【深度学习 - 吴恩达】05 序列模型
本文为吴恩达 Deep Learning 笔记
循环神经网络
基本概念
序列模型的应用:
- 语音识别、音乐生成、情感分析、DNA 序列分析、机器翻译、视频动作识别、命名实体识别。
数学符号:
One-hot 独热码
- 符号:
- 输入序列的第 个元素 ,输出序列的第 个元素 。
- 输入序列的长度 ,输出序列的长度 。
- 第 个输入样本第 个位置的元素 ,第 个输出样本第 个位置的元素 。
- 第 个输入样本的长度 ,第 个输出样本的长度 。
- 词汇表:
- 假设词汇表中有 个单词,则词汇表是 维列向量,每个单词对应唯一索引。
- 输入序列的每个单词 是一个向量,大小与词汇表一致,采用独热码,其中只有单词的索引位置为 ,其他位为 。
- 当出现词汇表中不存在的单词时,可用 表示。

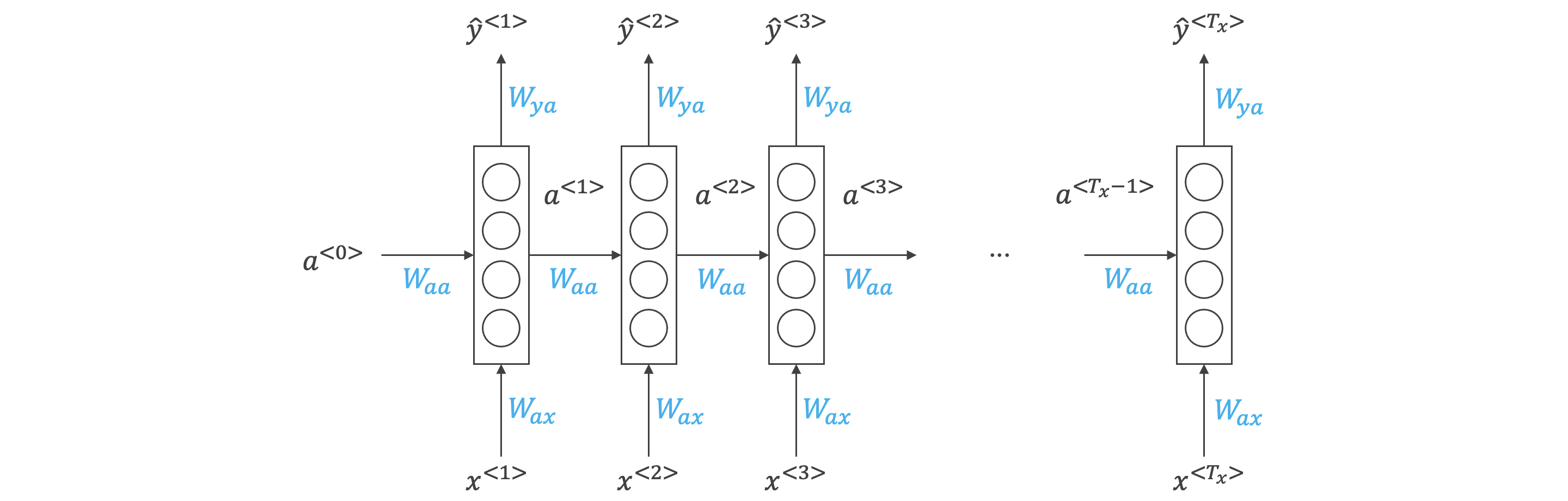
循环神经网络:
Recurrent Neural Network 循环神经网络
- 对于序列模型,如果使用标准神经网络:
- 不同样本的输入序列长度或输出序列长度不同,模型难以统一。
- 标准神经网络结构无法共享序列不同之间的特征。
-
正向传播:
整合:
-
RNN 按照从左到右顺序,单向进行,只与左边的元素有关。
反向传播:
Backpropagation through time 基于时间的反向传播算法
-
损失函数:
-
单个元素:
-
