接了两个字段,并且重命名为full_name。
MySQL中有许多内嵌的函数可以调用,详细的函数列表参照:https://dev.mysql.com/doc/refman/5.7/en/string-functions.html 可以使用Google浏览器打开,可以翻译为中文!
单表查询和一些条件语句结合:
查看表中记录的数量
mysql> select count(*) from employees; +----------+ | count(*) | +----------+ | 300024 | +----------+ 1 row in set (0.53 sec)
使用order by语句按照某字段排序:
#默认是按照正序排列 mysql> select * from employees order by emp_no limit 3; +--------+------------+------------+-----------+--------+------------+ | emp_no | birth_date | first_name | last_name | gender | hire_date | +--------+------------+------------+-----------+--------+------------+ | 10001 | 1953-09-02 | Georgi | Facello | M | 1986-06-26 | | 10002 | 1964-06-02 | Bezalel | Simmel | F | 1985-11-21 | | 10003 | 1959-12-03 | Parto | Bamford | M | 1986-08-28 | +--------+------------+------------+-----------+--------+------------+ 3 rows in set (0.00 sec) #加入关键字按照倒序排列 mysql> select * from employees order by emp_no desc limit 3; +--------+------------+------------+-----------+--------+------------+ | emp_no | birth_date | first_name | last_name | gender | hire_date | +--------+------------+------------+-----------+--------+------------+ | 499999 | 1958-05-01 | Sachin | Tsukuda | M | 1997-11-30 | | 499998 | 1956-09-05 | Patricia | Breugel | M | 1993-10-13 | | 499997 | 1961-08-03 | Berhard | Lenart | M | 1986-04-21 | +--------+------------+------------+-----------+--------+------------+ 3 rows in set (0.00 sec)
使用where条件语句:
#查找部门经理表中,员工号为d006的记录 mysql> select * from dept_manager where dept_no = "d006"; +--------+---------+------------+------------+ | emp_no | dept_no | from_date | to_date | +--------+---------+------------+------------+ | 110725 | d006 | 1985-01-01 | 1989-05-06 | | 110765 | d006 | 1989-05-06 | 1991-09-12 | | 110800 | d006 | 1991-09-12 | 1994-06-28 | | 110854 | d006 | 1994-06-28 | 9999-01-01 | +--------+---------+------------+------------+ 4 rows in set (0.06 sec) #where可以使用大于,小于,不等于 SELECT * FROM dept_manager where dept_no > "d006"; SELECT * FROM dept_manager where dept_no < "d004"; SELECT * FROM dept_manager where dept_no <> "d006"; #where语句也可以使用in关键字 mysql> select * from dept_manager where dept_no in ("d006", "d001"); +--------+---------+------------+------------+ | emp_no | dept_no | from_date | to_date | +--------+---------+------------+------------+ | 110022 | d001 | 1985-01-01 | 1991-10-01 | | 110039 | d001 | 1991-10-01 | 9999-01-01 | | 110725 | d006 | 1985-01-01 | 1989-05-06 | | 110765 | d006 | 1989-05-06 | 1991-09-12 | | 110800 | d006 | 1991-09-12 | 1994-06-28 | | 110854 | d006 | 1994-06-28 | 9999-01-01 | +--------+---------+------------+------------+ 6 rows in set (0.00 sec) #使用and关键字(与关系) mysql> select * from dept_manager where dept_no = "d006" and to_date = "9999-01-01"; +--------+---------+------------+------------+ | emp_no | dept_no | from_date | to_date | +--------+---------+------------+------------+ | 110854 | d006 | 1994-06-28 | 9999-01-01 | +--------+---------+------------+------------+ 1 row in set (0.00 sec) #使用or关键字(或关系) mysql> select * from dept_manager where dept_no = "d006" or to_date = "9999-01-01"; +--------+---------+------------+------------+ | emp_no | dept_no | from_date | to_date | +--------+---------+------------+------------+ | 110039 | d001 | 1991-10-01 | 9999-01-01 | | 110114 | d002 | 1989-12-17 | 9999-01-01 | | 110228 | d003 | 1992-03-21 | 9999-01-01 | | 110420 | d004 | 1996-08-30 | 9999-01-01 | | 110567 | d005 | 1992-04-25 | 9999-01-01 | | 110725 | d006 | 1985-01-01 | 1989-05-06 | | 110765 | d006 | 1989-05-06 | 1991-09-12 | | 110800 | d006 | 1991-09-12 | 1994-06-28 | | 110854 | d006 | 1994-06-28 | 9999-01-01 | | 111133 | d007 | 1991-03-07 | 9999-01-01 | | 111534 | d008 | 1991-04-08 | 9999-01-01 | | 111939 | d009 | 1996-01-03 | 9999-01-01 | +--------+---------+------------+------------+ 12 rows in set (0.00 sec) #使用between and关键字,在两个数值之间 mysql> select * from dept_manager where dept_no between "d003" and "d004"; +--------+---------+------------+------------+ | emp_no | dept_no | from_date | to_date | +--------+---------+------------+------------+ | 110183 | d003 | 1985-01-01 | 1992-03-21 | | 110228 | d003 | 1992-03-21 | 9999-01-01 | | 110303 | d004 | 1985-01-01 | 1988-09-09 | | 110344 | d004 | 1988-09-09 | 1992-08-02 | | 110386 | d004 | 1992-08-02 | 1996-08-30 | | 110420 | d004 | 1996-08-30 | 9999-01-01 | +--------+---------+------------+------------+ 6 rows in set (0.00 sec) #使用like关键字,其中“%”代表任意字符,“_”代表一个字符。 mysql> select * from dept_manager where dept_no like "d%4"; +--------+---------+------------+------------+ | emp_no | dept_no | from_date | to_date | +--------+---------+------------+------------+ | 110303 | d004 | 1985-01-01 | 1988-09-09 | | 110344 | d004 | 1988-09-09 | 1992-08-02 | | 110386 | d004 | 1992-08-02 | 1996-08-30 | | 110420 | d004 | 1996-08-30 | 9999-01-01 | +--------+---------+------------+------------+ 4 rows in set (0.00 sec) mysql> select * from dept_manager where dept_no like "d0_4"; +--------+---------+------------+------------+ | emp_no | dept_no | from_date | to_date | +--------+---------+------------+------------+ | 110303 | d004 | 1985-01-01 | 1988-09-09 | | 110344 | d004 | 1988-09-09 | 1992-08-02 | | 110386 | d004 | 1992-08-02 | 1996-08-30 | | 110420 | d004 | 1996-08-30 | 9999-01-01 | +--------+---------+------------+------------+ 4 rows in set (0.00 sec) mysql> select * from dept_manager where dept_no like "d_4"; Empty set (0.00 sec) #去重复, mysql> select dept_no from dept_manager limit 5; +---------+ | dept_no | +---------+ | d001 | | d001 | | d002 | | d002 | | d003 | +---------+ 5 rows in set (0.00 sec) mysql> select distinct dept_no from dept_manager limit 5; +---------+ | dept_no | +---------+ | d001 | | d002 | | d003 | | d004 | | d005 | +---------+ 5 rows in set (0.00 sec)
查询分组:
#一个报错:
mysql> select emp_no, dept_no from dept_manager group by dept_no; ERROR 1055 (42000): Expression #1 of SELECT list is not in GROUP BY clause and contains nonaggregated column 'employees.dept_manager.emp_no' which is not functionally dependent on columns in GROUP BY clause; this is incompatible with sql_mode=only_full_group_by #解决,更改sql_mode; http://www.ywnds.com/?p=8184
