python-Pandas基础语法
Pandas主要数据结构包括Series(一维数据,同构)和DataFrame(二维数据,异构)。Pandas是基于Numpy开发。
Series
基本操作
import pandas as pd
import numpy as np
#%% 创建一维数据
s = pd.Series([1, 3, 5, np.nan, 6, 8])
s
#%% help(pd.date_range) # pandas核心日期索引函数 pd.date_range
#%% pd.date_range(开始日期,结束日期,周期数,频率),频率默认天D
dates = pd.date_range('20200101', periods=6)
dates
#%% 创建二维数据,有点像R语言的数据框
df = pd.DataFrame(np.random.randn(6,4),index=dates,columns=list('ABCD'))
df
#%% 通过字典来创建二维数据,体现了二维数据dataframe的异构
df2 = pd.DataFrame({'A': 1.,
'B': pd.Timestamp('20200101'),
'C': pd.Series(1, index=list(range(4)), dtype='float32'),
'D': np.array([3] * 4, dtype='int32'),
'E': pd.Categorical(["test", "train", "test", "train"]),
'F': 'foo'})
df2
df2.dtypes
# 查看数据前N行,默认前5行
df.head(n=3)
# 查看数据最后N行
df.tail(n=1)
# 显示索引
df.index
# 显示列名
df.columns
# 输出不带索引和列名的值
df.values
# 描述数据属性,参考R的summary()
df.describe()
# 数据转置
df.T
# 按照index排序,按照列的index降序排
# axis = 0 表示行轴,axis = 1 表示列轴
df.sort_index(axis=1,ascending=False)
# 按照行index降序排
df.sort_index(axis=0,ascending=False)
# 按照values排序
df.sort_values(by='A')# 指定A列排序
选择数据
#%%选择数据
print(df['A'],'\n',df.A) # 通过指定列名选择
df[0:3] # 切片 等效df['2020-01-01':'2020-01-03']
# select by label: loc
df.loc[dates[0]] # 通过标签来选 等效df.loc['2020-01-01']
df.loc[:,['A','C']] # 标签选择多列
df.loc['2020-01-02':'2020-01-04',['A','C']] # 标签切片,包含端点处
# select by position: iloc
df.iloc[3] # 选择第三行数据
df.iloc[:,1] # 选择第1列
df.iloc[1:3,1:2] # 不包含结束位置
df.iloc[[1, 2, 4], [0, 2]] # 用整数列表按位置切片
# mixed selection: ix 同时使用label和position筛选
df.ix[1:3,'A']
