k8s 对外服务之ingress
1.什么是 Ingress
NotePort, LoadBalance, 此外externalIPs也可以使各类service对外提供服务,但是当集群服务很多的时候,NodePort方式最大的缺点是会占用很多集群机器的端口;LB方式最大的缺点则是每个service一个LB又有点浪费和麻烦,并且需要k8s之外的支持; 而ingress则只需要一个NodePort或者一个LB就可以满足所有service对外服务的需求。工作机制大致可以用下图表示: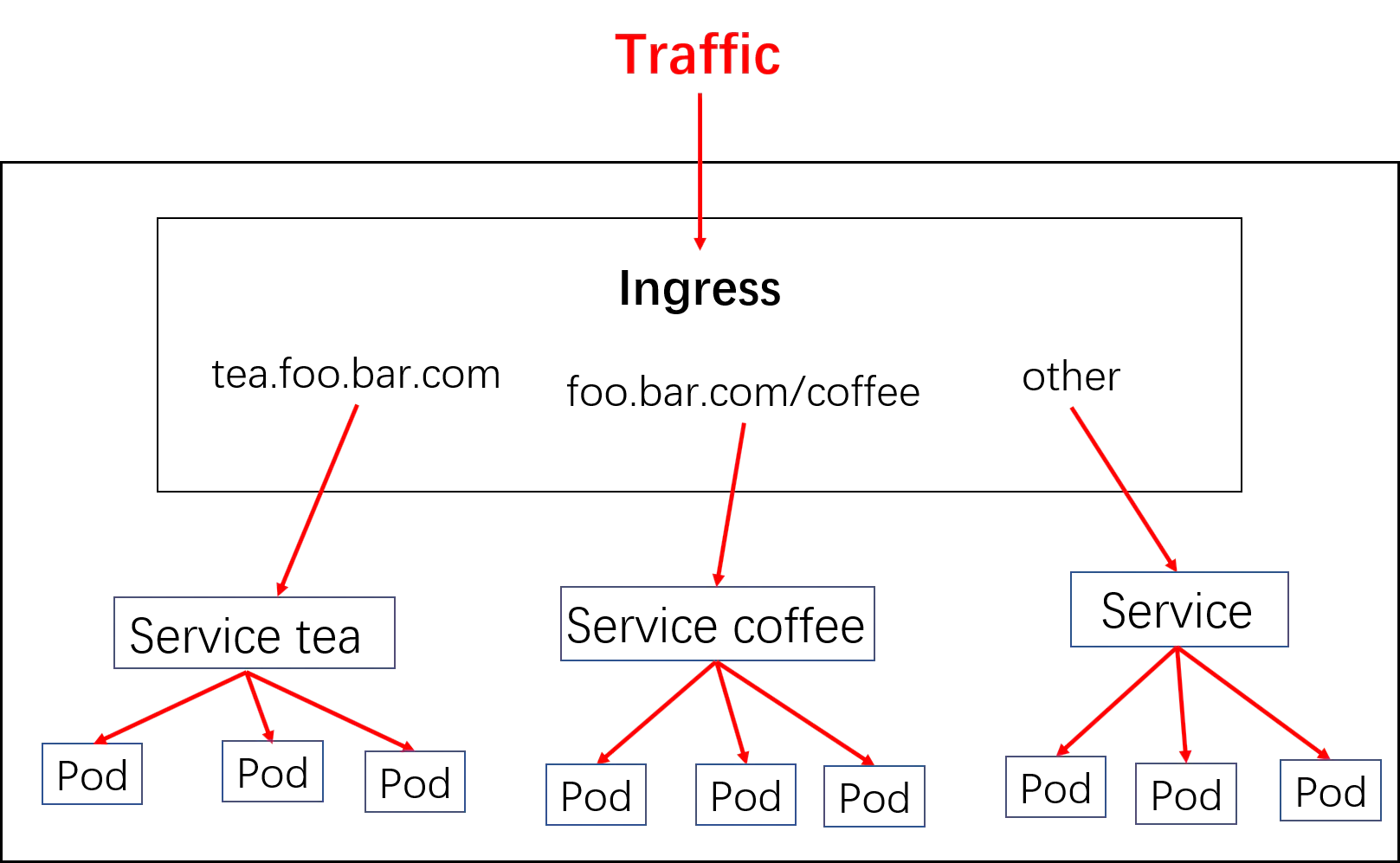
提示:如上图所示,ingress就是ingress 控制器pod的代理规则;用户请求某个后端pod所提供的服务时,首先会通过ingress controller pod把流量引入到集群内部,然后ingress controller pod根据ingress定义的规则,把对应ingress规则转化为对应ingress controller pod实现的对应应用的配置(ingress controller 可以由任何具有七层反向代理功能的服务实现,比如nginx,haproxy等等)然后再适配用户请求,把对应请求反代到对应service上;而对于pod的选择上,ingress控制器可以基于对应service中的标签选择器,直接同pod直接通信,无须通过service对象api的再次转发,从而省去了用户请求到kube-proxy实现的代理开销(本质上ingress controller 也是运行为一个pod,和其他pod在同一网段中)。
Ingress 可以给 Service 提供集群外部访问的 URL、负载均衡、SSL 终止、HTTP 路由等。为了配置这些 Ingress 规则,集群管理员需要部署一个 Ingress Controller,它监听 Ingress 和 Service 的变化,并根据规则配置负载均衡并提供访问入口。
Ingress 控制器和k8s上的其他控制不一样,ingress控制器并不能直接运行为kube-controller-manager的一部分,它类似k8s集群上的coredns,需要在集群上单独部署,本质上就是一个pod,我们可以使用k8s上的ds或deploy控制器来创建它。
2.Ingress的核心组件
要理解ingress,需要区分两个概念,ingress和ingress-controller:
ingress controller:核心是一个deployment,实现方式有很多,比如nginx, Contour, Haproxy, trafik, Istio,需要编写的yaml有:Deployment, Service, ConfigMap, ServiceAccount(Auth),其中service的类型可以是NodePort或者LoadBalancer。具体是实现反向代理及负载均衡的程序,对ingress定义的规则进行解析,根据配置的规则来实现请求转发;简单来说,Ingress-controller才是负责转发的组件,通过各种方式将他暴露在集群入口,外部对集群的请求流量会先到Ingress-controller,而Ingress对象是用来告诉Ingress-controller该如何转发请求,比如那些域名那些path要转发到那些服务等.ingress:这个就是一个类型为Ingress的k8s api对象了,一般用yaml配置,作用是定义请求如何转发到service的规则,可以理解为配置模板。
假设已经有两个服务部署在了k8s集群内部:
$ kubectl get svc,deploy NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE svc/coffee-svc ClusterIP <none> <none> 80/TCP 1m svc/tea-svc ClusterIP <none> <none> 80/TCP 1m NAME DESIRED CURRENT UP-TO-DATE AVAILABLE AGE deploy/coffee 2 2 2 2 1m deploy/tea 1 1 1 1 1m
配置 Ingress resources,即可实现多个service对外暴露服务:
1)coffee-svc
apiVersion: extensions/v1beta1 kind: Ingress metadata: name: cafe-ingress spec: rules: # 配置七层域名 - host: foo.bar.com http: paths: # 配置Context Path - path: /tea backend: serviceName: tea-svc servicePort: 80 # 配置Context Path - path: /coffee backend: serviceName: coffee-svc servicePort: 80