#按照部门分组 mysql> select emp_no, dept_no from dept_manager group by dept_no; +--------+---------+ | emp_no | dept_no | +--------+---------+ | 110022 | d001 | | 110085 | d002 | | 110183 | d003 | | 110303 | d004 | | 110511 | d005 | | 110725 | d006 | | 111035 | d007 | | 111400 | d008 | | 111692 | d009 | +--------+---------+ 9 rows in set (0.10 sec) #求出每个分组的元素数量 mysql> select count(emp_no), dept_no from dept_manager group by dept_no; +---------------+---------+ | count(emp_no) | dept_no | +---------------+---------+ | 2 | d001 | | 2 | d002 | | 2 | d003 | | 4 | d004 | | 2 | d005 | | 4 | d006 | | 2 | d007 | | 2 | d008 | | 4 | d009 | +---------------+---------+ 9 rows in set (0.00 sec) #列出每一个分组的元素 mysql> select group_concat(emp_no), dept_no from dept_manager group by dept_no; +-----------------------------+---------+ | group_concat(emp_no) | dept_no | +-----------------------------+---------+ | 110022,110039 | d001 | | 110085,110114 | d002 | | 110183,110228 | d003 | | 110303,110344,110386,110420 | d004 | | 110511,110567 | d005 | | 110725,110765,110800,110854 | d006 | | 111035,111133 | d007 | | 111400,111534 | d008 | | 111692,111784,111877,111939 | d009 | +-----------------------------+---------+ 9 rows in set (0.00 sec) mysql>
group by聚合函数,加上with rollup函数,会统计一个总的结果在最后一行。
mysql> select count(emp_no), dept_no from dept_manager group by dept_no with rollup; +---------------+---------+ | count(emp_no) | dept_no | +---------------+---------+ | 2 | d001 | | 2 | d002 | | 2 | d003 | | 4 | d004 | | 2 | d005 | | 4 | d006 | | 2 | d007 | | 2 | d008 | | 4 | d009 | | 24 | NULL | +---------------+---------+ 10 rows in set (0.00 sec)
#加上having条件语句
mysql> select count(emp_no), dept_no from dept_manager group by dept_no with rollup having dept_no > "d006";
+---------------+---------+
| count(emp_no) | dept_no |
+---------------+---------+
| 2 | d007 |
| 2 | d008 |
| 4 | d009 |
+---------------+---------+
3 rows in set (0.00 sec)
查询某个表的数据大小以及索引大小,以及数据和索引的总大小
USE information_schema; select b.TABLE_NAME, b.ddata, b.dindex, sum(b.ddata)+SUM(b.dindex) as total from ( SELECT TABLE_NAME, TRUNCATE (Data_length / 1024 / 1024, 2) AS ddata, TRUNCATE (INDEX_LENGTH / 1024 / 1024, 2) AS dindex FROM TABLES where TABLE_NAME = 't_hk_stock_news') as b; 执行结果如下 +-----------------+--------+--------+--------+ | TABLE_NAME | ddata | dindex | total | +-----------------+--------+--------+--------+ | t_hk_stock_news | 290.00 | 278.00 | 568.00 | +-----------------+--------+--------+--------+ 1 row in set (0.00 sec)
#这里面有个构建的新字段,然后再根据构建的新字段求二者的和。
联合查询
联合查询分为:内连接和外连接,其中外连接又包含左连接和右连接。
内连接:
需求1:求出经理人员的工号,姓名,性别,部门代号(暂时不考虑部门名称)。(经理就是dept_manager中的员工)
#使用where条件语句联合两张表查询 SELECT e.emp_no, concat( e.first_name, " ", e.last_name ), e.gender, dp.dept_no FROM employees AS e, dept_manager AS dp WHERE dp.emp_no = e.emp_no; #采用内联合查询的方法 SELECT e.emp_no, concat( e.first_name, " ", e.last_name ), e.gender, dp.dept_no FROM employees AS e INNER JOIN dept_manager AS dp ON dp.emp_no = e.emp_no;
由上面这个查询可以体会一下的连接的含义: 把两张或多张表中,相同的字段联合起来的的查询,当值相等时,就会查询出其结果。
上面的查询中,我们再加入一张表,把部门的代号换为部门名称。
