python-缺失值处理
python 缺失值用np.nan表示,默认情况下,在计算中是会自动忽略。
创建数据集
import pandas as pd
import numpy as np
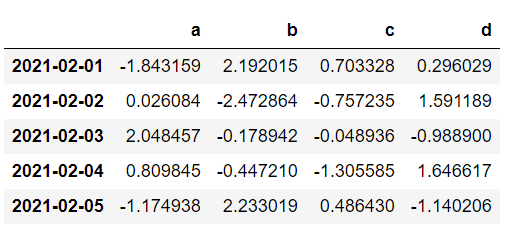
index = pd.date_range('2021-02-01',periods=5)
# np.random.randn(5,4) 生成5行4列的随机数
df = pd.DataFrame(np.random.randn(5,4),index = index,columns=list('abcd'))
df
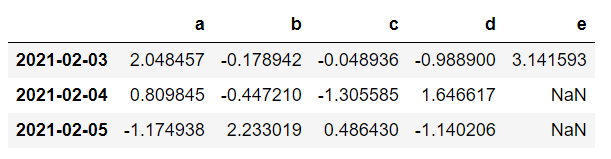
通过pd.Series新增一列含nan的数据,新增的列的index必须与原数据一致
df1 = df.loc['2021-02-03':'2021-02-05'].copy()
df1['e']=pd.Series([3.1415926,np.nan,np.nan],index=index[2:5])
df1
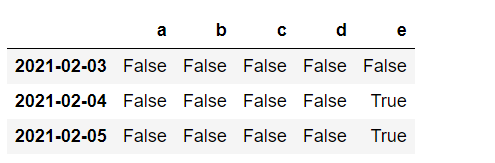
1.缺失值识别
# 缺失值识别
df1.isna()
2.缺失值删除
# 缺失值删除
df2 = df1.copy()
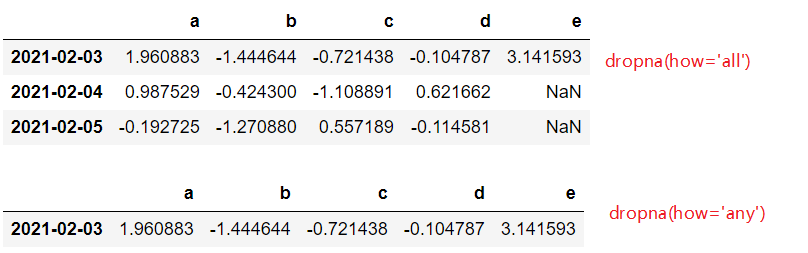
df2.dropna(how='all')
df2.dropna(how='any')
3.缺失值填充
# 缺失值填充
df3 = df1.copy()
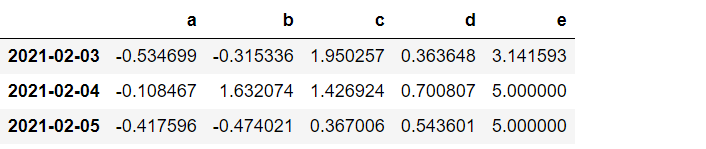
df3.fillna(value=5)
注意:
1.python中进行nan与nan是否相等判断,是无效的;但是可以判断none与none是否相等

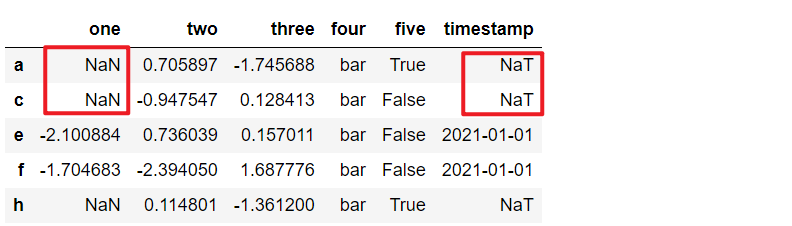
2.时间类型数据缺失值显式为Na.T,依然用np.nan设置
df = pd.DataFrame(
np.random.randn(5,3),
index = ["a", "c", "e", "f", "h"],
columns = ["one", "two", "three"]
)
df["four"] = "bar"
df['five'] = df['one']>0
df2 = df.copy()
df2["timestamp"] = pd.Timestamp("2021-01-01")
df2.loc[["a", "c", "h"],["one","timestamp"]] = np.nan
df2