所有元素:
-
不同类型的循环神经网络:
- One To One:标准神经网络。
- One To Many:音乐生成。
- Many To One:情感分析
- Many To Many:
- 输入输出数量相同:命名实体识别。
- 输入输出数量不同:机器翻译。
语言模型
语言模型和序列生成:
- 语言模型会计算出语句出现的概率:基于字典库,通过句子前面的输入预测该位置各个单词出现的概率,最后将各个位置单词的概率相乘得到句子的概率。
- 使用 RNN 构建语言模型:
- 一个足够大的训练集,由大量的单词语句语料库 (corpus) 构成。
- 对语料库的每句话进行切分词 (tokenize),做法与《数学符号》一节相同,建立字典,对每个单词进行独热编码。
- 作为语句结束符, 代表字典中没有该单词。
- 输入 的输出 是第 位置的单词 产生激活值 ,再使用 softmax 产生的,这个概率值是基于前面所有 个单词的概率值。
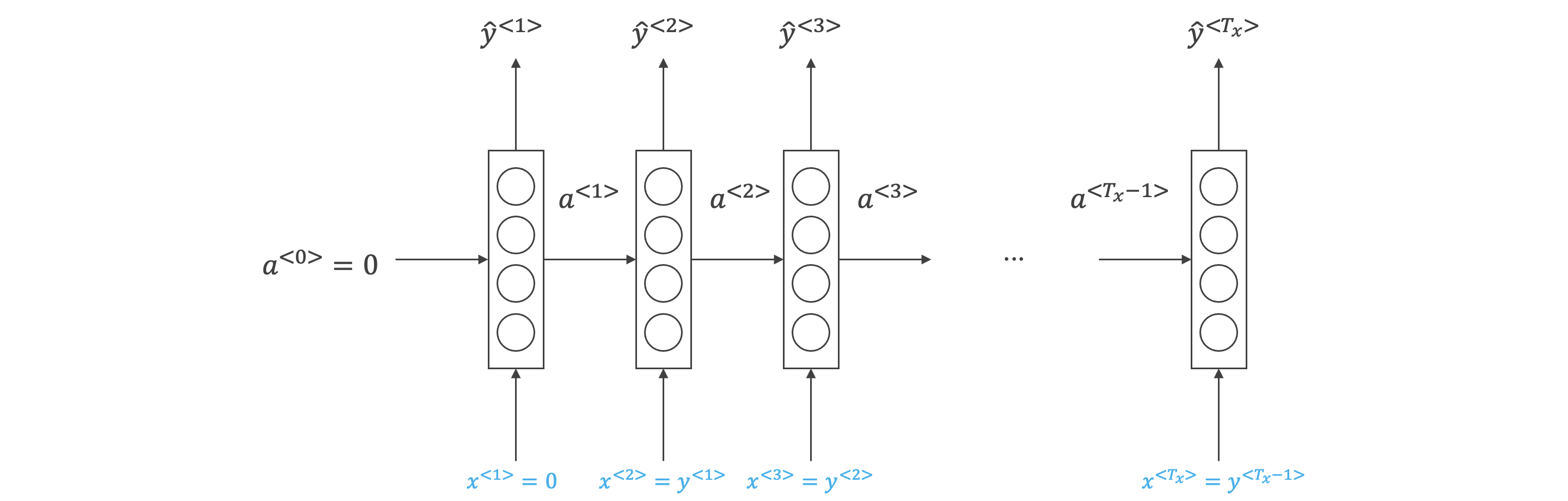
对新序列采样:
Word Level RNN 字级 RNN
Character Level RNN 字符级 RNN
- 训练完一个语言模型后,我们想知道模型学到了什么,可以从该模型中进行一次新序列采样来观察模型学到的知识。采样的过程就是根据模型预测第一个单词是什么,然后根据第一个单词预测第二个单词是什么,以此类推。
