python-pandas.cut()数据分箱
在对数据处理的过程中,经常会用到对不同阈值的数据贴上不同的标签,或者将连续数据转换成分类数据,pandas中的cut函数可以较好解决数据划分不同标签问题。
pandas.cut(x, bins, right=True, labels=None, retbins=False, precision=3, include_lowest=False, duplicates='raise', ordered=True )
参数解释:
x : 要进行分割的一维数组。
bins :整数,标量序列或者间隔索引,是进行分组的依据。
- 如果填入整数n,则表示将x中的数值分成等宽的n份(即每一组内的最大值与最小值之差约相等); - 如果是标量序列,序列中的数值表示用来分档的分界值 - 如果是间隔索引,“ bins”的间隔索引必须不重叠
right:布尔值,默认为True表示包含最右侧的数值。
- 当right = True(默认值)时,则bins=[1、2、3、4]表示(1,2],(2,3],(3,4] - 当bins是一个间隔索引时,该参数被忽略。
labels : 数组或布尔值,可选.指定分箱的标签。
- 如果是数组,长度要与分箱个数一致,比如bins=[1、2、3、4]表示(1,2],(2,3],(3,4]一共3个区间,则labels的长度也就是标签的个数也要是3 - 如果为False,则仅返回分箱的整数指示符,即x中的数据在第几个箱子里。
当bins是间隔索引时,将忽略此参数
retbins:是否显示分箱的分界值。默认为False,当bins取整数时可以设置retbins=True以显示分界值,得到划分后的区间
precision:整数,默认3,存储和显示分箱标签的精度。
include_lowest:布尔值,表示区间的左边是开还是闭,默认为false,也就是不包含区间左边。
duplicates:如果分箱临界值不唯一,则引发ValueError或丢弃非唯一。
栗子:
import numpy as np import pandas as pd
分割成等宽的n等分,bins=n
x = np.array([1, 7, 5, 4, 6, 3]) pd.cut(x, bins=3)

分割等宽n等分并指定标签
x = np.array([1, 7, 5, 4, 6, 3]) pd.cut(x, bins=3, labels=["bad", "medium", "good"])

只返回bin,设置labels=False
x = np.array([1, 7, 5, 4, 6, 3]) pd.cut(x, bins=3, labels=False)

