【操作系统】grep sed awk
grep
global regular expressions print
在一个或多个文件中,搜索某一特定的字符模式。
格式:
grep [选项] 模式 文件名。- 选项可省略。
- 模式可以是字符串,也可以是正则表达式。
- 文件名可以是一个或多个。如果是搜索多个文件,grep 命令的搜索结果只显示文件中发现匹配模式的文件名;而如果搜索单个文件,grep 命令的结果将显示每一个包含匹配模式的行。
选项:
-a不忽略二进制数据进行搜索。-c仅列出文件中包含模式的行数。-i忽略大小写。-l列出带有匹配行的文件名。-n显示行号。-r从文件夹递归查找。-v列出没有匹配的行。-w忽略部分匹配的行。
模式:
c*匹配 0 个或多个字符 c(c 为任一字符)。.匹配任何一个字符,且只能是一个字符。[xyz]匹配方括号中的任意一个字符。[^xyz]匹配除方括号中字符外的所有字符。^锁定行的开头。$锁定行的结尾。

例——grep:
# 在 /etc/acpi 目录中递归查找 update
grep -r update /etc/acpi
# 查找文件名中包含 test 的文件中不包含 test 的行
grep -v test *test*
# 找出以 78 开头的数据行
grep ^78 emp.data
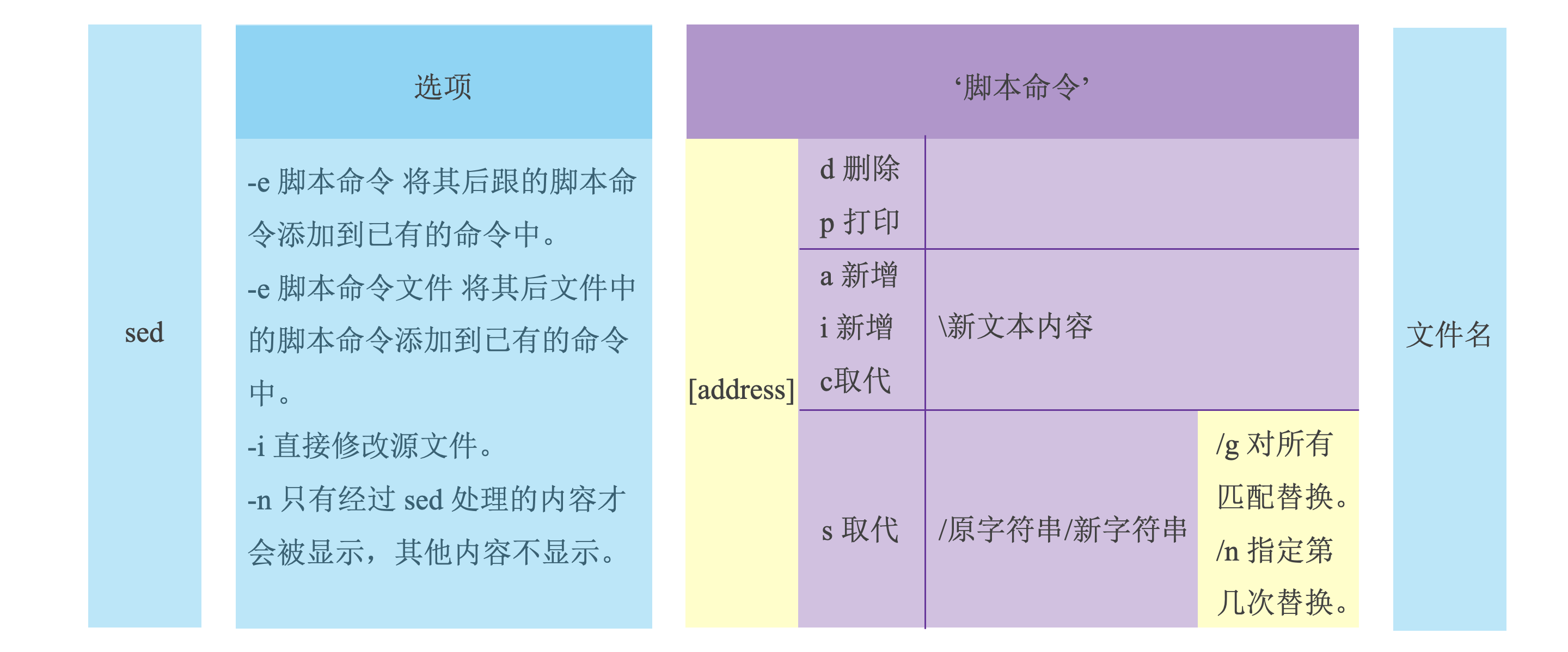
sed
读取一行内容。
根据提供的规则命令匹配并修改数据(sed 默认不会直接修改源文件数据,而是会将数据复制到缓冲区中,修改也仅限于缓冲区中的数据)。
将执行结果输出。
格式:
sed [选项] '[脚本命令]' 文件名。
选项:
-e 脚本命令将其后跟的脚本命令添加到已有的命令中。-e 脚本命令文件将其后文件中的脚本命令添加到已有的命令中。-i直接修改源文件。-n只有经过 sed 处理的内容才会被显示,其他内容不显示。
脚本命令:
- 插入
a或i:[address]a\新文本内容或[adress]i\新文本内容。a命令表示在指定行的后面附加一行。i命令表示在指定行的前面插入一行。- 如果想将一个多行数据添加到数据流中,只需对要插入或附加的文本中的每一行末尾(除最后一行)添加反斜线即可。
- 删除
d:[address]d。- 如果忘记指定具体行的话,文件中的所有内容都会被删除。
- 默认情况下 sed 并不会修改原始文件,这里被删除的行只是从 sed 的输出中消失了,原始文件没做任何改变。
- 替换
s:[address]s/pattern/replacement/flags。- 将字符串替换成字符串。
address指定要操作的具体行。pattern指原内容,可为正则表达式;replacement指新内容。flags:n,n为 1~512 之间的数字,表示指定要替换的字符串出现第几次时才进行替换。g,对数据中所有匹配到的内容进行替换。p,打印与替换命令中指定的模式匹配的行。w file, 将缓冲区中的内容写到指定的 file 文件中。\,转义,例sed 's/\/bin\/bash/\/bin\/csh/' file。
- 替换
c:[address]c\用于替换的新文本。- 将指定行中的所有内容,替换成该选项后面的字符串。
- 替换
y:[address]y/inchars/outchars/。- 对
inchars和outchars值进行一对一的映射。 - 如果
inchars和outchars的长度不同,则 sed 会产生一条错误消息。
- 对
- 打印
p:[address]p。- 可利用此命令配合
address进行查找操作。
- 可利用此命令配合
wrq:咕咕咕~
寻址方式:
- 默认情况下,sed 命令会作用于文本数据的所有行。如果只想将命令作用于特定行或某些行,则必须写明 address 部分。
- 以数字形式指定行区间:
- 文本流中的第一行编号为 1。