- 字级 RNN,词汇表来自英文词汇;字符级 RNN,词汇表来自英文字母和必要的一些符号。
- 字符级 RNN 不必担心未知序列,计算更加复杂。
梯度消失
带有神经网络的梯度消失:
Gradient Clipping 梯度裁剪
-
语句中可能存在跨度很大的依赖关系,即某个单词可能与它距离较远的某个单词具有强依赖关系。传统的RNN 模型并不能很好地捕捉长期依赖关系。
梯度消失:一个非常深的神经网络,从输出 得到的梯度,很难反向传播影响前期层的计算。
-
RNN 中也可能出现梯度爆炸,常用的解决办法是设定一个阈值,一旦梯度最大值达到这个阈值,就对整个梯度向量进行尺度缩小。这种做法被称为梯度裁剪。
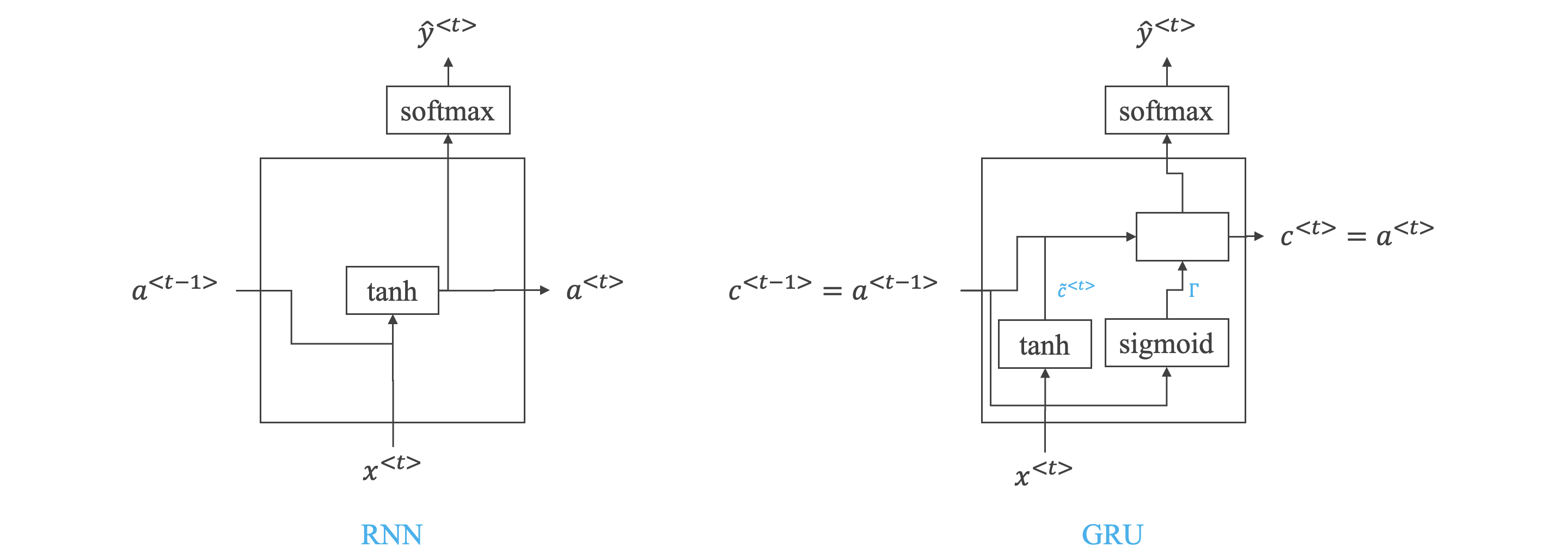
GRU 单元:
Gated Recurrent Unit 门控循环单元
-
GRU 是解决梯度消失的一种方法。
-
公式:
- 记忆区 ,在每一个时间点,尝试使用 去覆盖原有的 。
- 门限 ,值为 或 ,代表更新是否会被执行。
- 门限 ,值为 或 ,代表上一个时间点的记忆区和现在的记忆区候选值之间的相关程度。
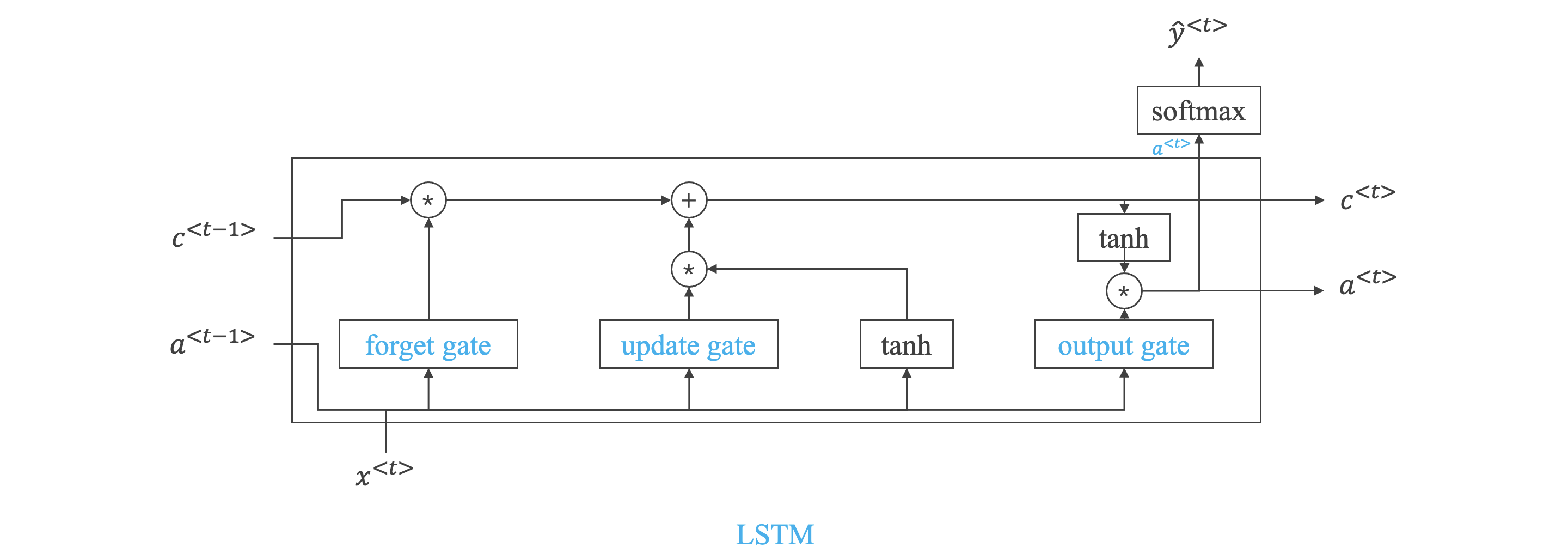
LSTM:
Long Short Term Memory 长短期记忆
Peephole Connection 窥孔连接
-
LSTM 是解决梯度消失的一种方法。
-
公式:
- 与 GRU 一个主要区别就是,不再出现 的情况。
