
负载均衡之-haproxy
1)HAProxy提供高可用性、负载均衡以及基于TCP和HTTP应用的代理,支持虚拟主机,它是免费、快速并且可靠的一种解决方案。
2)HAProxy特别适用于那些负载特大的web站点,这些站点通常又需要会话保持或七层处理。
3)HAProxy运行在当前的硬件上,完全可以支持数以万计的并发连接。并且它的运行模式使得它可以很简单安全的整合进您当前的架构中, 同时可以保护你的web服务器不被暴露到网络上。
4)HAProxy实现了一种事件驱动, 单一进程模型,此模型支持非常大的并发连接数。多进程或多线程模型受内存限制 、系统调度器限制以及无处不在的锁限制,很少能处理数千并发连接。事件驱动模型因为在有更好的资源和时间管理的用户空间(User-Space) 实现所有这些任务,所以没有这些问题。此模型的弊端是,在多核系统上,这些程序通常扩展性较差。这就是为什么他们必须进行优化以 使每个CPU时间片(Cycle)做更多的工作。
--------------------- 原文:https://blog.csdn.net/sj349781478/article/details/78862315
安装haproxy
推荐直接yum安装吧:
yum install -y haproxy
haproxy的配置文件在/etc/haproxy/下面!
haproxy配置文件参数,在http://www.ywnds.com/?p=6749 博客中有详细的说明,这里只说明haproxy的用法以及涉及到的参数说明!
首先来测试负载均衡:
两台后端服务器ip为:10.0.102.204和10.0.102.214,是nginx服务器!
10.0.102.179作为调度器,使用的是haproxy!
yum安装完成之后,在配置文件中加入如下参数,也可以修改原配置文件!
frontend webserver bind *:80 default_backend web_test backend web_test balance roundrobin server app1 10.0.102.204:80 check server app2 10.0.102.214:80 check
#frontend定义了一些监听的套接字,bind监听套接字的端口,*表示监听所有的ip,default_backend定义了real server服务器组
#backend:指定后端服务器组,与前面的frontend对应,balance表示使用的调度算法,server指定的是后面真实服务器的地
测试如下:
[root@mgt01 ~]# curl 10.0.102.179 The host ip is 10.0.102.204 [root@mgt01 ~]# curl 10.0.102.179 The hosname is test3
使用listen命令
上面的配置可以使用一个listen配置,同时还可以加上权重:
listen webserver bind *:80 stats enable #启用haproxy自带的界面监控 balance roundrobin server app1 10.0.102.204:80 check weight 2 server app2 10.0.102.214:80 check weight 1
访问测试:
[root@mgt01 ~]# curl 10.0.102.179 The host ip is 10.0.102.204 [root@mgt01 ~]# curl 10.0.102.179 The host ip is 10.0.102.204 [root@mgt01 ~]# curl 10.0.102.179 The hosname is test3 [root@mgt01 ~]# curl 10.0.102.179 The host ip is 10.0.102.204 [root@mgt01 ~]# curl 10.0.102.179 The host ip is 10.0.102.204 [root@mgt01 ~]# curl 10.0.102.179 The hosname is test3 [root@mgt01 ~]#
访问其web界面:
url的格式如下:
http://10.0.102.179/haproxy?stats
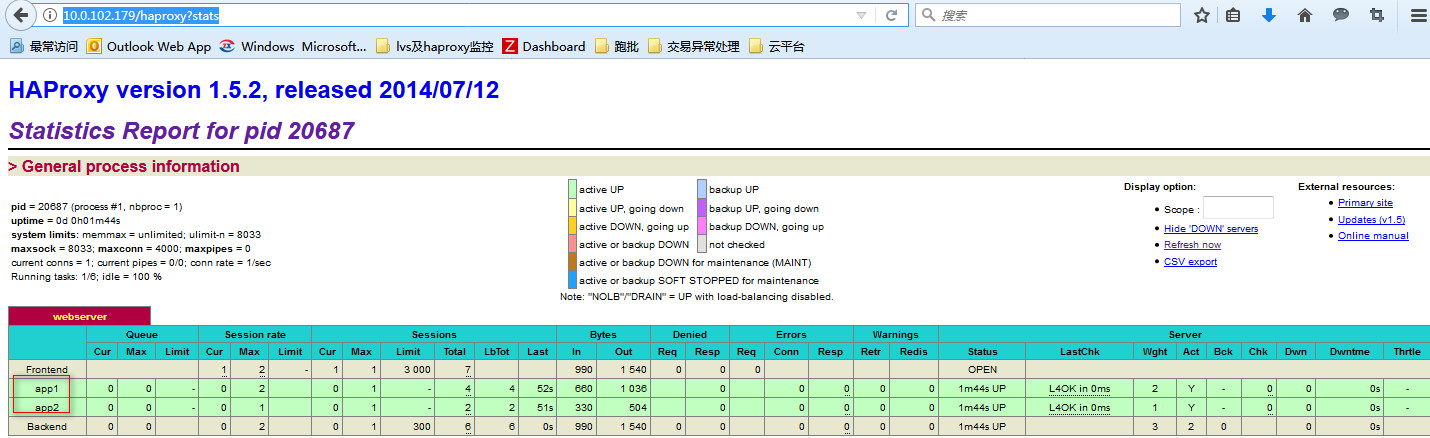
这个界面的信息统计还是蛮全面的!
