
- 评判规则:量化算法执行的操作/执行步骤的数量;
- 最重要的项:时间复杂度表达式中最有意义的项
- 大O记法:O(最重要的一项)
- O(1)表示一个特殊复杂度,含义为某个任务通过有限可数的资源即可完成,于输入数据量n无关;
- 一个顺序结构的代码,时间负责度是O(1);
- 二分查找法,分而治之的二分策略,时间复杂度为O(logn);
- 一个简单的for循环或并列两个for循环,时间复杂度是O(n);
- 两个嵌套的for循环,时间复杂度是O(n^2);
- 散列表 (散列表就是对数组的一种扩展,是由数组演化而来)
- hashtable 散列表(特性是:数组支持按照下标随机访问数据)
- ConcurrentHashMap
- 分段锁 不会影响整个table的,只会影响Hash值一样的(jdk1.7)
- HashMap
- 散列函数:先用H(key)=key MOD7有冲突后解决方法
- Hash冲突
- 将产生冲突的值以链表的形式连接起来,将相同hash值的对象以链表的形式进行存储,当链表过长时转换成红黑树;
- 冲突处理:线性探测法 (向下顺延1个)
- 二次探测法:di=1^2,-1^2,2^2,-2^2 Hi=(H0+di+m)%m
- 双散列法:ReHash(key)=keyMOD11+1 Hi=(H0+i*ReHash(key))%m
- 动态扩容
- HashMap的初始容量是16;
- 扩容阈值是0.75;
- 何时扩容:
- HashMap中存储的数据个数超过数组长度*0.75,就要扩容;
- 如果单个链表的长度超过8,但是数组的长度没有超过64,就扩容;
- 何时树化:
- 单链长度超过8,数组长度超过64(包含)才进行树化;
- 哪个链超过了阈值就哪个链树化;
- 如果树化后的节点数小于6,就退树化,变成链表;
- 位图
- 平衡二叉树 :它的左子树和右子树的深度之差(平衡因子)的绝对值不超过1,且它的左子树和右子树都是一颗平衡二叉树。
- 二叉查找树 :左节点都比根节点小,右节点都比根节点大;
- 完全二叉树:完全二叉树第i层至多有2(i-1)个节点,共i层的完全二叉树最多有2i-1个节点;
- 满二叉树:满二叉树一定是完全二叉树,但反过来不一定成立;
- 非叶子节点数总是比叶子节点数多1,即如果叶子节点数为N,非叶子节点数则为N+1;
- B树 (B-树):每个节点高度都相等。最下面是叶子节点,叶子节点实际上是一个空指针,实际的值被称为终端节点,可以查找到实际的关键字;
- 对于m叉树,树中每个节点至多有m棵子树,即至多有m-1个关键字;
- 一组数插入后会分裂int(m/2)

- 若根节点不是终端节点,则至多有两棵子树;
- 除根节点外的所有非叶子节点至少有m/2棵子树,即至少含有m/2-1个关键字;
- 所有的叶子节点都出现在同一层次上,并且不带信息;
- 非叶子节点由k关键字和p指针组成,怕、Pi-1所值子树中所有结点的关键字均小于Ki,Pi所值子树中所有结点的关键字均大于Ki;
- B+树
- 组合索引符合最左匹配原则;
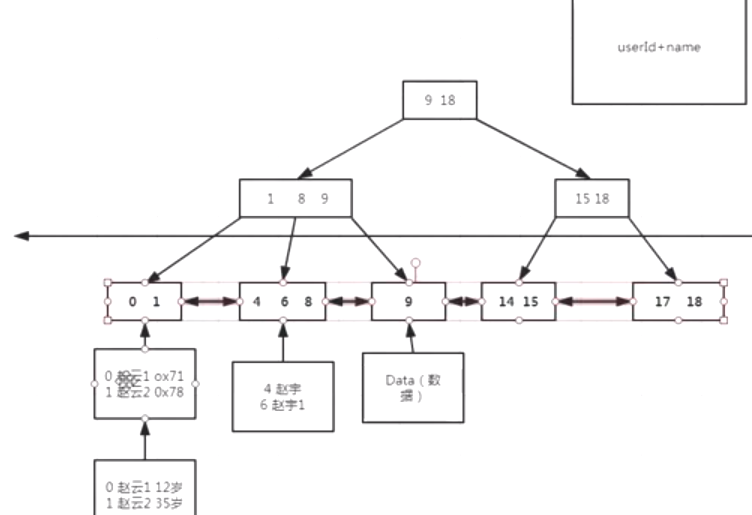