# boolean indexing
df[df.A > 0]
# 根据isin()筛选
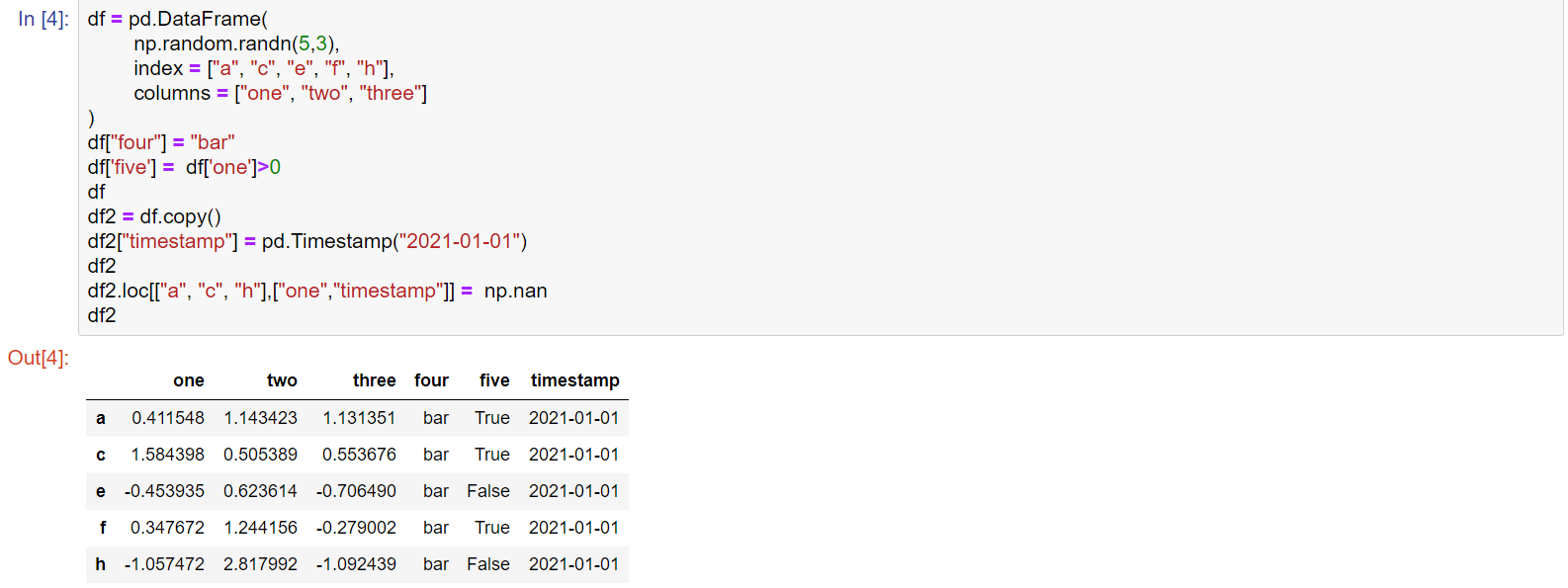
df3 = df.copy() # deep copy df
df3['E']=['on','two','three','four','five','two'] # 新增一列
df3[df3['E'].isin(['two','five'])] # 输出满足条件的数据
赋值
#%% 赋值
df.iloc[2,2]=100
print(df)
df.loc['2020-01-02','B']=120
print(df)
df.B[df.A>0]=1 # 满足A这列条件的B中数据
print(df.B)
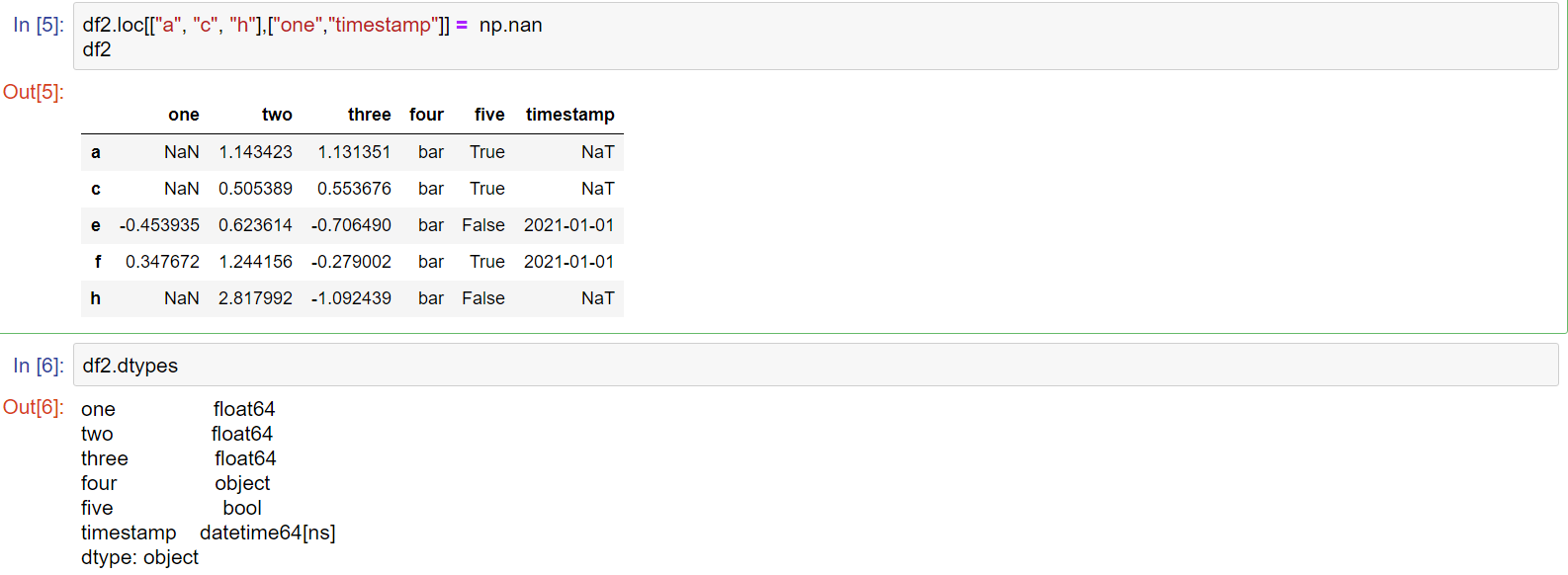
df2 = df.copy()
df2['F'] = pd.Series([1, 3, 5, np.nan, 6, 8],index=pd.date_range('2020-01-01',periods=6))
df2['E'] =[np.nan,2,3,5,8,10]
print(df2)
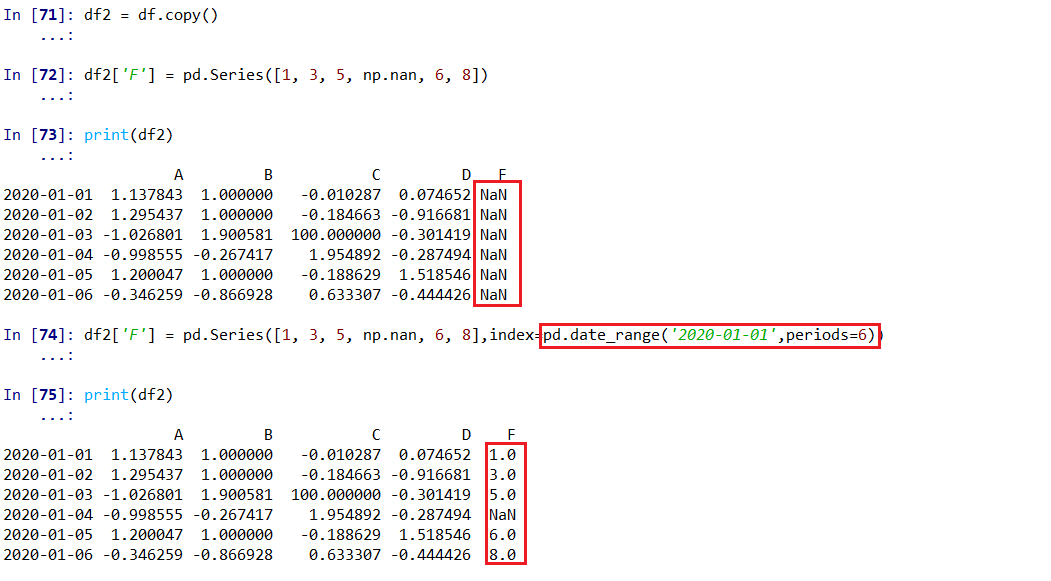
在使用Series对原有数据新增一列时,需要添加相同的row index!!!
缺失值
#%% 缺失值
# python 缺失值用np.nan表示,默认情况下,在计算中是会自动忽略。np.nan,数据类型float
# 删除缺失值 DataFrame.dropna
# how={'any','all'}
df2.dropna(axis=0,how='any') # 按照行,只要存在nan该行就删除
print(df2)
df2.dropna(axis=1,how='any') # 按照列,只要存在nan该列就删除
df2.dropna(axis=1,how='all') # 按照列,该列均为nan才删除
# 填充缺失值 DataFrame.fillna
print(df2.fillna(value=0))
# 识别缺失值 isna() notna()
print(df2.isna()) # 判断是否存在nan
print(df2.isnull())
注意:
-
python中 不能用来判断 nan 与 nan是否相等,但是 None 与 None却是相等的

-
时间型数据中缺失值显示为NaT
如何输出缺失值所在的行或列数据呢???
数据导入导出
pandas库中相应模块
导入:read_excel()、read_csv()
导出:to_excel()、to_csv()
pandas.read_excel(io, sheet_name=0, header=0, names=None
, index_col=None, usecols=None, squeeze=False
, dtype=None, engine=None, converters=None
, true_values=None, false_values=None
, skiprows=None # 设置跳过某一行
, nrows=None
, na_values=None
, keep_default_na=True
, na_filter=True, verbose=False
, parse_dates=False # 将某列解析为日期格式
