Linux(CentOS) Docker 部署Logstash (通过Logstash由SQLServer向Elasticsearch同步数据)
1.拉取镜像
使用以下命令拉去与elasticsearch 版本一致logstash的镜像
docker pull logstash:xxxx
下载完成之后,使用以下命令查询是否成功
docker images
如图
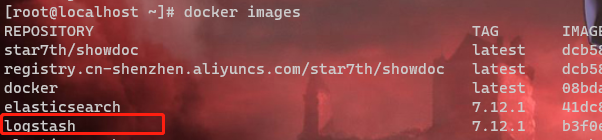
2.创建挂载目录
mkdir -p dockerdata/logstash/{config,pipeline}

启动容器并把配置文件复制到挂载目录
docker run -it -p 5044:5044 -p 9600:9600 -d --name logstash -e LS_JAVA_OPTS="-Xms512m -Xmx512m" --privileged=true logstash:xxx
docker cp logstash:/usr/share/logstash/config/ /dockerdata/logstash/config/
docker cp logstash:/usr/share/logstash/pipeline/ /dockerdata/logstash/pipeline/
停止容器并删除
docker stop 容器名称/id
docker rm 容器名称/id
3. 启动容器并挂载
docker run -it -p 5044:5044 -p 9600:9600 -d --name logstash -e LS_JAVA_OPTS="-Xms512m -Xmx512m" -v /dockerdata/logstash/config/:/usr/share/logstash/config/ -v /dockerdata/logstash/pipeline/:/usr/share/logstash/pipeline/ --privileged=true logstash:xxx
4.安装插件
bin/logstash-plugin install logstash-input-jdbc
bin/logstash-plugin install logstash-output-elasticsearch
这块可能会有两个报错提示
1.如提示Installation aborted, verification failed for logstash-input-jdbc
需要在install 后面加上--no-verify
2.如提示Installation aborted, plugin 'logstash-input-jdbc' is already provided by...
说明不需要安装了,logstash 已经支持logstash-input-jdb插件
5. 修改config和pipeline 目录的配置文件
如果你的Es与logstash 部署在同一台服务器的docker里面,那么就需要了解容器之间的访问了,可以参考容器互访的三种模式
我采用的是第三种,可能会出现docker容器内部ping不通域名的情况 可以参考 docker ping不通域名
5.1 config (dockerdata/logstash/config)
pipeline.yml 修改后的内容
# This file is where you define your pipelines. You can define multiple.
# For more information on multiple pipelines, see the documentation:
# https://www.elastic.co/guide/en/logstash/current/multiple-pipelines.html
- pipeline.id: main
path.config: "/usr/share/logstash/pipeline/logstash.conf"
logstash.yml 修改后的内容
http.host: "0.0.0.0"
# xxx.xx.xx es地址
xpack.monitoring.elasticsearch.hosts: ["http://xxx.xx.xx:9200"]
xpack.monitoring.enabled: true
5.2 pipeline (dockerdata/logstash/pipeline/)
pipeline目录下需要有三个文件(sqlserver的连接配置驱动,logstash.conf,logstash_jdbc_last_run)
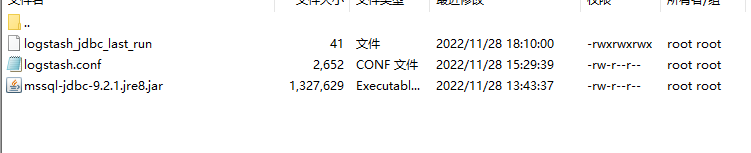
mssql-jdbc-9.2.1.jre8.jar
本地下载之后用(FileZilla)上传至服务器 ,其他配置文件我也是在本地编辑之后上传的,linux 编辑感觉不是特别方便,当然你也可以使用vi命令编辑。
logstash.conf
input {
stdin {
}
jdbc {
#数据库驱动所在位置,可以是绝对路径或者相对路径
jdbc_driver_library => "/usr/share/logstash/pipeline/mssql-jdbc-9.2.1.jre8.jar"
#驱动类名
jdbc_driver_class => "com.microsoft.sqlserver.jdbc.SQLServerDriver"
#数据库连接
jdbc_connection_string => "jdbc:sqlserver://xxx.xxx.xx;DatabaseName=DbName;"
#用户
jdbc_user => "sa"
#密码
jdbc_password => "sa123456"
#设置定时任务间隔 含义:分、时、天、月、年,全部为*默认含义为每分钟跑一次任务
#schedule => "* * * * *"
#每小时的第10分钟执行
schedule => "10 /1 * * *"
#索引设置时区
jdbc_default_timezone => "Asia/Shanghai"
#sql语句
statement => "SELECT *
FROM table where Isdeleted=0 and updatedtime>:sql_last_value"
#或者sql可执行文件
#statement_filepath => "路径"
#是否开启记录上次追踪的结果,也就是上次更新的时间,这个会记录到 last_run_metadata_path 的文件
use_column_value => true
#tracking_column 对应字段的类型
tracking_column_type => "timestamp"
#如果 use_column_value 为true, 配置本参数,追踪的 column 名,可以是自增id或者时间
tracking_column => "updatedtime"
#是否记录上次执行结果, 如果为真,将会把上次执行到的 tracking_column 字段的值记录下来,保存到 last_run_metadata_path 指定的文件中
record_last_run => true
# 记录上一次追踪的结果值
last_run_metadata_path => "/usr/share/logstash/pipeline/logstash_jdbc_last_run"
#
#type => ""
# 数据库字段名称大写转小写
lowercase_column_names => false
#是否清除 last_run_metadata_path 的记录,如果为真那么每次都相当于从头开始查询所有的数据库记录
#clean_run :
}
}
output {
elasticsearch {
# ES的IP地址及端口
hosts => ["http://xxx.xx.xx:9200"]
# 索引名称 可自定义(只可以小写)
index => "customer"
document_type => "customer"
# 需要关联的数据库中有有一个id字段,对应类型中的id
document_id => "%{id}"
}
stdout {
# codec => json_lines
#设置输出的格式
codec => line {
format => "updatedtime: %{[updatedtime]}"
}
}
}
logstash_jdbc_last_run
使用echo命令创建文件并写入内容
echo '--- !ruby/object:DateTime '2022-11-28 02:40:00.317455000 Z'' > logstash_jdbc_last_run
使用cat 查看是否成功
cat logstash_jdbc_last_run

重启 logstash容器
docker restart 容器名称/id
查看日志
docker logs -f logstash

 浙公网安备 33010602011771号
浙公网安备 33010602011771号