spark行列数据转换
列转行
lateral view 是什么
lateral view用于和split, explode等UDTF一起使用,它能够将一行数据拆成多行数据,在此基础上可以对拆分后的数据进行聚合。
一个from语句后可以跟多个lateral view语句,后面的lateral view语句能够引用它前面的所有表和列名。
explode 是什么
将一行数据转换成多行数据,可以用于array和map类型的数据。就是将hive一行中复杂的array或者map结构拆分成多行
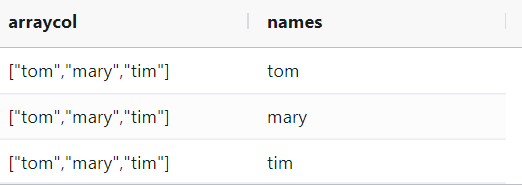
用于array语法
select arraycol,explode(arraycol)as names
from
(
select array("tom","mary","tim") as arraycol
)
运行结果如下:
用于map语法
-- ## 由于map是key_value结果,在转换的时候会转换成两列key和value,在命名别名时注意括号括起来,逗号分隔。
select dict,explode(dict)as (keysname,valuename)
from
(
select map('100','tom','200','mary') as dict
)
运行结果如下:

spark 1X1维度的数据转换成nX1维度
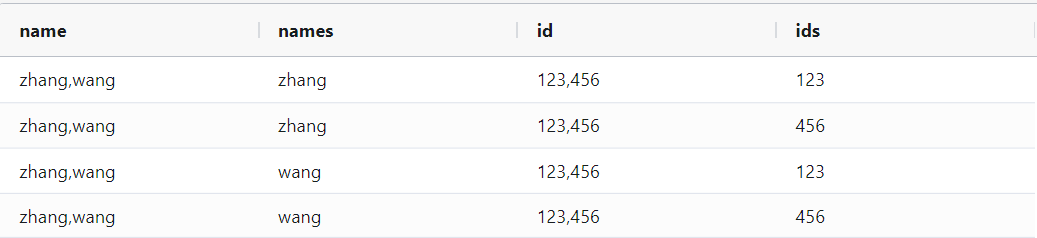
select name,names,id,ids
from
(
select 'zhang,wang'as name,'123,456'as id
)a
lateral view explode (split(name,','))o as names ## o 为lateral view 虚拟表名,names为定义的输出字段名
lateral view explode (split(id,','))d as ids
运行结果如下:
json文本提取相同key的多个values
假设有如下Json文本,需要提取所有的orderid,显然这些orderid都被包裹在一个数组里,若通过get_json_object()需要提取n次,效果如下:
select get_json_object(body,'$.session.sid')as sid
,get_json_object(json_array(get_json_object(body,'$.session.orderIds'))[0],'$.orderId')as orderIds
,get_json_object(json_array(get_json_object(body,'$.session.orderIds'))[1],'$.orderId')as orderIds
from
(
select '{"session": {
"sid": "800000055191936",
"gid": "16612476960752271281",
"createTime": 1610964871147,
"orderIds": [
{
"orderId": "1437226012673",
"endTime": 1610968963677
},
{
"orderId": "1437229210305",
"endTime": 1610968963677
},
{
"orderId": "1437229312697",
"startTime": 1610965863646
},
{
"orderId": "1437230110801",
"startTime": 1610966442829
},
{
"orderId": "1437237321377",
"endTime": 1610968963545
}
]
}} 'as body,'1234'as id
)as a
详细拆解下这句语法get_json_object(json_array(get_json_object(body,'\(.session.orderIds'))[0],'\).orderId')
step_1:get_json_object(body,'$.session.orderIds'):提取orderIds包含的内容,获取的类型是数组
step_2:json_array(get_json_object(body,'$.session.orderIds'))[0]:获取数组中的第一个json对象
step_3:get_json_object(json_array(get_json_object(body,'\(.session.orderIds'))[0],'\).orderId'):解析step_2中的orderId
如果json文本里有n个orderId需要提取,用上面的方法就需要写n遍,那有没有“一劳永逸”的办法呢???见下:
select get_json_object(body,'$.session.sid')as sid
,orderids,a_orderid,endtime
,get_json_object(orderids,'$.orderId')as `get_json_object_orderid`
,body
from
(
select '{"session": {
"sid": "800000055191936",
"gid": "16612476960752271281",
"createTime": 1610964871147,
"orderIds": [
{
"orderId": "1437226012673",
"endTime": 1610968963677
},
{
"orderId": "1437229210305",
"endTime": 1610968963677
},
{
"orderId": "1437229312697",
"startTime": 1610965863646
},
{
"orderId": "1437230110801",
"startTime": 1610966442829
},
{
"orderId": "1437237321377",
"endTime": 1610968963545
}
]
}} 'as body,'1234'as id
)as a
lateral view explode (split(regexp_replace(regexp_extract(get_json_object(body,'$.session.orderIds'),'^\\[(.+)\\]$',1),'\\}\\,\\{', '\\}\\|\\|\\{'),'\\|\\|'))b as orderids -- 先正则替换,一行转多行
lateral view json_tuple(orderids,'orderId','endTime')d as a_orderid,endtime
运行结果如下:

行转列
spark nX1维度的数据转换成1X1维度
collect_set(字段) ## 去重将多行数据转换成一维数组格式
collect_list(字段) ## 不去重将多行数据转换成一维数组格式。数据为字符形式时,应使用该函数
collect_set(字段)[0] ## 取数组中的第一个数据
sort_array() ## 对数组排序,默认升序
相当于将值进行了聚合,因此需要group by 操作
举个栗子
先创建数据集
select *
from
(
select 'A' as label, '95'as score,'math'as subject
union all
select 'A' as label, '90'as score,'english'as subject
union all
select 'A' as label, '76'as score,'chinese'as subject
union all
select 'B' as label, '95'as score,'chinese'as subject
union all
select 'B' as label, '95'as score,'english'as subject
union all
select 'B' as label, '100'as score,'math'as subject
)
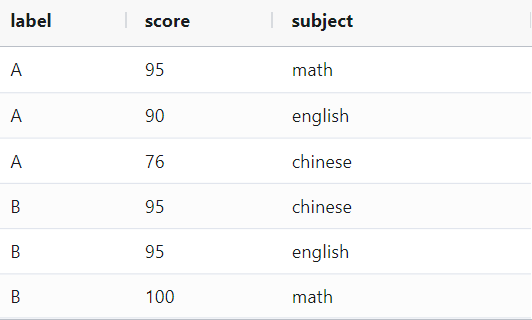
A和B两位同学,语数外成绩各占一行,如果我想将每个人的记录仅占用一行展示怎么处理呢?
select label,collect_set(score)as `去重score`,collect_list(score)as `不去重score`
,collect_set(subject)as `set_subject`
,collect_list(subject)as `list_subject`
,sort_array(collect_list(subject))as `不去重排序subject`
from
(
select 'A' as label, '95'as score,'math'as subject
union all
select 'A' as label, '90'as score,'english'as subject
union all
select 'A' as label, '76'as score,'chinese'as subject
union all
select 'B' as label, '95'as score,'chinese'as subject
union all
select 'B' as label, '95'as score,'english'as subject
union all
select 'B' as label, '100'as score,'math'as subject
)
group by label
运行结果如下

当行转列的数据有字符,且又为了与前面的数据形成对应,应使用collect_list()