- 对于记忆区的更新,不再使用单一门限值 ,引入一个新变量:遗忘门限值 ,相比于 GRU 的两个门限值,LSTM 存在三个门限值用于决定输出和记忆的更新。
- 一种变体,称为窥孔连接 (Peephole Connection),即在计算门限值时,不仅考虑上一个时间单元的激活输出 和当前时间单元的输入 ,同时还要考虑上一个单元的记忆输出 。
更多模型
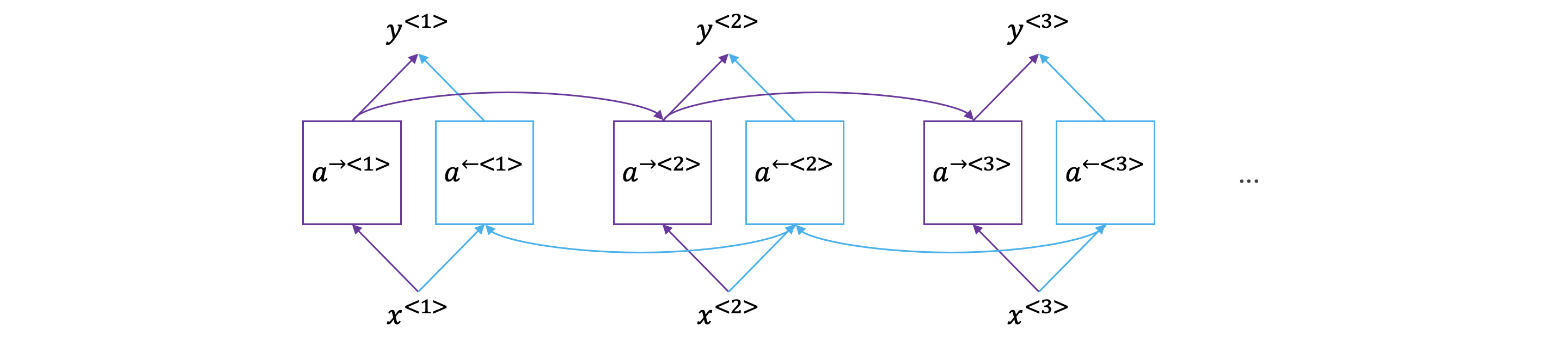
双向神经网络:
Bidirectional RNN 双向神经网络
-
双向 RNN 在每一个时间点都增加了一个后向递归层,从最右一个时间点开始向最开始的时间点进行类似正向的递归过程。
-
在每一个时间节点,同时存在来自两个方向的激活值,此时的输出将会由两个方向的激活值同时决定。
-
对于每一个时间点,其既能收到来自过去信息的影响,同时还能收到来自未来信息的影响。
-
公式:。
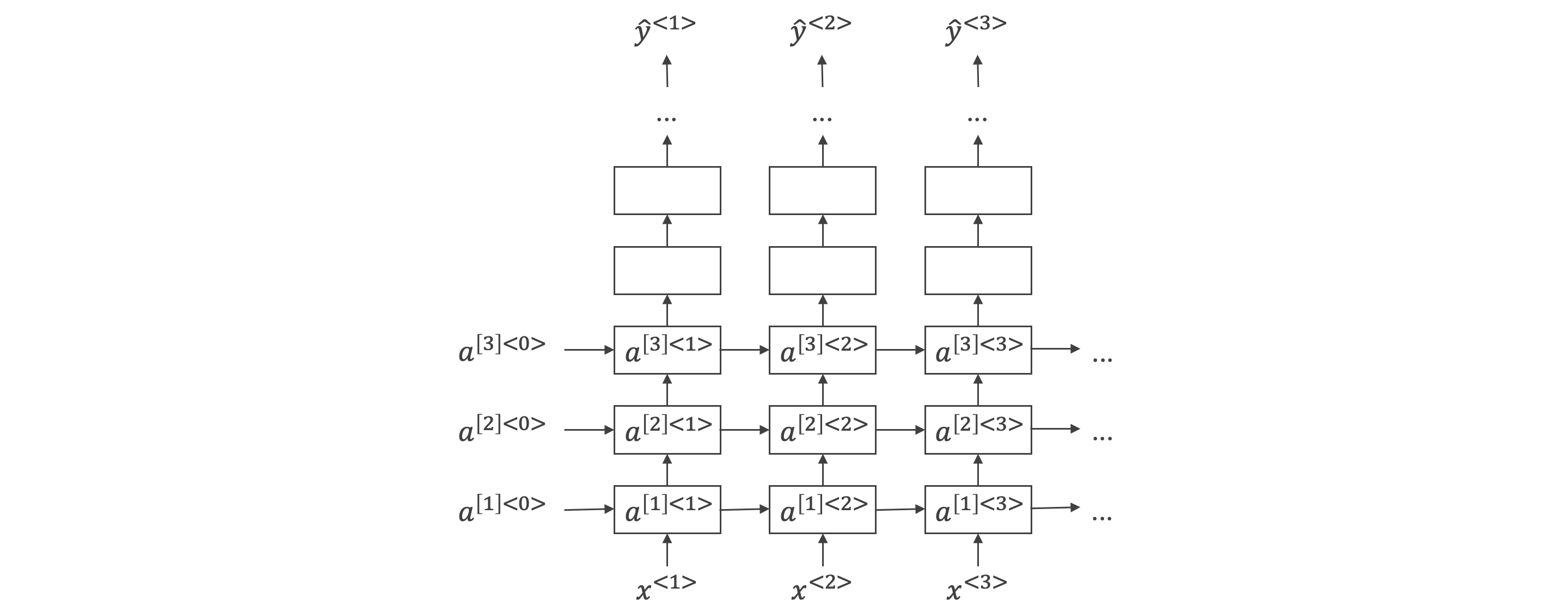
深层循环神经网络:
Deep RNNs 深层循环神经网络
-
基于传统 RNN 结构,每一个时间点的处理结构从一个变成了多个,并最终得到此时间节点的输出。
-
公式:。
NLP 和词向量
词向量
词向量:
Word Embedding 词向量
- 独热码表示单词的缺点:每个单词是独立的、正交的,无法知道不同单词之间的相似程度。
- 词向量:
- 用多个不同的特征来对各个词汇进行表征,每个单词对于每个特征都有一个相关特征值,多个特征的特征值组成单词的特征向量。
- 每个单词用 的方式标记。
- 相似的词的特征向量就比较接近,可以获取词与词之间的相似性和关联性。
- 特征向量并不一定具有物理意义,是比较抽象的。
- t-SNE:降维算法,可以将多维特征向量映射到二维,以直观展示。
使用词向量:
- 词向量迁移学习的步骤:
- 从大量的文本集合中学习词向量,或者从网上下载预训练好的词向量模型。
- 将词向量模型迁移到我们小训练集的新任务上。
- 使用我们新的标记数据对词向量模型继续进行微调 (可选)。
词向量的特性:
-
词向量可以实现类比推理,通过不同词向量之间的相减计算,可以发现不同词之间的类比关系。
- 如:man - woman / king - queen。
- 注意:这种类比关系在使用 t-SNE 降维后将不存在,因为 t-SNE 是复杂的非线形的算法。
-
距离相似度:
-
向量相减:。
-
利用相似函数,计算与 相似度最大的 即为所求。
-
相似函数:
-
嵌入矩阵
嵌入矩阵:
Embedding Matrix 嵌入矩阵
- 公式:。
- 嵌入矩阵 ,单词 的独热码 。
- 为嵌入矩阵的第 列。
词向量的算法:
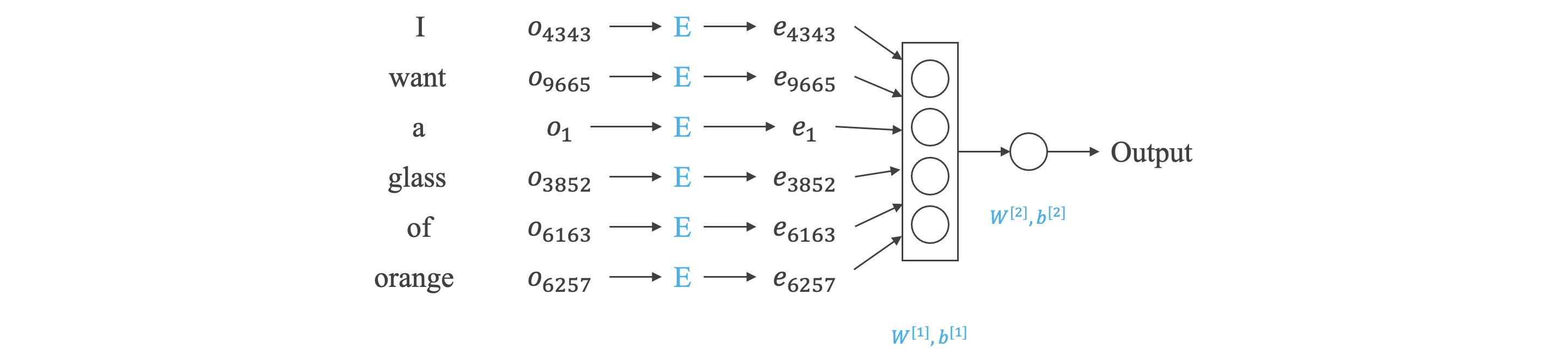
- 为求嵌入矩阵 ,可构建语言模型。
- 例如:I want a glass of orange juice.