结果表示数字1在第0号箱子,数字7在第2号箱子....
显示分界值,retbins=True

bins传入间隔索引
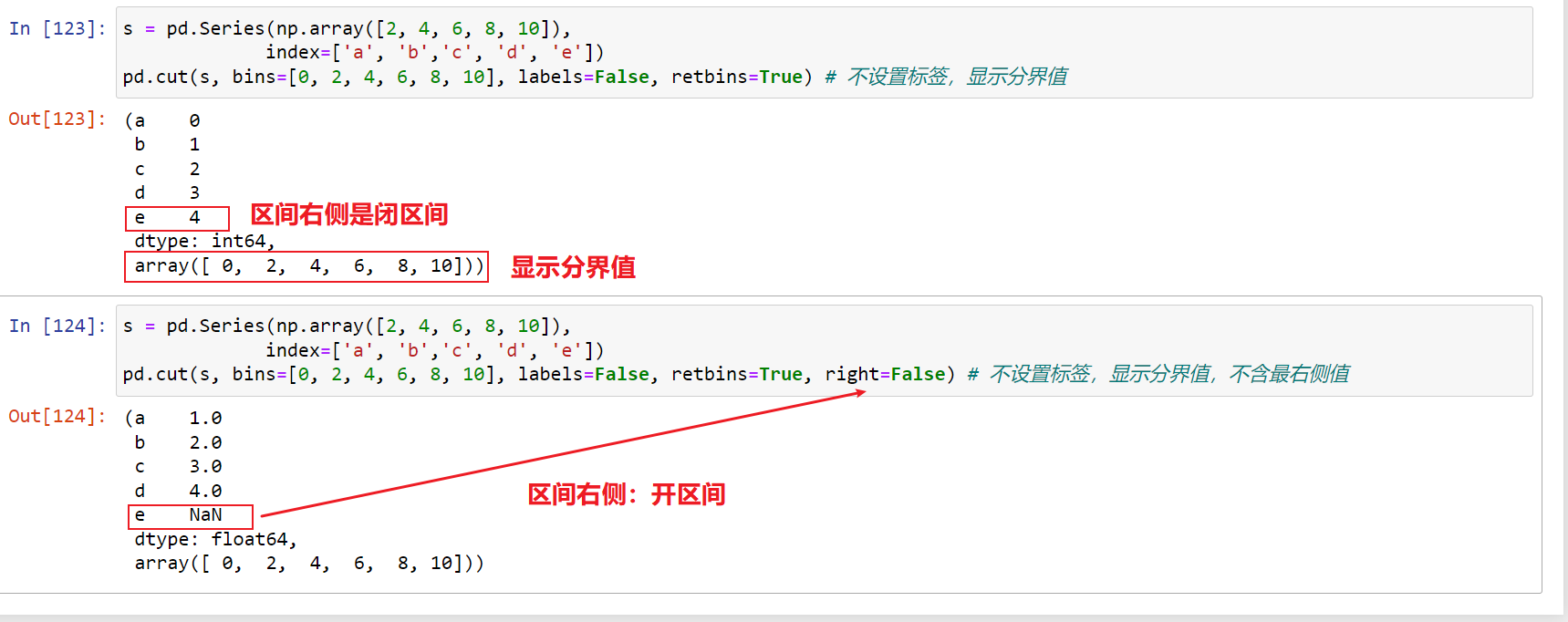
s = pd.Series(np.array([2, 4, 6, 8, 10]), index=['a', 'b','c', 'd', 'e']) pd.cut(s, bins=[0, 2, 4, 6, 8, 10], labels=False, retbins=True, right=False) # 不设置标签,显示分界值,不含最右侧值
bins传入间隔索引存在重复数据
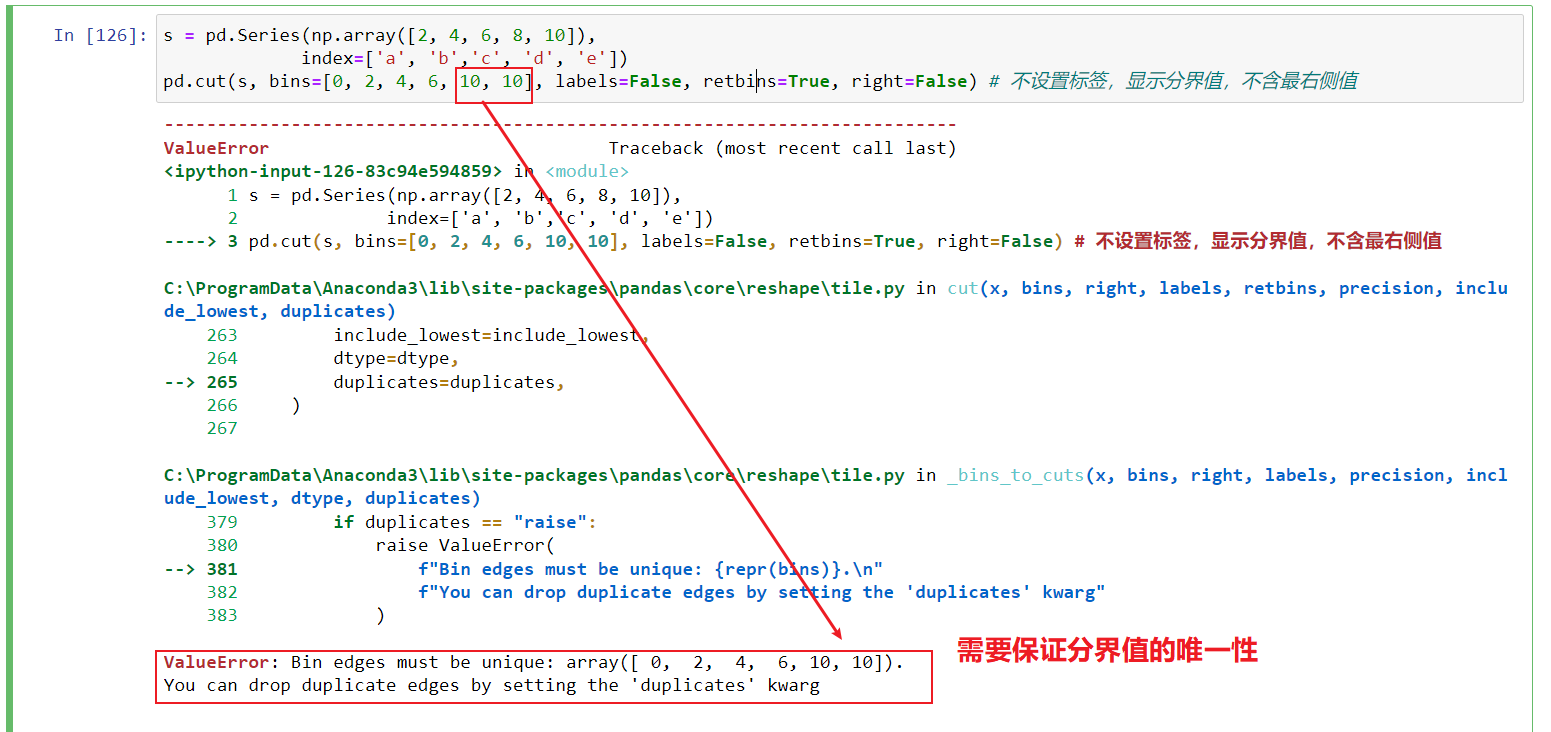
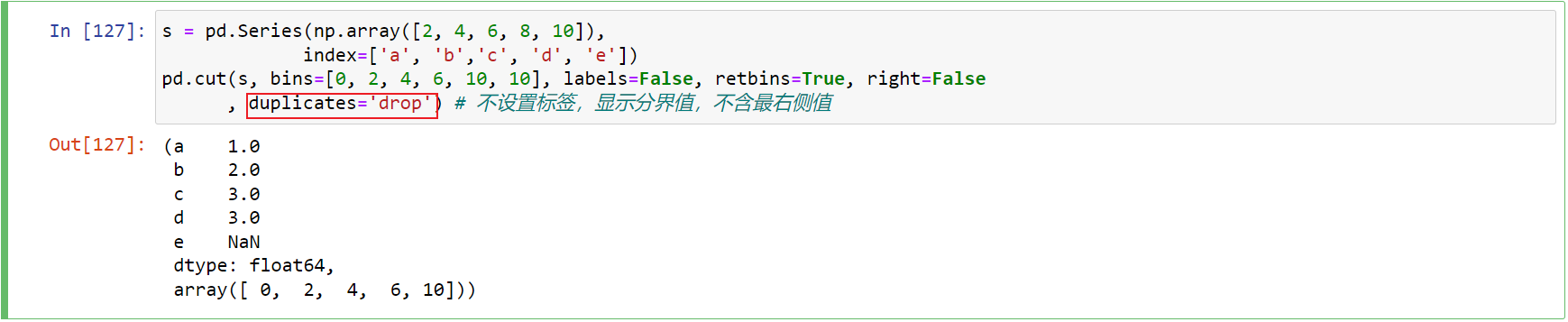
s = pd.Series(np.array([2, 4, 6, 8, 10]), index=['a', 'b','c', 'd', 'e']) pd.cut(s, bins=[0, 2, 4, 6, 10, 10], labels=False, retbins=True, right=False , duplicates='drop') # 不设置标签,显示分界值,不含最右侧值



【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· 无需6万激活码!GitHub神秘组织3小时极速复刻Manus,手把手教你使用OpenManus搭建本
· Manus爆火,是硬核还是营销?
· 终于写完轮子一部分:tcp代理 了,记录一下
· 别再用vector<bool>了!Google高级工程师:这可能是STL最大的设计失误
· 单元测试从入门到精通