SELECT e.emp_no, concat( e.first_name, " ", e.last_name ), e.gender, dp.dept_no, dep.dept_name FROM employees AS e, dept_manager AS dp, departments AS dep WHERE dp.emp_no = e.emp_no AND dp.dept_no = dep.dept_no; #使用inner联合查询的方式 SELECT e.emp_no, concat( e.first_name, " ", e.last_name ), e.gender, dp.dept_no, dep.dept_name FROM employees AS e INNER JOIN dept_manager AS dp ON dp.emp_no = e.emp_no INNER JOIN departments AS dep ON dp.dept_no = dep.dept_no;
外连接: 外连接分为左连接和右连接,这两个连接的方式是一样的,不同的是刷选数据的方式。
语法格式如下:
SELECT 字段名 FROM 表名1 LEFT| RIGHT 表名2 ON 表名1.字段名1 = 表名2.字段名2;
有以下的实例,我们来理解以下左查询和右查询:
mysql> select * from test1; +------+ | a | +------+ | 1 | | 2 | | 3 | | 4 | +------+ 4 rows in set (0.00 sec) mysql> select * from test2; +------+------+ | c | d | +------+------+ | 1 | a | | 2 | b | | c | d | +------+------+ 3 rows in set (0.00 sec) #左查询的结果,左边的数据会全部显示,对应右表若没有数据则为NULL mysql> select test1.a, test2.c, test2.d from test1 left join test2 on test1.a = test2.c; +------+------+------+ | a | c | d | +------+------+------+ | 1 | 1 | a | | 2 | 2 | b | | 3 | NULL | NULL | | 4 | NULL | NULL | +------+------+------+ 4 rows in set, 4 warnings (0.00 sec) #右查询的结果,有表的数据会全部显示,对应的左表数据若是没有则为NULL。 mysql> select test1.a, test2.c, test2.d from test1 right join test2 on test1.a = test2.c; +------+------+------+ | a | c | d | +------+------+------+ | 1 | 1 | a | | 2 | 2 | b | | NULL | c | d | +------+------+------+ 3 rows in set, 4 warnings (0.00 sec) mysql>
在上面的employyes库中表关系图中,我们来做一个如下检索。
- 要求求出普通员工的员工号,姓名(用一个字段显示),性别,最近的薪水,最近的一个部门,和最近的一个title。
(因为在titles,salries,dept_emp表中,同一个工号员工有多条数据,因此我们可以根据时间,选择最近的员工)。
上面的需求一步一步拆解:先求出普通员工的工号,姓名,性别和部门的代号,这个只涉及两张表的查询:
SELECT e.emp_no, concat( e.first_name, " ", e.last_name ) AS full_name, e.gender, dp.dept_no FROM employees AS e LEFT JOIN dept_manager AS dp ON dp.emp_no = e.emp_no WHERE dp.dept_no IS NULL; #这个表查询处理有30万条记录,因此会比较慢,暂时不考虑性能,为了验证这个结果,可以设置where条件dp.dept_no IS NOT NULL,这样查出来的结果是经理的个人信息,恰好是24条。
再求出员工的最近的薪水:
看一下薪水表的数据:
mysql> select * from salaries where emp_no = "10002"; +--------+--------+------------+------------+ | emp_no | salary | from_date | to_date | +--------+--------+------------+------------+ | 10002 | 65828 | 1996-08-03 | 1997-08-03 | | 10002 | 65909 | 1997-08-03 | 1998-08-03 | | 10002 | 67534 | 1998-08-03 | 1999-08-03 | | 10002 | 69366 | 1999-08-03 | 2000-08-02 | | 10002 | 71963 | 2000-08-02 | 2001-08-02 | | 10002 | 72527 | 2001-08-02 | 9999-01-01 | +--------+--------+------------+------------+ 6 rows in set (0.00 sec) #我们要查询得到的是这个表中,salary最近的那个值,也就是时间距现在最近,需要注意的是,时间最近的薪水不一定是最高的! mysql> select emp_no, max(from_date) from salaries group by emp_no limit 4; +--------+----------------+ | emp_no | max(from_date) | +--------+----------------+ | 10001 | 2002-06-22 | | 10002 | 2001-08-02 | | 10003 | 2001-12-01 | | 10004 | 2001-11-27 | +--------+----------------+ 4 rows in set (0.11 sec) #这样我们得出的是,每个员工的最近的from_date,然后根据这两个条件就可以求出员工最近的薪水。(这张表用的是复合索引,暂时先不提)
#SQL语句如下
SELECT
a.emp_no, a.salary
from salaries a
WHERE a.from_date = (SELECT max(b.from_date) from salaries b WHERE a.emp_no = b.emp_no GROUP BY b.emp_no);
#我们要的是员工的最近的薪水表,而不是最高的薪水表!