2)tea-svc
apiVersion: extensions/v1beta1 kind: Ingress metadata: name: cafe-ingress spec: rules: # 配置七层域名 - host: tea.foo.bar.com http: paths: - backend: serviceName: tea-svc servicePort: 80 - host: coffee.foo.bar.com http: paths: - backend: serviceName: coffee-svc servicePort: 80
接着在hosts文件中添加一条解析规则即可在浏览器访问了。
3.部署Nginx Ingress Controller( 基于Nginx 来处理请求)
资料信息地址:
Ingress-Nginx-github 地址:https://github.com/kubernetes/ingress-nginx
Ingress-Nginx 官方地址:https://kubernetes.github.io/ingress-nginx
注意:选择合适的版本
3.1下载并修改配置文件
下载整合配置文件,获取配置文件地址:https://github.com/kubernetes/ingress-nginx/tree/nginx-0.30.0/deploy/static
# wget https://raw.githubusercontent.com/kubernetes/ingress-nginx/nginx-0.30.0/deploy/static/mandatory.yaml
# service-nodeport.yaml为ingress通过nodeport对外提供服务,注意默认nodeport暴露端口为随机,可以编辑该文件自定义端口。
# wget https://raw.githubusercontent.com/kubernetes/ingress-nginx/nginx-0.30.0/deploy/static/provider/baremetal/service-nodeport.yaml应用yml文件创建ingress资源:
# kubectl apply -f mandatory.yaml
# kubectl apply -f service-nodeport.yaml
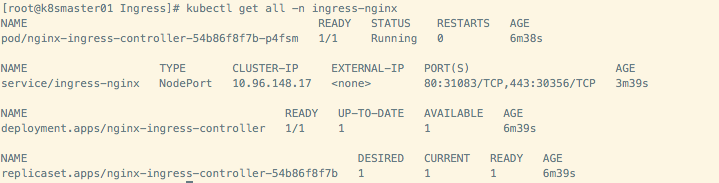
# kubectl get all -n ingress-nginx -o wide
3.2实际应用举例
3.2.1创建svc及后端deployment
# cat test-ingress-pod.yaml apiVersion: apps/v1 kind: Deployment metadata: labels: app: web-a name: web-a spec: replicas: 2 selector: matchLabels: app: web-a template: metadata: labels: app: web-a spec: containers: - image: nginx name: web-a --- apiVersion: v1 kind: Service metadata: name: web-a labels: app: web-a spec: ports: - port: 80 targetPort: 80 selector: app: web-a
应用yaml:
# kubectl apply -f test-ingress-pod.yaml # kubectl get pod NAME READY STATUS RESTARTS AGE web-a-89b89d4dd-chhhq 1/1 Running 0 38s web-a-89b89d4dd-tjh82 1/1 Running 0 38s
查看service:
# kubectl get svc NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE kubernetes ClusterIP 10.96.0.1 <none> 443/TCP 15d web-a ClusterIP 10.96.214.85 <none> 80/TCP 64s
3.2.2创建Ingress规则