- 每个节点最多有m个子节点;
- 除了根节点外,每个节点至少有m/2个子节点,如果除不尽,就像上取整,比如5/2=3;
- 根节点要么是空的,要么是独根,否则至少有2个子节点;
- 有k个子节点必有k个关键码;
- 叶节点的高度一致;
- B树和B+树的区别:B+树非叶子节点上是不存储数据的,仅存储键值,而B树节点中不仅存储键值,也会存储数据;B+树增加了系统的稳定性以及遍历查找效率;
- 红黑树(存中的意义防止二叉树退化成链表)
- 根节点一定是黑色;
- 两个红色节点不能靠着;
- 在HashMap: jdk1.7用链表;jdk1.8版本中引入了红黑树,在链表大于8的时候;
- 数据库的索引不能用红黑树,因为红黑树会频繁操作磁盘IO的资源;
- HashMap为什么不用B+树而用红黑树?
- B+tree是放在磁盘的(大数据量)会牵扯到分裂,红黑树在内存里面的(少量数据);
- 大根堆
- 小根堆
- 优先级队列
- 斐波那契堆
- 二顶堆
- 权重
- 有权图
- 无权图
- 方向
- 有向图
- 无向图
- 连续存储--数组
- 离散存储--链表
- 单向链表
- 双向链表
- 循环链表
- 非循环链表
- 跳表
- 栈
- 出栈(pop)和入栈(push);
- 栈是限制线性表中元素的插入和删除只能在线性表的同一端进行的一种特殊线性表。允许插入和删除一端,为变化的一端,称为栈顶,另一端为固定的一端,称为栈底;
- 子程序的调用:在跳往子程序前,会先将下个指令的地址存到堆栈中,直到子程序执行完后再将地址取出,以回到原来的程序中;
- 处理递归调用:和子程序的调用类似,只是除了存储下一个指令的地址外,也将参数、区域变量等数据存入堆栈中;
- 表达式的转换与求值(中缀表达式转后缀表达式)(实际解决);
- 二叉树的遍历;
- 图形的深度优先(depth-first)搜索法;
- 使用一个数组来模拟栈;
- 定义一个top来表示栈顶,初始化为-1;
- 入栈的操作,当有数据加入到栈时,top++;stack[top]=data;
- 出栈的操作,int value=stack[top];top--,return valuel;
- 顺序栈
- 链式栈
- 队列
- 普通队列
- 双端队列
- 阻塞队列
- 并发队列
- 阻塞并发队列
- 交换排序
- 冒泡排序
- 快速排序
- 插入排序
- 简单插入排序
- 希尔排序
- 选择排序
- 简单选择排序
- 堆排序
- 归并排序
- 二路归并排序
- 多路归并排序
- 计数排序
- 桶排序
- 基数排序
posted @
2024-01-21 19:40
卡皮巴拉
阅读(
25)
评论()
编辑
收藏
举报
点击右上角即可分享


【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· TypeScript + Deepseek 打造卜卦网站:技术与玄学的结合
· Manus的开源复刻OpenManus初探
· AI 智能体引爆开源社区「GitHub 热点速览」
· 从HTTP原因短语缺失研究HTTP/2和HTTP/3的设计差异
· 三行代码完成国际化适配,妙~啊~