访问这个界面的时候,界面上显示了haproxy的版本号,我们可以设置不显示版本号,并且还可以加上用户认证!
配置如下:
listen webserver bind *:80 stats enable stats hide-version #隐藏版本信息 stats realm FUCK #显示提示信息 stats auth admin:123456 #认证的用户名和密码 balance roundrobin server app1 10.0.102.204:80 check weight 2 server app2 10.0.102.214:80 check weight 1
再次访问url时候,会出现如下提示:
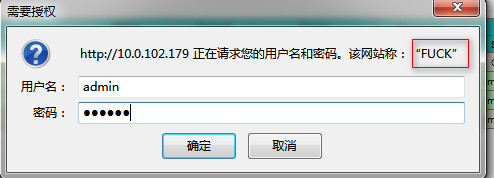
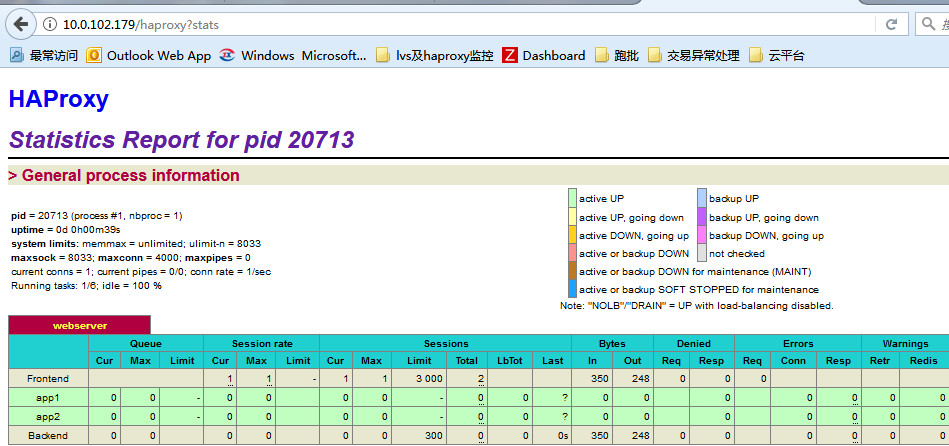
输入正确的用户名和密码之后,会进入到监控界面,可以看到监控界面中haproxy的版本信息已经消失!
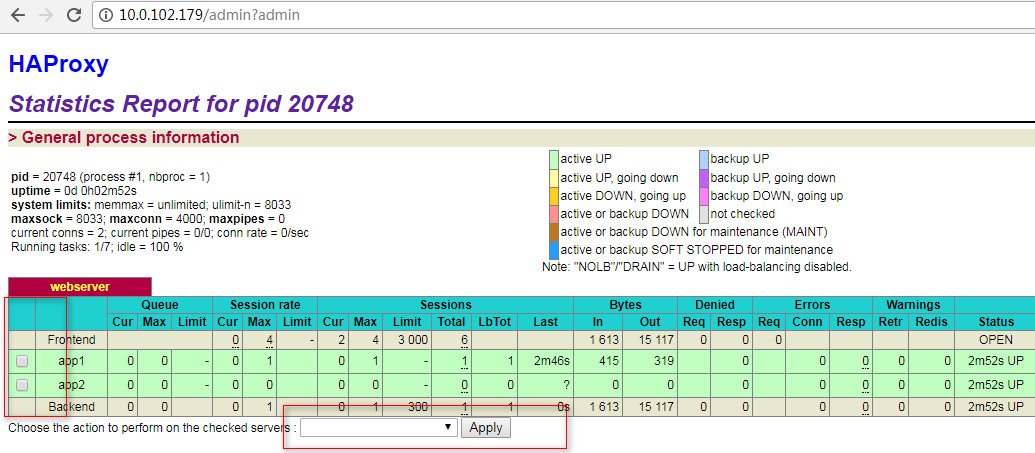
相比较于lvs和keepalived,haproxy的web界面已经很让人惊奇了!我们还可以在web界面进行一些操作,只需要打开管理员的窗口即可!
listen webserver bind *:80 stats enable stats hide-version stats realm FUCK stats auth admin:123456 stats admin if TRUE stats uri /admin?admin balance roundrobin server app1 10.0.102.204:80 check weight 2 server app2 10.0.102.214:80 check weight 1
打开如下的url:
http://10.0.102.179/admin?admin
输入用户名和密码之后
上面的监听都是监听同一端口,可以借助于listen和frontend设置监听不同的端口!
