王者英雄你喜欢那个!利用Python网络爬虫教你抓取喜欢的英雄图片!
3、对请求到的数据进行处理 3、对请求到的数据进行处理【一、项目背景】
王者荣耀作为当下最火的游戏之一,里面的人物信息更是惟妙惟肖,但受到官网的限制,想下载一张高清的图片很难。(图片有版权)。
以彼岸桌面这个网站为例,爬取王者荣耀图片的信息。

![]()
【二、项目目标】
实现将获取到的图片批量下载。
【三、涉及的库和网站】
1、网址如下:
![]()
![]()
2、涉及的库:requests、lxml
【四、项目分析】
首先需要解决如何对下一页的网址进行请求的问题。可以点击下一页的按钮,观察到网站的变化分别如下所示:

![]()
观察到只有index_()变化,变化的部分用{}代替,再用for循环遍历这网址,实现多个网址请求。
![]()
![]()
【五、项目实施】
1、我们定义一个class类继承object,然后定义init方法继承self,再定义一个主函数main继承self。准备url地址和请求头headers。

![]()
2、对网站发生请求。

![]()
3、对请求到的数据进行处理

![]()
4、在谷歌浏览器上,右键选择开发者工具或者按F12。
5、右键检查,找到图片二级的页面的链接,如下图所示。
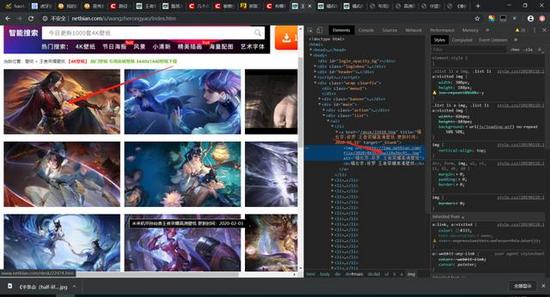
![]()
6、对二级页面发生请求,for遍历得到的网址。

![]()

![]()
7、将获取的图片写入文档,获取图片的title值作为图片的命名。

![]()
8、在main方法调用,如下所示。因为第一页的网址是没有规律的,所以这里先判断一下是不是第一页。

![]()
【六、效果展示】
1、运行程序,在控制台输入你要爬取的页数,如下图所示。
![]()
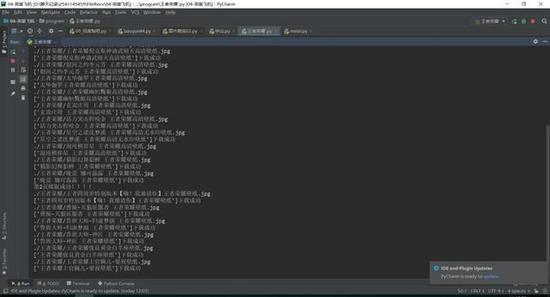
2、将下载成功的图片信息显示在控制台,如下图所示。
![]()
3、在本地可以看到效果图,如下图所示。

![]()
【七、总结】
1、不建议抓取太多数据,容易对服务器造成负载,浅尝辄止即可。
2、希望通过这个项目,能够帮助大家下载高清的图片。
3、本文基于Python网络爬虫,利用爬虫库,实现王者荣耀图片的抓取。实现的时候,总会有各种各样的问题,切勿眼高手低,勤动手,才可以理解的更加深刻。
4、英雄有很多,大家自行选择你喜欢的英雄做为你的桌面的壁纸吧。
此文转载文,著作权归作者所有,如有侵权联系小编删除!
原文地址:https://www.tuicool.com/articles/2aMZ3ua
需要源代码或者想了解更多点击这里下载

 浙公网安备 33010602011771号
浙公网安备 33010602011771号