, date_parser=None
, thousands=None, comment=None
, skipfooter=0, convert_float=True, mangle_dupe_cols=True, storage_options=None)
pandas.to_excel(excel_writer, sheet_name='Sheet1', na_rep=''
, float_format=None, columns=None, header=True
, index=True, index_label=None, startrow=0, startcol=0
, engine=None
, merge_cells=True # 是否合并单元格
, encoding=None, inf_rep='inf', verbose=True, freeze_panes=None, storage_options=None)
ExcelWriter(path,
engine, # str (optional)
date_format, # str, default None,设置日期格式 eg: YYYY-MM-DD
datetime_format, # str, default None,设置时间格式 e.g. ‘YYYY-MM-DD HH:MM:SS’
mode, # {‘w’, ‘a’}, default ‘w’,w表示每次写入一个新sheet中,a表示在同一个sheet中写入// 目前版本无该keyword argument
storage_options, # dict, optional
)
注意:若导出的数据含有时间,请提前将时间转换成str格式
# 所有数据导入到excel的同一个sheet
with pd.ExcelWriter(r'数据路径')as writer:
df1.to_excel(writer, sheet_name='data1')
df2.to_excel(writer, sheet_name='data1', startrow= 5)
#%% 分次读取各sheet
# read_csv/to_csv
data = pd.read_csv(r'D:\Users\ywango\Desktop\Test_IBU.csv',encoding='GB18030')
data.head(6)
data.head(6).to_csv(r'D:\Users\ywango\Desktop\Test.csv',encoding='GB18030')
data = pd.read_excel(r'D:\Users\ywango\Desktop\Test_IBU.xlsx',sheet_name='test1'
,parse_dates=['d']) # 将d列日期parse成日期格式
print(data.tail(5))
data.tail(5).to_excel(r'D:\Users\ywango\Desktop\mytest.xlsx')
# 指定将数据写入excel中的engine
data.tail(8).to_excel(r'D:\Users\ywango\Desktop\mytest1.xlsx',engine='xlsxwriter')
CSV文件默认不支持UTF-8编码格式,在文件中存在中文时候,如果使用函数read_csv()/to_csv()不进行encoding声明,会报错或者输出的中文为乱码!!!
如何将导出的数据日期只保留到天????
· pd.ExcelFile() 将 Excel 文件存储成 ExcelFile 对象
· ExcelFile.sheet_names 获取ExcelFile的所有sheet表的名称,存储在python列表中
#%% 读取一个工作薄中所有sheet
xlsx = pd.ExcelFile(r'D:\Users\Desktop\Test_IBU.xlsx')
sheetnames = xlsx.sheet_names # 产生所有sheet名的列表,test1,test2
print(sheetnames)
df = pd.read_excel(xlsx) # 默认返回第一个sheet的DataFrame
df = pd.read_excel(xlsx,sheet_name=None) # 返回所有sheet组成的字典DataFrame
df = pd.read_excel(xlsx,sheet_name=['test1',1])# 返回第1到第2个sheet组成的字典DataFrame
# 分开sheet读取
with pd.ExcelFile(r'D:\Users\ywango\Desktop\Test_IBU.xlsx') as xlsx:
df1 = pd.read_excel(xlsx,'test1')
df2 = pd.read_excel(xlsx,'IBU表')
print(df1.head(6))
print(df2.head(6))
数据合并

# concatenating
df1 = pd.DataFrame(np.ones((3,4))*0,columns=['a','b','c','d'])
df2 = pd.DataFrame(np.ones((3,4))*1,columns=['a','b','c','d'])
df3 = pd.DataFrame(np.ones((3,4))*2,columns=['a','b','c','d'])
print(df1)
print(df2)
print(df3)
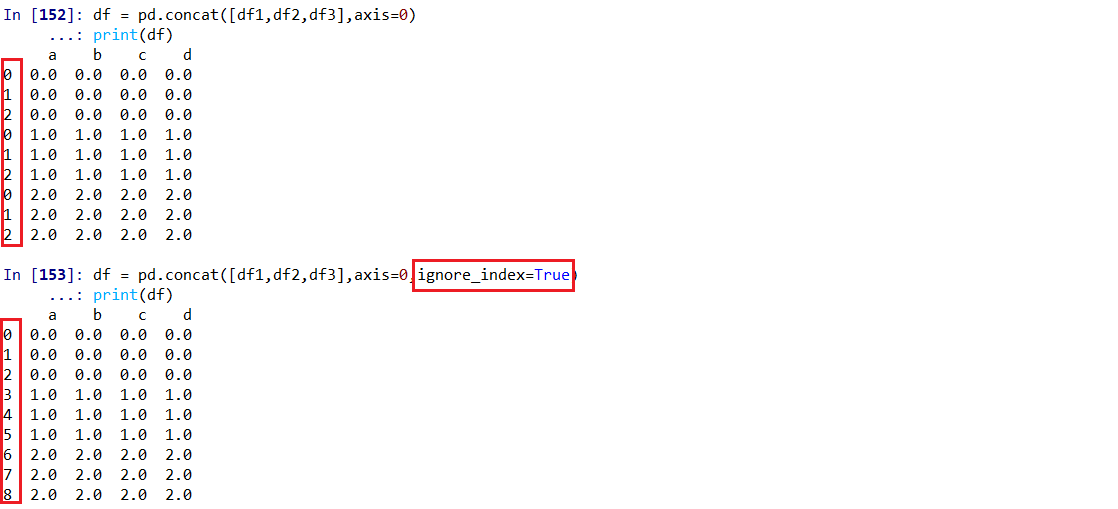
# concat(objs[对象],axis=0[默认垂直合并],join='outer'[默认外连接]
# ,join_axes[根据哪个对象的轴合并],ignore_index[默认F表示合并后对象使用原对象index])
df = pd.concat([df1,df2,df3],axis=0) # df1-3有相同的列名,按照行合并
print(df) # 行索引保留了原来各数据的
df = pd.concat([df1,df2,df3],axis=0,ignore_index=True)
print(df)
# join : 'outer'/'inner'
df1 = pd.DataFrame(np.ones((3,4))*0,columns=['e','b','c','d'],index=[2,3,4])
df2 = pd.DataFrame(np.ones((3,4))*1,columns=['a','b','d','k'],index=[3,1,4])
print(df1)
print(df2)
df = pd.concat([df1,df2],sort=False)# 不加sort=False会有警告,default axis=0,join='outer'
print(df)
# 等效于join='outer',把彼此缺失的部分以nan填充
df = pd.concat([df1,df2],join='outer',sort=False)
print(df)
df = pd.concat([df1,df2],join='inner',sort=False,ignore_index=True) #输出二者列名相同的数据
print(df)
# 以df1的行index为基准进行水平合并,df2中缺少的df1.index行数据nan填充
res = pd.concat([df1,df2],axis=1,join_axes=[df1.index])
print(res)
# 垂直填充
res = pd.concat([df1,df2],axis=0,join_axes=[df1.columns])
print(res)
# append 数据的最后追加一行
dt = pd.DataFrame(np.arange(12).reshape(3,4),columns=['A','B','C','D'])
s = pd.Series([1,1,1,1],index=['A','B','C','D'])
print(dt)
print(s)
res = dt.append(s,ignore_index=True)
print(res)

#%% merge,on可以一个条件,也可以多个条件
# how:{'outer','inner','left','right'}
right = pd.DataFrame({'key': ['foo', 'bad','col','goo'],
'rval': [4,5,0,2],
'col':[1,3,1,2]})
left = pd.DataFrame({'key': ['foo', 'bad','foo','goo'],
'lval': [1,2,3,4],
'col':[1,3,3,]})
print(left)
print(right)
print(pd.merge(left, right, on='key'))
#print(pd.merge(right,left,on='key'))
## 基于两个key进行合并,实际是看同样列名的相同数据合并
print(pd.merge(left,right,on=['key','col'],how='outer',indicator=True))
print(pd.merge(left,right,on=['key','col'],how='right',indicator='indicator_col'))# 默认以右边的参数为基准合并
print(pd.merge(left,right,on=['key','col'],how='left'))
## 基于index进行合并
left = pd.DataFrame({'A':[1,2,3,4,5],
'B':['b1','b2','b3','b4','b7']},
index=['K0','K1','K2','K3','K4'])
print(left)
right = pd.DataFrame({'C':['a1','b','b1','c','d1'],
'D':[2,13,9,0,4]},
index=['K0','K4','A1','K2','B0'])
print(right)
res = pd.merge(left,right,how='outer',left_index=True,right_index=True,indicator=True)
print(res)
# 当两个DataFrame列名一致时,进行合并时,如何区分哪个列来自哪个数据
city1 = pd.DataFrame({'k':[1,2,3,4],
'p':['a1','b1','c1','d1']})
print(city1)
city2 = pd.DataFrame({'k':[9,1,5,3],
'p':['A1','B1','C1','D1']})
print(city2)
res = pd.merge(city1,city2,on='k',suffixes=['_city1','_city2'],how='inner')
print(res)
可视化
#%%pandas数据可视化
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
# plot()
# 单一指标
data = pd.Series(np.random.randn(1000),index=np.arange(1000))
data = data.cumsum()
data.head()
data.plot()
plt.show()
# 多指标
data = pd.DataFrame(np.random.randn(1000,4),index=np.arange(1000),
columns=list('ABCD'))
data = data.cumsum()
data.head()
data.plot()
plt.show()
# scatter()
ax = data.plot.scatter(x='A',y='C',color='Orange',label='Type1')
data.plot.scatter(x='A',y='D',color='Green',label='Type2',ax=ax)
plt.show()
参考来源:
pandas中文参考文档:https://www.pypandas.cn/docs/getting_started/overview.html
pandas_excel操作指导:https://pandas.pydata.org/pandas-docs/stable/user_guide/io.html#excel-files
pandas导入csv文件中文乱码:https://blog.csdn.net/weicao1990/article/details/81316871