我们把其中的一个后端服务器的端口改为监听8080端口!
[root@test2 sbin]# netstat -lntp Active Internet connections (only servers) Proto Recv-Q Send-Q Local Address Foreign Address State PID/Program name tcp 0 0 0.0.0.0:22 0.0.0.0:* LISTEN 1028/sshd tcp 0 0 0.0.0.0:8080 0.0.0.0:* LISTEN 1293/nginx tcp 0 0 :::22 :::* LISTEN 1028/sshd [root@test2 sbin]#
修改haproxy的配置文件如下:
listen webserver bind *:80 balance roundrobin server app1 10.0.102.214:80 check weight 2 stats enable stats hide-version stats realm FUCK stats auth admin:123456 stats admin if TRUE stats uri /admin?admin frontend test bind *:8080 default_backend back_srv backend back_srv balance roundrobin server app2 10.0.102.204:8080 check weight 1
然后重新haproxy,测试结果如下:
[root@mgt01 ~]# curl 10.0.102.179 The hosname is test3 [root@mgt01 ~]# curl 10.0.102.179:8080 The host ip is 10.0.102.204
上面说明了haproxy的一些简单应用,但是haproxy都是单机的,接下来我们测试haproxy+keepalived的应用!
使用haproxy做负载均衡,使用keepalived做高可用!
keeplaived配置参数详解,很详细的地址: https://blog.csdn.net/mofiu/article/details/76644012
在这里我们引入了一个vrrp_script参数:
作用:添加一个周期性执行的脚本。脚本的退出状态码会被调用它的所有的VRRP Instance记录。 注意:至少有一个VRRP实例调用它并且优先级不能为0.优先级范围是1-254. vrrp_script <SCRIPT_NAME> { ... } 选项说明: scrip "/path/to/somewhere":指定要执行的脚本的路径。 interval <INTEGER>:指定脚本执行的间隔。单位是秒。默认为1s。 timeout <INTEGER>:指定在多少秒后,脚本被认为执行失败。 weight <-254 --- 254>:调整优先级。默认为2. rise <INTEGER>:执行成功多少次才认为是成功。 fall <INTEGER>:执行失败多少次才认为失败。 user <USERNAME> [GROUPNAME]:运行脚本的用户和组。 init_fail:假设脚本初始状态是失败状态。 解释: weight: 1. 如果脚本执行成功(退出状态码为0),weight大于0,则priority增加。 2. 如果脚本执行失败(退出状态码为非0),weight小于0,则priority减少。 3. 其他情况下,priority不变。
做为master的配置文件如下:
! Configuration File for keepalived vrrp_script check_haproxy { script "/root/check_haproxy_status.sh" interval 3 weight -5 } vrrp_instance VI_1 { state MASTER interface eth0 virtual_router_id 62 priority 91 advert_int 1 authentication { auth_type PASS auth_pass 1111 } track_script { check_haproxy } virtual_ipaddress { 10.0.102.110 dev eth0 } }
从的配置文件与主基本相似,需要更改的是state的状态和权重值!需要保证两台主备的virtual_router_id数值是一样的!
然后是添加检测脚本文件:
cat check_haproxy_status.sh #!/bin/bash if [ $(ps -C haproxy --no-header | wc -l) -eq 0 ];then service haproxy start fi sleep 2 if [ $(ps -C haproxy --no-header | wc -l) -eq 0 ];then service keepalived stop fi
然后分别在master和backup上启动keepalived!
测试VIP如下:
[root@test3 sbin]# curl 10.0.102.110 The hosname is test3 [root@test3 sbin]# curl 10.0.102.110 The host ip is 10.0.102.204 [root@test3 sbin]# curl 10.0.102.110 The hosname is test3 [root@test3 sbin]# curl 10.0.102.110 The hosname is test3 [root@test3 sbin]# curl 10.0.102.110 The host ip is 10.0.102.204
我们可以在主上模拟,停掉haproxy的服务,观察VIP的漂移情况,只有在主上的keepalived服务停掉之后,VIP才会发生漂移!
