在找工作吗?今天教你使用Python网络爬虫获取招聘信息!来体验一下
1.前言

![]()
现在在疫情阶段,想找一份不错的工作变得更为困难,很多人会选择去网上看招聘信息。可是招聘信息有一些是错综复杂的。而且不能把全部的信息全部罗列出来,以外卖的58招聘网站来看,资料整理的不清晰。
![]()
2.项目目标
获取招聘信息,并批量把地点、 公司名、工资 、下载保存在txt文档。
3.项目准备
软件:PyCharm
需要的库:requests、lxml、fake_useragent
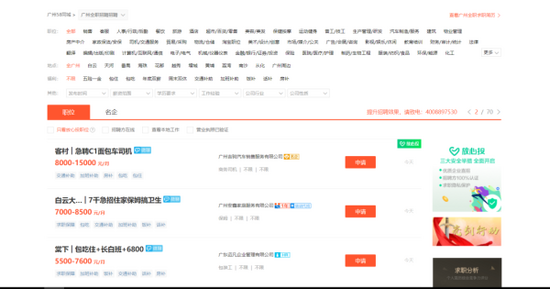
网站如下:

![]()
点击下一页时,ClickID={}每增加一页自增加1,用{}代替变换的变量,再用for循环遍历这网址,实现多个网址请求。
4.反爬措施
该网站上的反爬主要有两点:
1、 直接使用requests库,在不设置任何header的情况下,网站直接不返回数据
2、同一个ip连续访问多次,直接封掉ip,起初我的ip就是这样被封掉的。
为了解决这两个问题,最后经过研究,使用以下方法,可以有效解决。
1、获取正常的 http请求头,并在requests请求时设置这些常规的http请求头。
2、使用 fake_useragent ,产生随机的UserAgent进行访问。
5.项目实现
1、定义一个class类继承object,定义init方法继承self,主函数main继承self。导入需要的库和网址,代码如下所示。

![]()
2、随机产生UserAgent。

![]()
3、发送请求,获取响应, 页面回调,方便下次请求。

![]()
4、xpath解析找到对应的父节点。

![]()
5、for遍历,定义一个变量food_info保存,获取到二级页面对应的菜 名、 原 料 、下 载 链 接。

![]()
6、将结果保存在txt文档中,如下所示。

![]()
7、调用方法,实现功能。

![]()
6.效果展示
1、点击绿色小三角运行输入起始页,终止页。
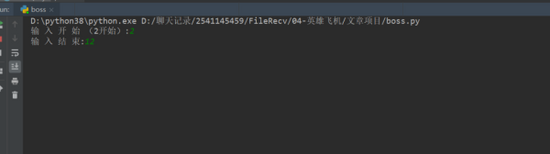
![]()
2、运行程序后,结果显示在控制台,如下图所示。
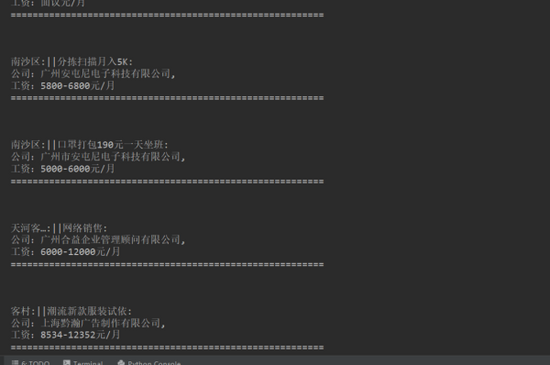
![]()
3、保存txt文档到本地,如下图所示。
![]()
4、双击文件,内容如下图所示。
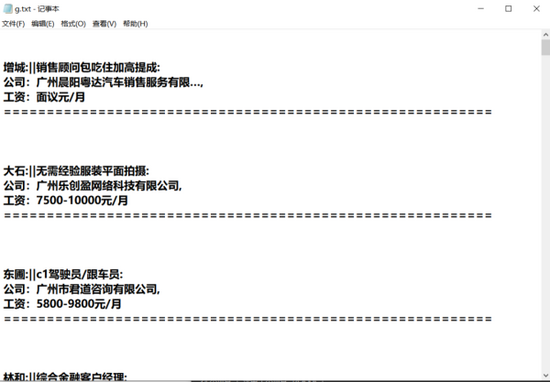
![]()
7.小结
1、不建议抓取太多数据,容易对服务器造成负载,浅尝辄止即可。
2、本文章就Python爬取招聘网,在应用中出现的难点和重点,以及如何防止反爬,做出了相对于的解决方案。
3、介绍了如何去拼接字符串,以及列表如何进行类型的转换。
4、代码很简单,希望能够帮到你。
5、欢迎大家积极尝试,有时候看到别人实现起来很简单,但是到自己动手实现的时候,总会有各种各样的问题,切勿眼高手低,勤动手,才可以理解的更加深刻。
6、可以选择自己喜欢的分类,获取工作,找到自己喜欢工作。
此文转载文,著作权归作者所有,如有侵权联系小编删除!
原文地址:https://www.tuicool.com/articles/euQze27
需要源代码的点击这里下载

 浙公网安备 33010602011771号
浙公网安备 33010602011771号