Redis 的多个数据库
Redis 默认提供了16个数据库. 每个数据库都有一个id, 从 0 开始, [0,15]。 不同的数据库中数据隔离保存。我们可以通过修改redis的配置文件进行修改数据库的数量。
database 32
- 使用
select <ID>可以切换数据库.
示例如下:
127.0.0.1:6379> select 1
OK
# 演示数据隔离
127.0.0.1:6379[1]> set test 1
OK
127.0.0.1:6379[1]> select 2
Ok
127.0.0.1:6379[2]> get test
(nil)
可以通过命令之前的部分区分我们所在的数据库.
127.0.0.1:6379[2]> select 2执行这个命令的时候,我们是在数据库1中的。
- 使用
flushdb只能删除 该数据库(一个库) 中的数据。 - 使用
flushall可以删除 所有库 中的数据。
redis使用分库的意义
- 避免不同应用相同
key的影响。 - 更便于管理。
一个实例上运行多个库,只运维这一个实例就可以了。 - 也有不少文章说, redis的作者曾说过, “多数据库的设计可能是最糟糕的决定.”. Redis是单线程的,即使是多数据库也不会带来性能提升. 但是这个并没有和前面的两个好处冲突. 下面是作者的原话:
I understand how this can be useful, but unfortunately I consider Redis multiple database errors my worst decision in Redis design at all… without any kind of real gain, it makes the internals a lot more complex. The reality is that databases don’t scale well for a number of reason, like active expire of keys and VM. If the DB selection can be performed with a string I can see this feature being used as a scalable O(1) dictionary layer, that instead it is not.
With DB numbers, with a default of a few DBs, we are communication better what this feature is and how can be used I think. I hope that at some point we can drop the multiple DBs support at all, but I think it is probably too late as there is a number of people relying on this feature for their work.
Redis的分库是怎么实现?
Redis服务器间所有的数据库都保存在 服务器状态 redis.h/redisServer结构的db数组中。db数组中的每个元素都是一个 redis.h/redisDb结构. 每个redisDb结构代表一个数据库.
struct redisServer {
// 保存所有数据库
redisDb *db;
// 数据库的数量(redis.conf文件中 database配置的)
int dbnum;
}
每个Redis客户端都有自己的目标数据库,每个客户端执行数据库写命令或者数据库读命令的时候,目标数据库都会成为这些命令的操作对象.
每个客户端用 RedisClient 来描述。 RedisClient结构的db属性记录了客户端当前的目标数据库,这个属性是一个指向 redisDb 的指针.
typedef struct redisClient {
// 记录客户端端正在使用的数据库id
redisDb *db;
} redisClient;
举个例子:
假设我们客户端连接的是数据库1,那么客户端与服务器端之间的关系是这样的:
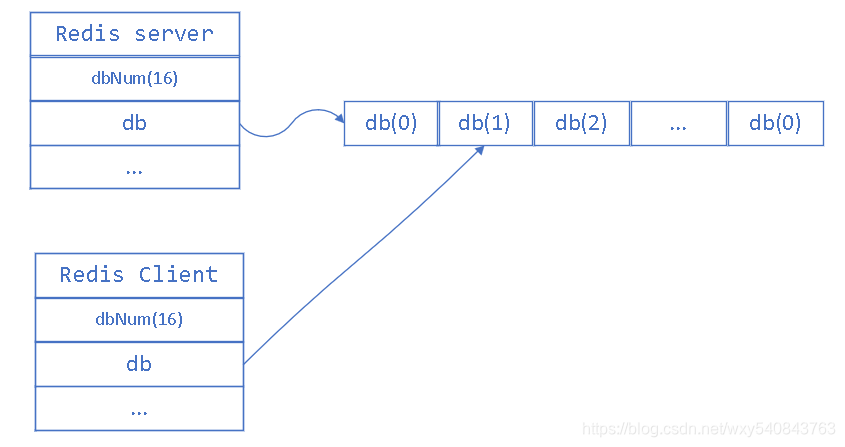
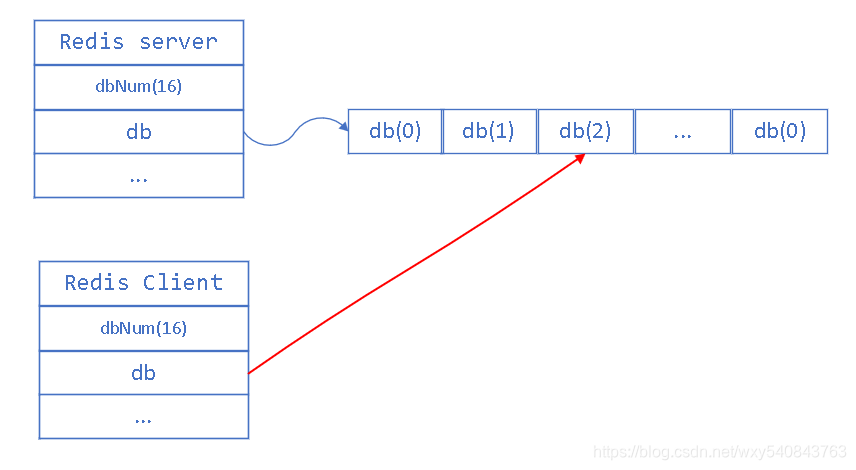
如果我们运行 select 2, 其实,就是改变的db的指针。让它指向了 db(2),这就是 select 命令的运行原理. 如下图。
以上就是 关于 Redis 多数据库的内容了。
最后
希望和你成为朋友!我们一起学习~
最新文章尽在公众号【方家小白】,期待和你相逢在【方家小白】