在线上环境中有一个问题,好像是bug吧!就是keepalived运行长时间之后,会忽然停掉,不知道什么原因造成。在这里使用了自己写的shell脚本,对keepalived进行监控。
在master上配置文件,监控脚本,如下:


[root@test1 log]# cat /etc/keepalived/keepalived.conf ! Configuration File for keepalived vrrp_script check_haproxy { script "/root/check_haproxy_status.sh" interval 3 weight -5 } vrrp_instance VI_1 { state MASTER interface eth0 virtual_router_id 110 priority 91 nopreempt advert_int 1 authentication { auth_type PASS auth_pass 1111 } track_script { check_haproxy } virtual_ipaddress { 10.0.102.110 dev eth0 } } [root@test1 log]#
监控脚本如下:
[root@test1 log]# cat /root/moniter_keepalived.sh #!/bin/bash # # VIP=10.0.102.110 MASTER=10.0.102.179 BACKUP=10.8.102.221 CONF=/etc/keepalived/keepalived.conf NodeRole=`grep -i "state" /etc/keepalived/keepalived.conf | awk '{print $2}'` check_Vip() { ping -c 1 -w 3 $VIP &> /dev/null && return 0 || return 1 } restart_Server() { if [ $NodeRole == "MASTER" ];then ping -c 1 -w 3 $BACKUP &> /dev/null if [ $? -eq 0 ];then ssh -l root $BACKUP "/etc/init.d/keepalived stop" sleep 2 /etc/init.d/keepalived restart echo `date +%Y-%m-%d_%H:%M` "NodeRole--MASTER: if" check_Vip && ssh -l root $BACKUP "/etc/init.d/keepalived start" else /etc/init.d/keepalived restart echo `date +%Y-%m-%d_%H:%M` "NodeRole-Master: else" fi elif [ $NodeRole == "BACKUP" ];then ping -c 1 -w 3 $MASTER &> /dev/null if [ $? -eq 0 ];then /etc/init.d/keepalived stop ssh -l root $MASTER "/etc/init.d/keepalived restart" check_Vip && /etc/init.d/keepalived start echo $(date +%F_%H-%M-%S) "NodeRole-BACKUP: if" else /etc/init.d/keepalived restart echo $(date +%F_%H-%M-%S) "NodeRole-Backup: else" fi fi } while true;do check_Vip if [ $? -eq 1 ];then restart_Server else echo "ok" fi sleep 3 done
监控脚本加上可执行权限,然后放到后台运行!
nohup /root/moniter_keepalived.sh > /var/log/nohup.log 2>&1 &
在backup上配置文件如下:
[root@mgt01 ~]# cat /etc/keepalived/keepalived.conf ! Configuration File for keepalived vrrp_script check_haproxy { script "/root/check_haproxy_status.sh" interval 3 weight -5 } vrrp_instance VI_1 { state BACKUP interface eth0 virtual_router_id 110 priority 80 advert_int 1 authentication { auth_type PASS auth_pass 1111 } track_script { check_haproxy } virtual_ipaddress { 10.0.102.110 dev eth0 } }
监控脚本如下:
[root@mgt01 ~]# cat moniter_keepalived.sh #!/bin/bash # # VIP=10.0.102.110 MASTER=10.0.102.179 BACKUP=10.0.102.221 CONF=/etc/keepalived/keepalived.conf NodeRole=`grep -i "state" /etc/keepalived/keepalived.conf | awk '{print $2}'` check_Vip() { ping -c 1 -w 3 $VIP &> /dev/null && return 0 || return 1 } restart_Server() { if [ $NodeRole == "MASTER" ];then ping -c 1 -w 3 $BACKUP &> /dev/null if [ $? -eq 0 ];then ssh -l root $BACKUP "/etc/init.d/keepalived stop" sleep 2 /etc/init.d/keepalived restart echo `date +%Y-%m-%d_%H:%M` "NodeRole--MASTER: if" check_Vip && ssh -l root $BACKUP "/etc/init.d/keepalived start" else /etc/init.d/keepalived restart echo `date +%Y-%m-%d_%H:%M` "NodeRole-Master: else" fi elif [ $NodeRole == "BACKUP" ];then ping -c 1 -w 3 $MASTER &> /dev/null if [ $? -eq 0 ];then /etc/init.d/keepalived stop ssh -l root $MASTER "/etc/init.d/keepalived restart" check_Vip && /etc/init.d/keepalived start echo $(date +%F_%H-%M-%S) "NodeRole-BACKUP: if" else /etc/init.d/keepalived restart echo $(date +%F_%H-%M-%S) "NodeRole-Backup: else" fi fi } check_Vip if [ $? -eq 1 ];then restart_Server fi
把此监控脚本加入可执行计划!
[root@mgt01 ~]# crontab -l */1 * * * * sh /root/moniter_keepalived.sh
当主和备的keepalived都宕机时,主的keepalived就会重新启动!

 浙公网安备 33010602011771号
浙公网安备 33010602011771号