python-主成分CPA
1、含义及思想
主成分分析-Principal Component Analysis,是Hotelling于1933年首先提出来的。利用降维的思想,在保留原始变量尽可能多的信息前提下把多个指标转化为几个不相关的综合指标的多远统计方法。
通常把原始变量的线性组合称为主成分,主成分之间互不相关(包含的信息互不重叠)、主成分的方差(包含的信息)依次递减。
主成分个数选取标准:在实际工作中,主成分个数的多少能够反映原来变量85%以上的信息量为依据,即当累积贡献率 >= 85%时的主成分个数就足够了。最常见的情况是主成分为2-3个。
2、一般步骤
-
数据标准化处理
-
计算样本相关系数矩阵、求特征值和特征向量
-
选择主成分个数,并写出主成分表达式
-
计算主成分得分、计算综合得分
3、实例应用
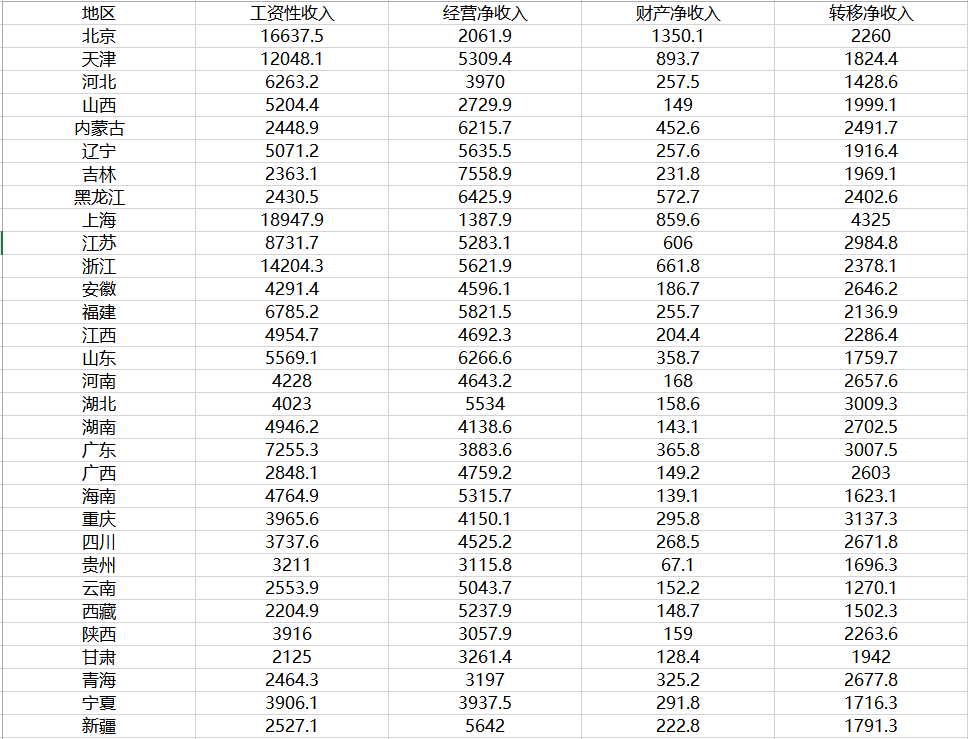
对全国30个省市农村收入来源数据进行主成分分析并进行综合排名。
数据集如下:
import pandas as pd
ori_data = pd.read_excel(r'C:\Users\Desktop\农村居民人均可支配收入来源2016.xlsx')
# 数据规范化处理
from sklearn.preprocessing import StandardScaler
scaler = StandardScaler().fit(ori_data.iloc[:, 1:])
data = scaler.transform(ori_data.iloc[:, 1:])
# data.mean(axis=0)
# data.std(axis=0)
from sklearn.decomposition import PCA
pca = PCA(n_components=0.85) # 要求累计贡献率达到85%及以上
pca.fit(data) # 对待分析的数据进行拟合训练
result = pca.transform(data) # 提取主成分
tzxl = pca.components_ # 返回特征向量
tz = pca.explained_variance_ # 返回特征值
gxl = pca.explained_variance_ratio_ # 返回方差贡献率
# 综合得分及排名
score = result @ gxl
F = pd.DataFrame({"综合得分": score} , index=ori_data["地区"])
F.sort_values(by=["综合得分"], ascending=False, inplace=True)
F



 浙公网安备 33010602011771号
浙公网安备 33010602011771号