【深度学习 - 吴恩达】L2W3作业
本文为吴恩达 Deep Learning 作业,Tensorflow
Tensorflow
-
在TensorFlow中编写和运行程序包含以下步骤:
- 创建尚未执行的张量 (变量)。
- 在这些张量之间编写操作。
- 初始化张量。
- 创建一个会话。
- 运行会话,这将运行你上面编写的操作。
-
由于版本不同,这是一个可以在我的电脑运行的代码。
import numpy as np
import tensorflow as tf
np.random.seed(1)
tf.compat.v1.disable_eager_execution()
def main():
y_hat = tf.constant(36, name='y_hat')
y = tf.constant(39, name='y')
loss = tf.Variable((y - y_hat)**2, name='loss')
init = tf.compat.v1.global_variables_initializer()
with tf.compat.v1.Session() as session:
session.run(init)
print(session.run(loss))
if __name__ == '__main__':
main()
使用 Tensorflow 构建神经网络
模型
模型结构:
3 层神经网络:
LINEAR-> RELU-> LINEAR-> RELU-> LINEAR-> SOFTMAX。
创建占位符
- 占位符是一个对象,稍后将指定其值。
- 要为占位符指定值,可以使用
feed_dict。
def create_placeholders(n_x, n_y):
X = tf.compat.v1.placeholder(shape=[n_x, None], dtype=tf.float32)
Y = tf.compat.v1.placeholder(shape=[n_y, None], dtype=tf.float32)
return X, Y
初始化
tf.get_variable(name, shape, initializer)
name是变量名称,shape是变量维度,initializer是变量初始化方式。
def initialize_parameters():
tf.compat.v1.set_random_seed(1)
W1 = tf.compat.v1.get_variable("W1", [25, 12288],
initializer=tf.initializers.GlorotUniform(seed=1))
b1 = tf.compat.v1.get_variable("b1", [25, 1], initializer=tf.zeros_initializer())
W2 = tf.compat.v1.get_variable("W2", [12, 25],
initializer=tf.initializers.GlorotUniform(seed=1))
b2 = tf.compat.v1.get_variable("b2", [12, 1], initializer=tf.zeros_initializer())
W3 = tf.compat.v1.get_variable("W3", [6, 12],
initializer=tf.initializers.GlorotUniform(seed=1))
b3 = tf.compat.v1.get_variable("b3", [6, 1], initializer=tf.zeros_initializer())
parameters = {"W1": W1, "b1": b1, "W2": W2, "b2": b2, "W3": W3, "b3": b3}
return parameters
向前传播
def forward_propagation(X, parameters):
W1 = parameters['W1']
b1 = parameters['b1']
W2 = parameters['W2']
b2 = parameters['b2']
W3 = parameters['W3']
b3 = parameters['b3']
Z1 = tf.add(tf.matmul(W1, X), b1) # Z1 = np.dot(W1, X) + b1
A1 = tf.nn.relu(Z1) # A1 = relu(Z1)
Z2 = tf.add(tf.matmul(W2, A1), b2) # Z2 = np.dot(W2, a1) + b2
A2 = tf.nn.relu(Z2) # A2 = relu(Z2)
Z3 = tf.add(tf.matmul(W3, A2), b3) # Z3 = np.dot(W3, A2) + b3
return Z3
计算代价
tf.nn.sigmoid_cross_entropy_with_logits(logits = ..., labels = ...)用于求交叉熵。
def compute_cost(Z3, Y):
logits = tf.transpose(Z3)
labels = tf.transpose(Y)
cost = tf.reduce_mean(tf.nn.softmax_cross_entropy_with_logits(logits=logits, labels=labels))
return cost
整合
- 创建一个
optimizer"对象,运行tf.session时,与损失一起调用此对象,调用时,它将使用所选方法和学习率对给定的损失执行优化。
def model(X_train, Y_train, X_test, Y_test, learning_rate=0.0001, num_epochs=1500, minibatch_size=32, print_cost=True):
ops.reset_default_graph()
tf.compat.v1.set_random_seed(1)
seed = 3
(n_x, m) = X_train.shape
n_y = Y_train.shape[0]
costs = []
X, Y = create_placeholders(n_x, n_y)
parameters = initialize_parameters()
Z3 = forward_propagation(X, parameters)
cost = compute_cost(Z3, Y)
optimizer = tf.compat.v1.train.AdamOptimizer(learning_rate=learning_rate).minimize(cost) # 重点
init = tf.compat.v1.global_variables_initializer()
with tf.compat.v1.Session() as sess:
sess.run(init)
for epoch in range(num_epochs):
epoch_cost = 0.