其实就是配置NGINX的一个过程
# ingress规则中,要指定需要绑定暴露的svc名称 apiVersion: extensions/v1beta1 kind: Ingress metadata: name: ingress-web-a annotations: kubernetes.io/ingress.class: "nginx" # 指定 Ingress Controller 的类型 nginx.ingress.kubernetes.io/use-regex: "true" # 指定我们的 rules 的 path 可以使用正则表达式 nginx.ingress.kubernetes.io/proxy-connect-timeout: "600" # 连接超时时间,默认为 5s nginx.ingress.kubernetes.io/proxy-send-timeout: "600" # 后端服务器回转数据超时时间,默认为 60s nginx.ingress.kubernetes.io/proxy-send-timeout: "600" # 后端服务器响应超时时间,默认为 60s nginx.ingress.kubernetes.io/proxy-body-size: "10m" # 客户端上传文件,最大大小,默认为 20m spec: rules: #定义路由规则 - host: www.web-a.com # 主机名,只能是域名,修改为你自己的 http: paths: - path: / backend: serviceName: web-a # 后台部署的 Service Name servicePort: 80 # 后台部署的 Service Port
说明:在ingress配置中,annotations很重要,前面有说ingress-controller有很多不同的实现,而不同的Ingress-controller就可以根据"kubernetes.io/ingress.class"来判断要使用那些ingress配置,同时,不同的ingress-controller也有对应的annotations配置,用于自定义一些参数。
应用yaml文件:
# kubectl apply -f test-ingress-web-a.yaml kubectl get ingress Warning: extensions/v1beta1 Ingress is deprecated in v1.14+, unavailable in v1.22+; use networking.k8s.io/v1 Ingress NAME CLASS HOSTS ADDRESS PORTS AGE ingress-web-a <none> www.web-a.com 10.96.148.17 80 6m26s
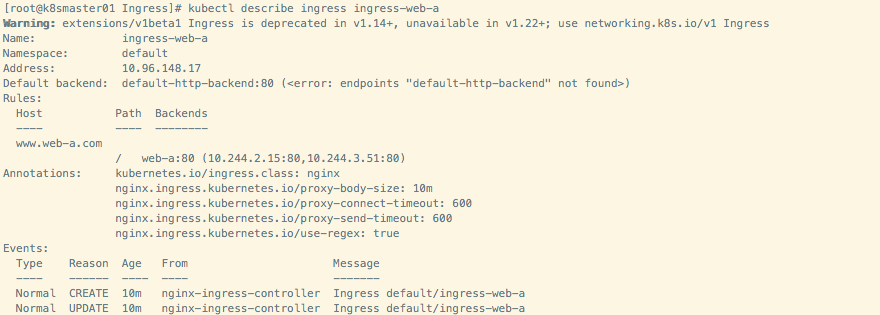
c:\windows\system32\drivers\etc\hosts:192.168.0.25 www.web-a.com
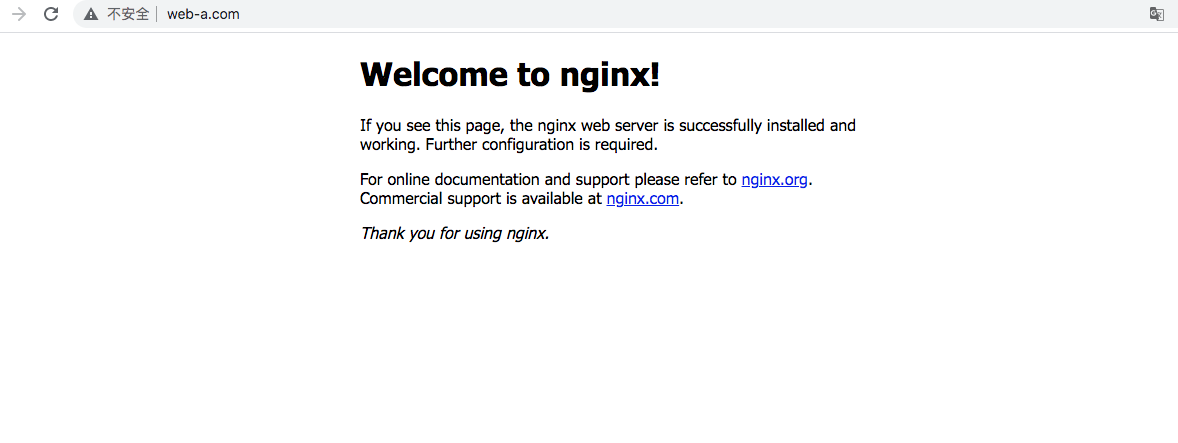
访问测试:域名+nodeport的模式
总结:
- 上面我们创建一个针对于nginx的deployment资源,pod为2个;
- 为nginx的pod暴露service服务,名称为web-a
- 通过ingress把nginx暴露出去
这里对于nginx创建的svc服务,其实在实际调度过程中,流量是直接通过ingress然后调度到后端的pod,而没有经过svc服务,svc只是提供一个收集pod服务的作用。
4.Ingress的部署,架构简谈
Ingress的部署,需要考虑两个方面:
# 1 . ingress-controller是作为Pod来运行的,以什么方式部署比较好
# 2 . ingress解决了如何请求路由到集群内部,那他自己怎么暴露给外部比较好
下面列举一些目前常用的部署和暴露方式,具体使用哪种方式还得根据实际需要考虑来决定:
- Deployment+LoadBalancer模式的service
如果要把ingress部署在公有云,那用这种方式比较合适。用Deployment部署ingress-controller,创建一个type为LoadBalancer的service关联这组pod。大部分公有云,都会为LoadBalancer的service自动创建一个负载均衡器,通常还绑定了公网地址。只要把域名解析指向该地址,就实现了集群服务的对外暴露。
- Deloyment+NodePort模式的service
