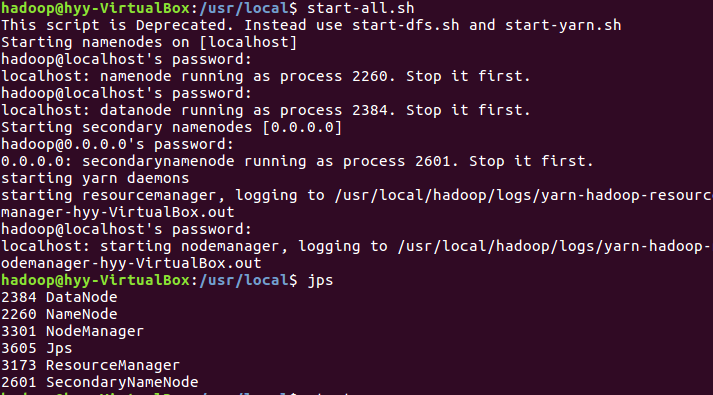
启动hadoop:
usr/local$ start-all.sh
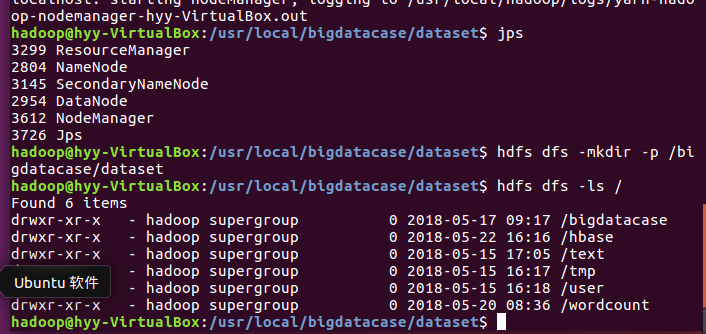
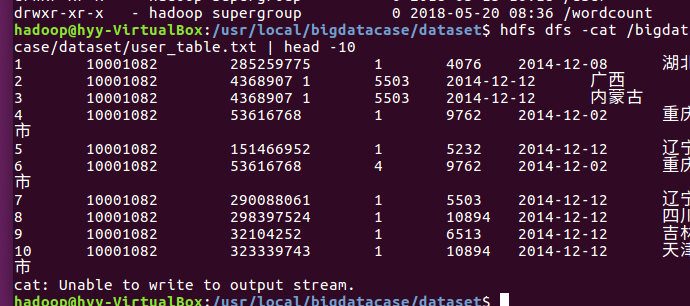
在hdfs分布式系统下创建一个文档并把数据导入:
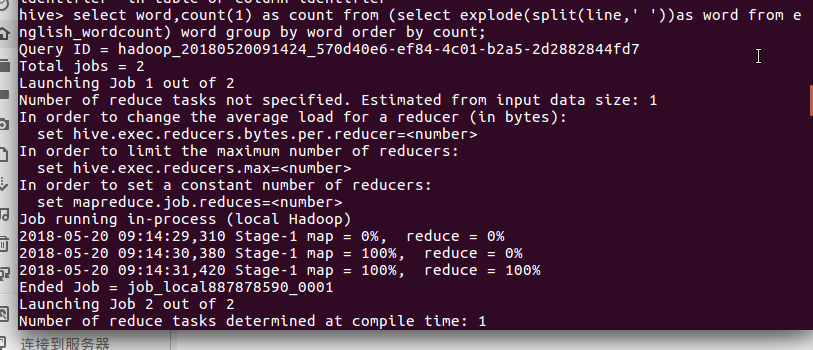
启动hive并导入数据:
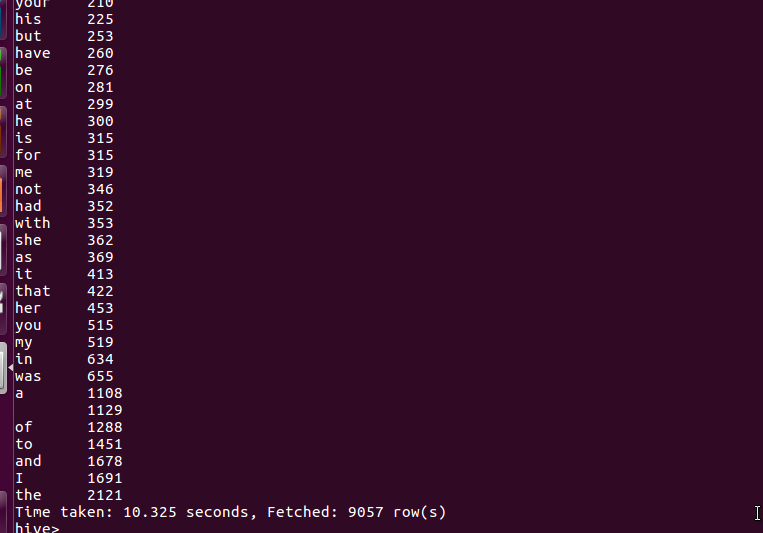
词频统计结果如下:
2.用Hive对爬虫大作业产生的csv文件进行数据分析,写一篇博客描述你的分析过程和分析结果。