按照上面的方法我们可以求出,员工距离现在最近的部门代号,和title。
title的SQL语句仿照上面写就可以了,但是员工的部门职称,需要再联合一张表查询,结果如下:
SELECT a.emp_no, a.dept_no, dp.dept_name FROM dept_emp AS a, departments AS dp WHERE #WHERE条件句是一个and语句 from_date = ( SELECT #and语句的第一个条件是子查询, max(from_date) FROM dept_emp AS b WHERE a.emp_no = b.emp_no GROUP BY emp_no ) AND dp.dept_no = a.dept_no #and语句的第二个条件语句 ORDER BY a.emp_no; #查询的结果就是每个员工的最新职称
把求出的三个查询和最上面的普通员工信息的查询联合起来就是我们要得道的SQL查询:
SELECT e.emp_no, CONCAT(e.first_name, ' ', e.last_name) AS full_name, dep_name.dept_name, c.salary, t.title FROM employees AS e LEFT JOIN #这个查询求出普通员工的信息 dept_manager AS dp ON e.emp_no = dp.emp_no LEFT JOIN (SELECT #子查询中求出员工最近的薪水 emp_no, salary FROM salaries a WHERE from_date = (SELECT MAX(from_date) FROM salaries b WHERE a.emp_no = b.emp_no GROUP BY emp_no)) c ON e.emp_no = c.emp_no LEFT JOIN (SELECT #子查询中求出员工最近的title emp_no, title FROM titles a WHERE from_date = (SELECT MAX(from_date) FROM titles b WHERE a.emp_no = b.emp_no GROUP BY emp_no)) t ON e.emp_no = t.emp_no LEFT JOIN (SELECT #这个子查询求出员工的最新的职称信息 a.emp_no, a.dept_no, dp.dept_name FROM dept_emp AS a, departments AS dp WHERE from_date = (SELECT MAX(from_date) FROM dept_emp AS b WHERE a.emp_no = b.emp_no GROUP BY emp_no) AND dp.dept_no = a.dept_no) dep_name ON dep_name.emp_no = e.emp_no WHERE dp.dept_no IS NULL; #过滤出非普通的员工
查询的结果执行时,可以加上limit函数,不然会很慢,至于优化问题,暂时先不管!
union联合查询
有两张表如下: mysql> select * from tb1; +----+------+ | c1 | c2 | +----+------+ | 1 | zhao | | 2 | qina | | 3 | b | | 4 | c | +----+------+ 4 rows in set (0.00 sec) mysql> select * from tb2; +------+------+ | id | NAME | +------+------+ | 1 | a | | 3 | b | | 4 | c | | 5 | d | | 6 | e | +------+------+ 5 rows in set (0.00 sec) #使用UNION联合查询, 去重复,把重复的数值自动去掉 mysql> select * from tb1 -> union -> select * from tb2; +------+------+ | c1 | c2 | +------+------+ | 1 | zhao | | 2 | qina | | 3 | b | | 4 | c | | 1 | a | | 5 | d | | 6 | e | +------+------+ 7 rows in set (0.00 sec) #使用all关键字,会把重复的行也查询出来 mysql> select * from tb1 -> union all -> select * from tb2; +------+------+ | c1 | c2 | +------+------+ | 1 | zhao | | 2 | qina | | 3 | b | | 4 | c | | 1 | a | | 3 | b | | 4 | c | | 5 | d | | 6 | e | +------+------+ 9 rows in set (0.00 sec)
给查询的结果加上行号:
查询员工信息时,给查询的结果加上行号。
mysql> set @rn:=0; Query OK, 0 rows affected (0.00 sec) mysql> select @rn:=@rn+1 as row_num, emp_no, concat("first_name"," ","last_name") as full_name from employees limit 10; +---------+--------+----------------------+ | row_num | emp_no | full_name | +---------+--------+----------------------+ | 1 | 10001 | first_name last_name | | 2 | 10002 | first_name last_name | | 3 | 10003 | first_name last_name | | 4 | 10004 | first_name last_name | | 5 | 10005 | first_name last_name | | 6 | 10006 | first_name last_name | | 7 | 10007 | first_name last_name | | 8 | 10008 | first_name last_name | | 9 | 10009 | first_name last_name | | 10 | 10010 | first_name last_name | +---------+--------+----------------------+ 10 rows in set (0.00 sec) #这样写有点不方便就是需要两个SQL语句,还有一个就是,当第二次查询数据是,行号不会清零,会累加! mysql> select @rn:=@rn+1 as row_num, emp_no, concat("first_name"," ","last_name") as full_name from employees limit 10; +---------+--------+----------------------+ | row_num | emp_no | full_name | +---------+--------+----------------------+ | 11 | 10001 | first_name last_name | | 12 | 10002 | first_name last_name | | 13 | 10003 | first_name last_name | | 14 | 10004 | first_name last_name | | 15 | 10005 | first_name last_name | | 16 | 10006 | first_name last_name | | 17 | 10007 | first_name last_name | | 18 | 10008 | first_name last_name | | 19 | 10009 | first_name last_name | | 20 | 10010 | first_name last_name | +---------+--------+----------------------+ 10 rows in set (0.00 sec) #尽量使用一条SQL语句,行号每次查询时会清零: mysql> select @rn:=@rn+1 as row_num, emp_no, concat("first_name"," ","last_name") as full_name from employees, (select @rn:=0) as row_num limit 10; +---------+--------+----------------------+ | row_num | emp_no | full_name | +---------+--------+----------------------+ | 1 | 10001 | first_name last_name | | 2 | 10002 | first_name last_name | | 3 | 10003 | first_name last_name | | 4 | 10004 | first_name last_name | | 5 | 10005 | first_name last_name | | 6 | 10006 | first_name last_name | | 7 | 10007 | first_name last_name | | 8 | 10008 | first_name last_name | | 9 | 10009 | first_name last_name | | 10 | 10010 | first_name last_name | +---------+--------+----------------------+ 10 rows in set (0.00 sec)
MySQL的一个排名问题:
#有如下的数据,按照成绩排名: mysql> select * from rank; +------+-------+ | id | score | +------+-------+ | 1 | 10 | | 2 | 20 | | 3 | 20 | | 4 | 30 | | 5 | 40 | | 6 | 40 | | 7 | 20 | +------+-------+ 7 rows in set (0.00 sec) #成绩有相同的,按照成绩排名 set @prev_value = NULL; set @rank_count = 0; SELECT id, score, CASE WHEN @prev_value = score THEN @rank_count WHEN @prev_value := score THEN @rank_count := @rank_count + 1 end as rank_column from rank ORDER BY score; #如果我们期望有一条SQL语句完成排名,可以仿照上面的方法: mysql> SELECT id, score, -> CASE -> WHEN @prev1_value = score THEN @rank1_count -> WHEN @prev1_value := score THEN @rank1_count := @rank1_count + 1 -> end as rank_column -> from rank, (SELECT @prev1_value := NULL, @rank1_count :=0 ) as rank_column -> ORDER BY score; #注意可以测试一下加ORDER BY与不加ORDER BY的结果,会不一样的! +------+-------+-------------+ | id | score | rank_column | +------+-------+-------------+ | 1 | 10 | 1 | | 2 | 20 | 2 | | 3 | 20 | 2 | | 7 | 20 | 2 | | 4 | 30 | 3 | | 5 | 40 | 4 | | 6 | 40 | 4 | +------+-------+-------------+ 7 rows in set (0.00 sec) SQL语句如下: SELECT id, score, CASE WHEN @prev1_value = score THEN @rank1_count WHEN @prev1_value := score THEN @rank1_count := @rank1_count + 1 end as rank_column from rank, (SELECT @prev1_value := NULL, @rank1_count :=0 ) as rank_column ORDER BY score;

 浙公网安备 33010602011771号
浙公网安备 33010602011771号