同样用deployment模式部署ingress-controller,并创建对应的服务,但是type为NodePort。这样,ingress就会暴露在集群节点ip的特定端口上。由于nodeport暴露的端口是随机端口,一般会在前面再搭建一套负载均衡器来转发请求。该方式一般用于宿主机是相对固定的环境ip地址不变的场景。
NodePort方式暴露ingress虽然简单方便,但是NodePort多了一层NAT,在请求量级很大时可能对性能会有一定影响。
- DaemonSet+HostNetwork+nodeSelector
用DaemonSet结合nodeselector来部署ingress-controller到特定的node上,然后使用HostNetwork直接把该pod与宿主机node的网络打通,直接使用宿主机的80/433端口就能访问服务。这时,ingress-controller所在的node机器就很类似传统架构的边缘节点,比如机房入口的nginx服务器。该方式整个请求链路最简单,性能相对NodePort模式更好。缺点是由于直接利用宿主机节点的网络和端口,一个node只能部署一个ingress-controller pod。比较适合大并发的生产环境使用。
4.1.DaemonSet+HostNetwork+nodeSelector部署
DaemonSet简介:
DaemonSet 是指在 Kubernetes 集群里运行一个 Daemon Pod, 它有如下特征:
- 这个 Pod 默认运行在 Kubernetes 集群里的每一个Node节点上;
- 每个节点上只有一个这样的 Pod 实例;
- 当有新的节点加入集群时,会自动创建该 Pod 。
修改mandatory.yaml,主要修改pod相关:
apiVersion: apps/v1 kind: DaemonSet #修改为DaemonSet metadata: name: nginx-ingress-controller namespace: ingress-nginx labels: app.kubernetes.io/name: ingress-nginx app.kubernetes.io/part-of: ingress-nginx spec: #replicas: 1 #注销此行,DaemonSet不需要此参数 selector: matchLabels: app.kubernetes.io/name: ingress-nginx app.kubernetes.io/part-of: ingress-nginx template: metadata: labels: app.kubernetes.io/name: ingress-nginx app.kubernetes.io/part-of: ingress-nginx annotations: prometheus.io/port: "10254" prometheus.io/scrape: "true" spec: # wait up to five minutes for the drain of connections terminationGracePeriodSeconds: 300 serviceAccountName: nginx-ingress-serviceaccount hostNetwork: true #添加该字段让docker使用物理机网络,在物理机暴露服务端口(80),注意物理机80端口提前不能被占用 dnsPolicy: ClusterFirstWithHostNet #使用hostNetwork后容器会使用物理机网络包括DNS,会无法解析内部service,使用此参数让容器使用K8S的DNS nodeSelector: #添加节点标签,在符合标签的node上部署,所以运行此服务的node标签要打上这个标签 kubernetes.io/ingress-controller-ready: "true" tolerations: #添加对指定node节点污点的容忍度,和node节点的污点有关系,pod指定了容忍度后,就可以在对应的打了此污点的node上部署。 - key: "node-role.kubernetes.io/master" operator: "Equal" value: "" effect: "NoSchedule" containers: - name: nginx-ingress-controller image: quay.io/kubernetes-ingress-controller/nginx-ingress-controller:0.30.0 ……
修改参数如下:
- kind: Deployment #修改为DaemonSet
- replicas: 1 #注销此行,DaemonSet不需要此参数