- 输出 (target):juice。
- 输入 (context) 选择 target 的前 个单词 (这里的 是超参数):a glass of juice。
- 其中 、、、、 是待求值。
- 例如:I want a glass of orange juice.
Word2Vec:
Hierarchical Softmax Classifier 树形分类器
-
Word2Vec 是一种计算词向量的方法,在具体计算时可使用不同模型,本节介绍了 Skip-Gram 模型。
-
算法流程:
- 随机选择一个单词作为 context。
- 使用一个自定义宽度的滑动窗口,在 context 附近选择一个单词作为 target。
- 得到了多个 context - target 对作为监督式学习样本。
- 构建自然语言模型。
-
公式 (假设词汇表中有 个单词):
-
的输出, 为参数, 为 context 的嵌入矩阵。
-
损失函数:
-
-
单元中计算量大,解决方法之一是使用树形分类器 (Hierarchical Softmax Classifier)
- 树形分类器减少计算量的原理类似二分查找。
- 树形分类器是非对称的,通常选择把比较常用的单词放在树的顶层,而把不常用的单词放在树的底层。
-
对于 context 的选择,一般不选择随机均匀采样,因为我们更关心 orange, apple 而非 the, a, of。
负采样:
Negative Sampling 负采样
-
Skip-Gram 模型中 单元中计算量大,负采样可以减少计算量,是另一种计算词向量的方法。
-
算法流程:
- 选定 context。
- 选取 target,标记为 。
- 在字典中选取 个词,标记为 ,作为负样本。
-
公式:。
- 将 个输出单元的 分类 (假设词汇表中有 个单词) 转换为 个二分类。
-
负样本的选取方法:
- 不能完全随机或完全按照单词出现频率选取,论文中给出二者折中,, 表示单词 的出现概率。
- 不能完全随机或完全按照单词出现频率选取,论文中给出二者折中,, 表示单词 的出现概率。
GloVe 词向量:
-
是一种计算词向量的方法。
-
损失函数:
- 表示 和 同时出现的次数。
- 表示权重因子,当 时 ,解决 无意义的问题; 对出现频率较小的单词和出现频率较大的单词起着平衡作用。
- 参数 和 是对称的,最后 。
-
其实没看懂,咕咕咕~
词向量的应用
情绪分类:
- 平均值:
- 求出每个单词的 ,然后取平均值。
- 问题:没有考虑词序,"Completely lacking in good taste, good service, and good ambience." 会被认为是好评。
- RNN:
- 求出每个单词的 ,使用 Many To One RNN。
词向量消除偏见:
- 消除偏见的方法:
- 定义偏见的方向,如性别:
- 对大量性别相对的词汇进行相减并求平均:。
- 得到一个或多个偏见相关的维度 (Bias Direction),以及大量不相关的维度 (Non-bias Direction)。
- 中和化:对每一个定义不明确的词汇 (如 docter, nurse) 调整到偏见相关维度的距离中轴线上。