num_minibatches = int(m / minibatch_size)
seed = seed + 1
minibatches = random_mini_batches(X_train, Y_train, minibatch_size, seed)
for minibatch in minibatches:
(minibatch_X, minibatch_Y) = minibatch
_, minibatch_cost = sess.run([optimizer, cost], feed_dict={X: minibatch_X, Y: minibatch_Y}) # 重点
epoch_cost += minibatch_cost / num_minibatches
if print_cost is True and epoch % 100 == 0:
print("Cost after epoch %i: %f" % (epoch, epoch_cost))
if print_cost is True and epoch % 5 == 0:
costs.append(epoch_cost)
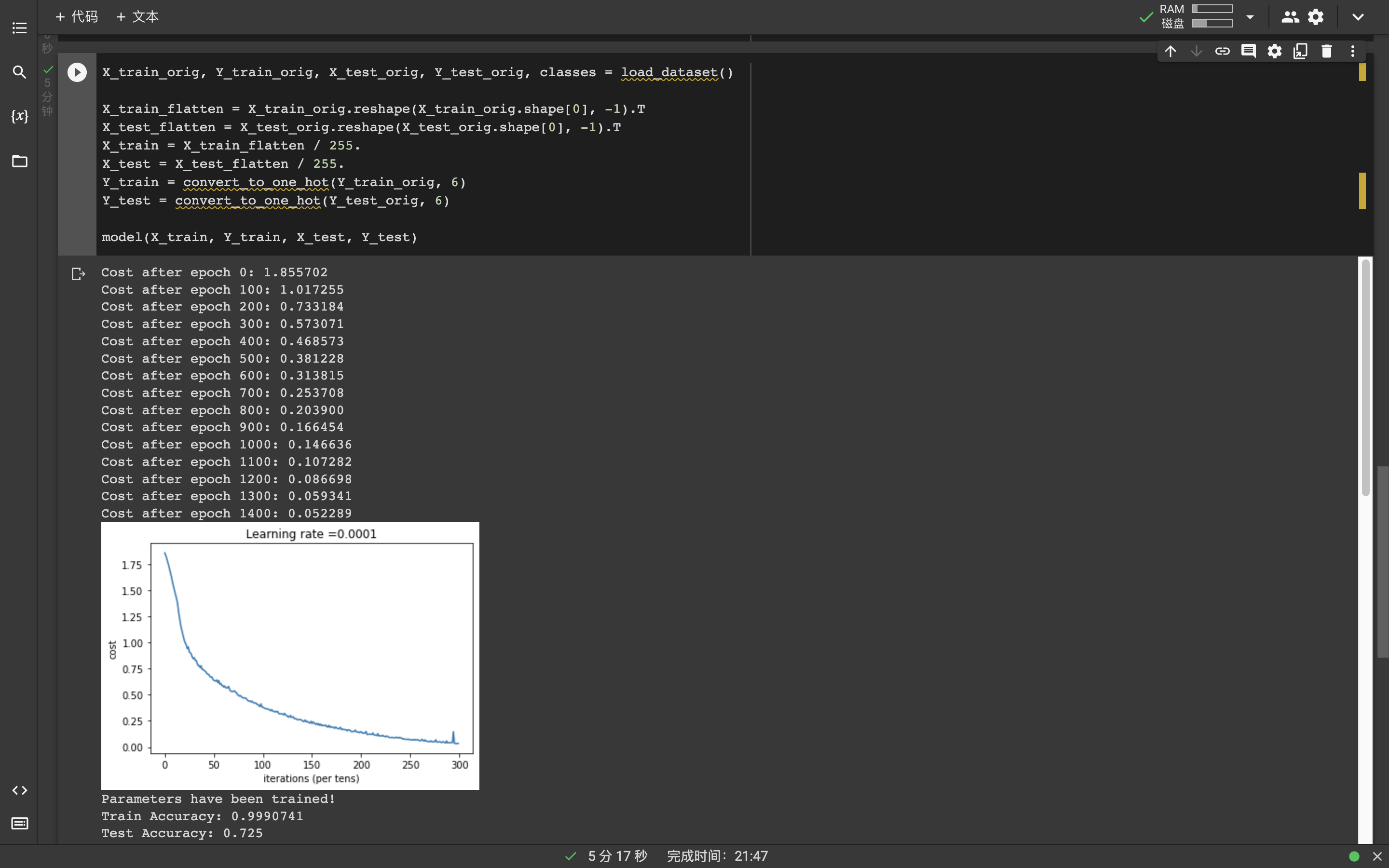
plt.plot(np.squeeze(costs))
plt.ylabel('cost')
plt.xlabel('iterations (per tens)')
plt.title("Learning rate =" + str(learning_rate))
plt.show()
parameters = sess.run(parameters)
print("Parameters have been trained!")
correct_prediction = tf.equal(tf.argmax(Z3), tf.argmax(Y))
accuracy = tf.reduce_mean(tf.cast(correct_prediction, "float"))
print("Train Accuracy:", accuracy.eval({X: X_train, Y: Y_train}))
print("Test Accuracy:", accuracy.eval({X: X_test, Y: Y_test}))
return parameters
main 函数:
def main():
X_train_orig, Y_train_orig, X_test_orig, Y_test_orig, classes = load_dataset()
X_train_flatten = X_train_orig.reshape(X_train_orig.shape[0], -1).T
X_test_flatten = X_test_orig.reshape(X_test_orig.shape[0], -1).T
X_train = X_train_flatten / 255.
X_test = X_test_flatten / 255.
Y_train = convert_to_one_hot(Y_train_orig, 6)
Y_test = convert_to_one_hot(Y_test_orig, 6)
model(X_train, Y_train, X_test, Y_test)
CoLab
- CoLab 是个好东西,咕咕咕~


【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· 阿里最新开源QwQ-32B,效果媲美deepseek-r1满血版,部署成本又又又降低了!
· AI编程工具终极对决:字节Trae VS Cursor,谁才是开发者新宠?
· 开源Multi-agent AI智能体框架aevatar.ai,欢迎大家贡献代码
· Manus重磅发布:全球首款通用AI代理技术深度解析与实战指南
· 被坑几百块钱后,我竟然真的恢复了删除的微信聊天记录!