- hostNetwork: true #添加该字段让docker使用物理机网络,在物理机暴露服务端口(80),注意物理机80端口提前不能被占用
- dnsPolicy: ClusterFirstWithHostNet #使用hostNetwork后容器会使用物理机网络包括DNS,会无法解析内部service,使用此参数让容器使用K8S的DNS
- nodeSelector:kubernetes.io/ingress-controller-ready: "true" #添加节点标签,在符合标签的node上部署,所以运行此服务的node标签要改成这个标签
- tolerations: 添加对指定node节点的污点容忍度,和node节点的污点有关系,pod指定了容忍度后,就可以在对应的打了此污点的node上部署。

# kubectl label nodes k8snode01 kubernetes.io/ingress-controller-ready=true # kubectl label nodes k8snode02 kubernetes.io/ingress-controller-ready=true
在查看:

给node02、node02打上污点,污点内容根据上述配置文件中tolerations定义的来进行:这一步主要的作用是限定了只有容忍这个污点的pod才可以在这个节点上部署,也就是只有Ingress才能在这个node上部署。
# kubectl taint nodes k8snode01 node-role.kubernetes.io/master=:NoSchedule # kubectl taint nodes k8snode02 node-role.kubernetes.io/master=:NoSchedule 说明:因为value是空的,所以=后面直接就是:NoSchedule
查看污点:
# kubectl describe nodes k8snode01 Name: k8snode01 Roles: <none> Labels: beta.kubernetes.io/arch=amd64 beta.kubernetes.io/os=linux kubernetes.io/arch=amd64 kubernetes.io/hostname=k8snode01 kubernetes.io/ingress-controller-ready=true kubernetes.io/os=linux Annotations: flannel.alpha.coreos.com/backend-data: {"VNI":1,"VtepMAC":"3a:bc:8d:c3:5f:47"} flannel.alpha.coreos.com/backend-type: vxlan flannel.alpha.coreos.com/kube-subnet-manager: true flannel.alpha.coreos.com/public-ip: 192.168.0.27 kubeadm.alpha.kubernetes.io/cri-socket: /var/run/dockershim.sock node.alpha.kubernetes.io/ttl: 0 volumes.kubernetes.io/controller-managed-attach-detach: true CreationTimestamp: Sun, 05 Sep 2021 04:26:07 -0400 Taints: node-role.kubernetes.io/master:NoSchedule Unschedulable: false
……
部署Ingress:
# kubectl apply -f mandatory.yaml # kubectl get pod -n ingress-nginx -o wide NAME READY STATUS RESTARTS AGE IP NODE NOMINATED NODE READINESS GATES nginx-ingress-controller-hpnz8 1/1 Running 0 7m36s 192.168.0.28 k8snode02 <none> <none> nginx-ingress-controller-pjxr8 1/1 Running 0 7m36s 192.168.0.27 k8snode01 <none> <none>
测试:
ingress规则还是使用前面我们创建的。
在win主机上直接解析,IP地址为node01或node02任意节点ip即可,访问的时候也无需再加端口: