淘宝购物车清空了吗?今天教你用Python爬虫来获取淘宝商品图文信息--要看一下吗?
首先需要先导入webdriver
from selenium import webdriver
webdriver支持主流的浏览器,比如说:谷歌浏览器、火狐浏览器、IE浏览器等等
然后可以创建一个webdriver对象,通过这个对象就可以通过get方法请求网站
![]()
![]()
接下来可以定义一个方法:search_product
一、selenium的简单介绍
1.selenium简介
selenium是一个用于测试网站的自动化测试工具,支持很多主流的浏览器,比如:谷歌浏览器、火狐浏览器、IE、Safari等。
2.支持多个操作系统
如windows、Linux、IOS、Android等。
3、安装selenium
打开终端输入
![]()
![]()
4、安装浏览器驱动
1、Chrome驱动文件下载: 点击下载谷歌浏览器驱动
2、火狐浏览器驱动文件下载: 点击下载geckodriver
5、配置环境变量
配置环境变量的方法非常简单,首先将下载好的驱动进行解压,放到你安装Python的目录下,即可。
因为之前,在配置Python环境变量的时候,就将Python的目录放到我的电脑–>属性–>系统设置–>高级–>环境变量–>系统变量–>Path

![]()
二、selenium快速入门
1、selenium提供8种定位方式
1、id
2、name
3、class name
4、tag name
5、link text
6、partial link text
7、xpath
8、css selector
2、定位元素的8中方式详解
| 定义一个元素 | 定位多个元素 | 含义 |
|---|---|---|
| find_element_by_id | find_elements_by_id | 通过元素的id定位 |
| find_element_by_name | find_elements_by_name | 通过元素name定位 |
| find_element_by_xpath | find_elements_by_xpath | 通过xpath表达式定位 |
| find_element_by_link_text | find_elements_by_link_text | 通过完整超链接定位 |
| find_element_by_partial_link_text | find_elements_by_partial_link_text | 通过部分链接定位 |
| find_element_by_tag_name | find_elements_by_tag_name | 通过标签定位 |
| find_element_by_class_name | find_elements_by_class_name | 通过类名进行定位 |
| find_element_by_css_selector | find_elements_by_css_selector | 通过css选择器进行定位 |
3、selenium库下webdriver模块常用的方法与使用
控制浏览器的一些方法
| 方法 | 说明 |
|---|---|
| set_window_size() | 设置浏览器的大小 |
| back() | 控制浏览器后退 |
| forward() | 控制浏览器前进 |
| refresh() | 刷新当前页面 |
| clear() | 清除文本 |
| send_keys (value) | 模拟按键输入 |
| click() | 单击元素 |
| submit() | 用于提交表单 |
| get_attribute(name) | 获取元素属性值 |
| text | 获取元素的文本 |
4、代码实例

![]()
关于selenium的简单介绍就先到这里了,更多详细内容大家可以去selenium官方文档查看。 点击查看selenium官方文档
爬取淘宝数据
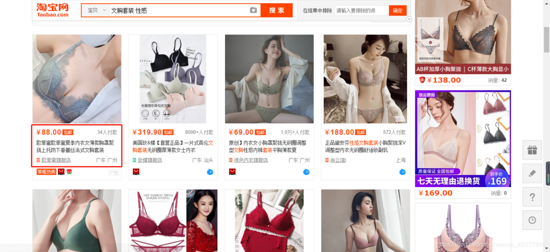
![]()
从上图,可以看到需要获取的信息是:价格、商品名称、付款人数、店铺名称。
现在我们开始进入主题。
首先,需要输入你要搜索商品的内容,然后根据内容去搜索淘宝信息,最后提取信息并保存。
1、搜素商品
我在这里定义提个搜索商品的函数和一个主函数。
搜索商品
在这里需要创建一个浏览器对象,并且根据该对象的 get方法 来发送请求。
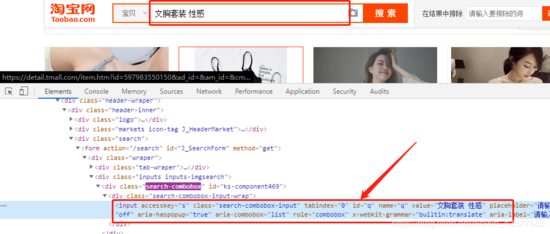
![]()
从上图可以发现搜索框的 id值为q
,那么这样就简单很多了,有HTML基础的朋友肯定知道id值是唯一的。
通过id值可以获取到文本框的位置,并传入参数,然后点击搜索按钮。
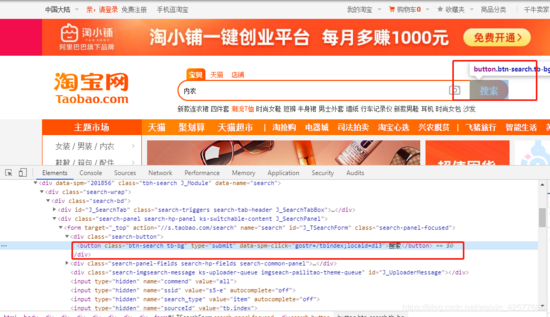
![]()
从上图可以发现搜索按钮在一个类里面,那么可以通过这个类来定位到搜索按钮,并执行点击操作。
当点击搜索按钮之后,网页便会跳转到登录界面,要求我们登录,如下图所示:
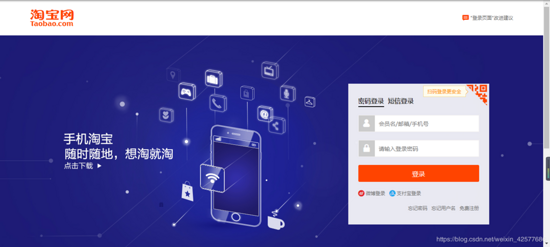
![]()
登录成功后会发现,里面的数据总共有100页面。

![]()
上图是前三页的url地址,你会发现其实并没有太大的变化,经过测试发现,真正有效的参数是框起来的内容,它的变化会导致页面的跳转,很明显第一页的s=0,第二页s=44,第三页s=88,以此类推,之后就可以轻松做到翻页了。
搜搜商品的代码如下:

![]()
2、获取商品信息并保存
获取商品信息相对比较简单,可以通过xpath方式来获取数据。在这里我就不在论述。在这边我创建了一个函数get_product来获取并保存信息。在保存信息的过程中使用到了csv模块,目的是将信息保存到csv里面。

![]()
3、构造URL实现翻页爬取
从上面的图片中可以发现连续三页URL的地址,其实真正变化并不是很多,经过测试发现,只有q和s两个参数是有用的。
构造出的url: s.taobao.com/search?q={}…
因为q是你要搜索的商品,s是设置翻页的参数。这段代码就放在了主函数里面

![]()
最后结果,如下图所示:
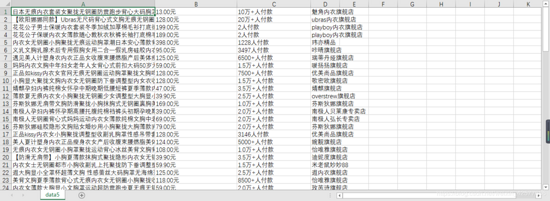
![]()
此文转载文,著作权归作者所有,如有侵权联系小编删除!
原文地址:https://www.tuicool.com/articles/6JVB3qQ
需要源代码或者想了解更多的(点击这里下载)

 浙公网安备 33010602011771号
浙公网安备 33010602011771号