- 均衡化:将定义明确的男女成对的词 (如 gradmother, gradfather) 调整到偏见相关维度的距离中轴线对应的位置。
- 定义偏见的方向,如性别:
序列模型和注意力机制
基础模型
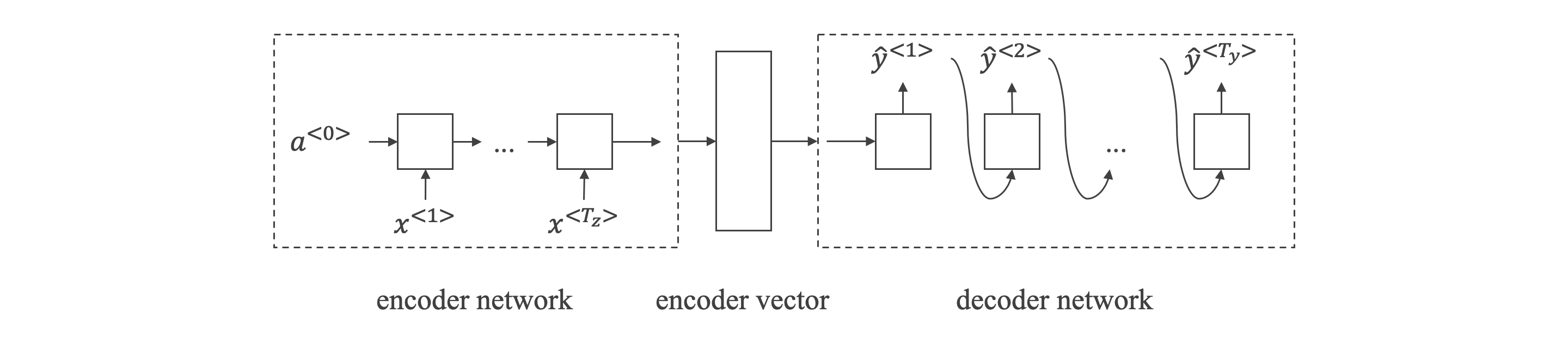
基础模型:
- 对于机器翻译问题,可以使用 "编码网络 (encoder network)" + "解码网络 (decoder network)" 两个RNN模型组合的形式来解决。
选择最可能的句子:
Greedy Search 贪心搜索
-
语言模型与机器翻译:
-
语言模型生成一个随机的完整的语句;机器翻译根据输入语句,生成一个完整的语句。
-
机器翻译由 encoder network 和 decoder network 组成,decoder network 与语言模型相似。
-
机器翻译可看成有条件的语言模型,机器的目标就是根据输入语句作为条件,找到最佳翻译语句,使其概率最大。
-
-
贪心搜索:
- 每次只寻找一个最佳单词作为翻译输出,力求把每个单词都翻译准确。
- 贪心搜索并不是最佳方法。
集束搜索
集束搜索:
Beam Search 集束搜索
Beam Width 集束宽度
- 每次寻找 个预测概率最大的单词, 是集束宽度。 时,即为贪心搜索。
- 假设 :
- 首先计算 ,找到最可能的 个 。
- 依据 和 计算 ,找到最可能的 个 单词对。
- 以此类推,找到最可能的句子。
改进集束搜索:
Length Normalization 长度归一化
-
集束搜索中,机器翻译的概率是乘积形式,多个概率相乘会使结果很小,因此可以取对数转换为求和形式。
-
机器翻译得到的句子中的单词越少,概率的乘积就越小,模型会倾向于选择短句子,因此引入归一化因子 对长度进行归一化。
- 当 时,完全进行长度归一化。
- 当 时,不进行长度归一化。
-
与 BFS 和 DFS 相比,集束搜索运行速度快,但并不保证一定能找到正确的翻译语句。
集束搜索的误差分析:
- 人工翻译记为 ,机器翻译记为 。
- 如果 ,集束搜索可能有问题。
- 集束搜索会使 尽可能大,但是现在 ,所以集束搜索可能有问题。
- 如果 ,RNN 模型可能有问题。
- 人工翻译 是比机器翻译 更好的翻译,但是 RNN 预测 更好,所以 RNN 模型可能有问题。
- 如果 ,集束搜索可能有问题。
Bleu Score:
Bilingual Evaluation Understudy 双语评估替换
-
Bleu Score 用于对机器翻译进行打分。
-
最简单的准确度评价方法是看机器翻译的每个单词是否出现在参考翻译中,这种方法很不科学,并不可取。
-
另外一种评价方法是看机器翻译单词出现在参考翻译单个语句中的次数,取最大次数。
- 如,参考翻译为 "The cat is on the mat.",机器翻译为 "The the the the the the the.",准确率为 。
-
上述两种方法都是对单个单词进行评价。按照集束搜索的思想,另外一种更科学的打分方法是 Bleu Score On Bigrams,即同时对两个连续单词进行打分。
-
如,参考翻译为 "The cat is on the mat.",机器翻译为 "The cat the cat on the mat."
-
将机器翻译分解成两个单词组成的词组:
- 机器翻译中:"the cat" 出现 次,"cat the" 出现 次,"cat on" 出现 次,"on the" 出现 次,"the mat" 出现 次。
- 参考翻译中:"the cat" 出现 次,"cat the" 出现 次,"cat on" 出现 次,"on the" 出现 次,"the mat" 出现 次。
- 准确率为 。
-
公式:
同时计算 再求平均,并引入参数因子 (brevity penalty, BP) "惩罚" 机器翻译语句过短而造成的得分 "虚高" 的情况:
-
注意力模型
注意力模型直观理解:
Attention Model 注意力模型
Attention Weights 注意力权重
- 如果原语句很长,要对整个语句输入 RNN 的编码网络和解码网络进行翻译,则效果不佳。
- 对待长语句,正确的翻译方法是将长语句分段,每次只对长语句的一部分进行翻译,根据这种 "局部聚焦" 的思想,建立相应的注意力模型 (Attention Model)。
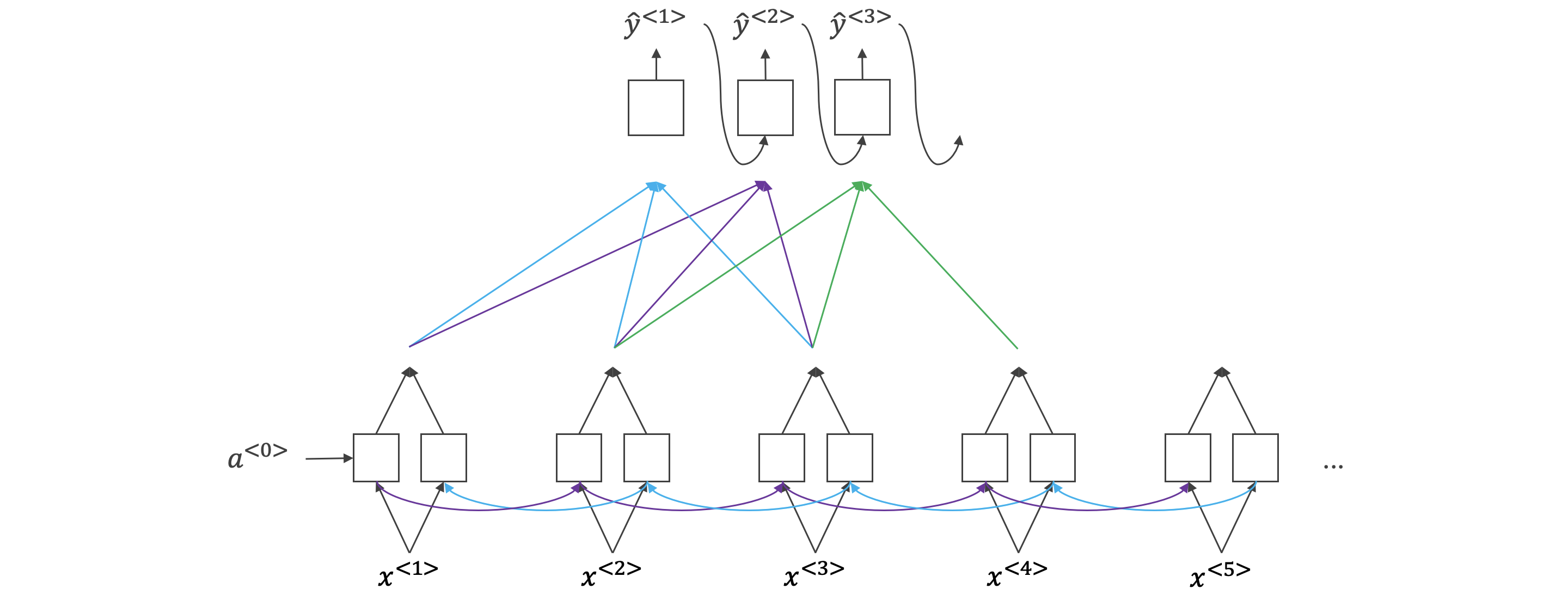
注意力模型:
-
符号:
-
表示双向 RNN 中 。
-
表示机器翻译的第一个单词对应 RNN 第 个神经元的权重。
-
表示机器翻译的第一个单词对应解码网络输入参数。
-
参数,使 之和为 。 通过一个简单的神经网络计算得到,输入是 和 。
-
机器翻译状态。
-
-
注意力模型计算量大,若输入句子长度为 ,输出句子长度为 ,则计算时间约为 。
应用
语音识别:
Connectionist Temporal Classification CTC
- 语音识别的输入时间序列都比较长,而翻译的语句通常很短,可以把输出相应字符重复并加入空白,这种模型被称为 CTC。
触发字检测:
Trigger Word Detection 触发字检测
- 触发字检测:说出触发字通过语音来启动相应的设备。
- 百度 DuerOS 的触发字是 "小度你好",Apple Siri 的触发字是 "Hey Siri"。
- 触发字检测系统可以使用 RNN 模型来建立。
- 输入语音中包含一些触发字,其余都是非触发字。RNN 检测到触发字后输出 ,非触发字输出 。这样训练的 RNN 模型就能实现触发字检测。
- 这种模型有一个缺点,就是通常训练样本语音中的触发字较非触发字数目少得多,即正负样本分布不均。一种解决办法是在出现一个触发字时,将其附近的 RNN 都输出 。这样就简单粗暴地增加了正样本。


【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· 震惊!C++程序真的从main开始吗?99%的程序员都答错了
· 【硬核科普】Trae如何「偷看」你的代码?零基础破解AI编程运行原理
· 单元测试从入门到精通
· 上周热点回顾(3.3-3.9)
· winform 绘制太阳,地球,月球 运作规律