- 指定的地址可以是单个行号,或是用起始行号、逗号以及结尾行号指定的一定区间范围内的行。
- 修改时包括起始行和结尾行。
- 可以使用特殊地址
$。
- 以文本模式指定行区间:
- 必须用
/ /将要指定的文本模式封起来,sed 会将该命令作用到包含指定文本模式的行上。 - 允许使用正则表达式。
- 必须用
例——sed:
# 在 testfile 文件的第四行后添加一行,该行内容为 newLine,不修改原文件。
sed -e 4a\newLine testfile
# 删除第 2 行
sed '2d'
# 将第 2 行到第 5 行删除,包括第 2 行和第 5 行
sed '2,5d'
# 删除第 2 行到最后一行
sed '2,$d'
# 将第 5 行到第 7 行打印到屏幕
sed -n '5,7p'
# 将包含 root 的行删除
sed '/root/d'
# 将第 3 行到文件末尾删除,然后将每行中第一次出现的 bash 替换成 blueshell
sed -e '3,$d' -e 's/bash/blueshell/'
# 将 regular_express.txt 内结尾为 . 的每一行结尾换成 !
sed -i 's/\.$/\!/g' regular_express.txt
# 将包含 root 的行打印,其中 /root/ 是 [address] 部分
sed -n '/root/p'
# 使用花括号可执行多个脚本命令
# 将包含 root 的行中 bash 改为 blueshell,然后打印所有含 bash 的行,然后退出命令
sed -n '/root/{s/bash/blueshell/;p;q}'
awk
逐行扫描文件。
寻找含有目标文本的行。
如果匹配成功,则会在该行上执行用户想要的操作;反之,则不对行做任何处理。
格式:
awk [选项] '脚本命令' 文件名。
选项:
-F fs指定以fs作为输入行的分隔符,默认分隔符为空格或制表符。-f file从脚本文件中读取 awk 脚本指令,以取代直接在命令行中输入指令。-v var=val在执行处理过程之前,设置一个变量 var,并给其设备初始值为 val。
脚本命令 '匹配规则{执行命令}':
- 如果没有指定执行命令,则默认会把匹配的行输出;如果不指定匹配规则,则默认匹配文本中所有的行。
- 数据字段变量:每个数据字段通过字段分隔符划分,
$0代表整个文本行;$n代表文本行中的第 n 个数据字段。 - 在脚本命令中使用多个命令:在命令之间放分号。
BEGIN关键字:强制 awk 在读取数据前执行该关键字后指定的脚本命令。END关键字:指定一些脚本命令,awk 会在读完数据后执行它们。

例——awk:
# 匹配文本中的空白行,匹配到空白行时,输出 Blank line,即有多少空白行,输出多少次 Blank line
awk '/^$/ {print "Blank line"}' test.txt
# 给第四个字段赋值 Christine,然后输出整行
awk '{$4="Christine"; print $0}'
# 使用 , 分隔,输出第一项和第二项
awk -F, '{print $1,$2}' log.txt
# 输出第一项大于 2 的行
awk '$1>2' log.txt
awk 的更多内容:咕咕咕~


【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· 阿里最新开源QwQ-32B,效果媲美deepseek-r1满血版,部署成本又又又降低了!
· AI编程工具终极对决:字节Trae VS Cursor,谁才是开发者新宠?
· 开源Multi-agent AI智能体框架aevatar.ai,欢迎大家贡献代码
· Manus重磅发布:全球首款通用AI代理技术深度解析与实战指南
· 被坑几百块钱后,我竟然真的恢复了删除的微信聊天记录!