早期(编译器)优化--javac编译器
java语言的“编译期”其实是一段“不确定”的操作过程,可能是指一个前端编译器把.java变成.class的过程,也可能是指虚拟机的后端运行期编译器(JLT)把字节码转变成机器码的过程,也有可能是使用静态提前编译器(AOT)直接把.java文件直接编译成本地机器代码的过程。现在讨论的是第一种编译器。
Javac编译器


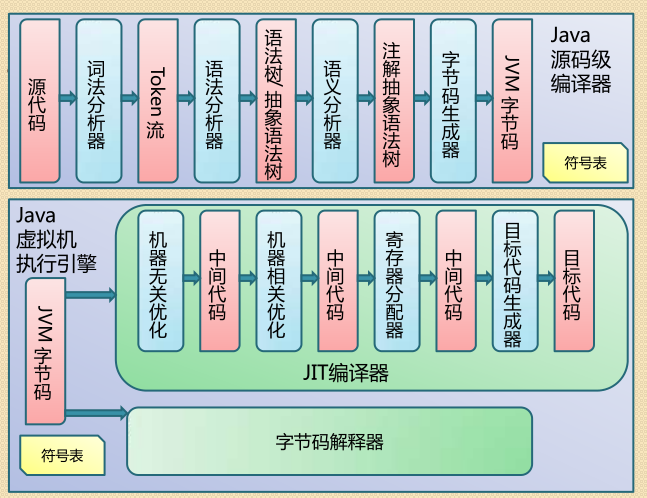
①javac的源码与测试
运行com.sun.tools.javac.Main的main()方法来执行编译,与命令行中使用javac的命令没什么区别.
编译过程可以分为3个过程:
1.解析与填充符号表过程
2.插入式注解处理器的注解处理过程
3.分析与字节码生成过程


②解析与填充符号表
解析步骤由parseFiles完成。解析步骤包括词法解析与语法解析两个过程
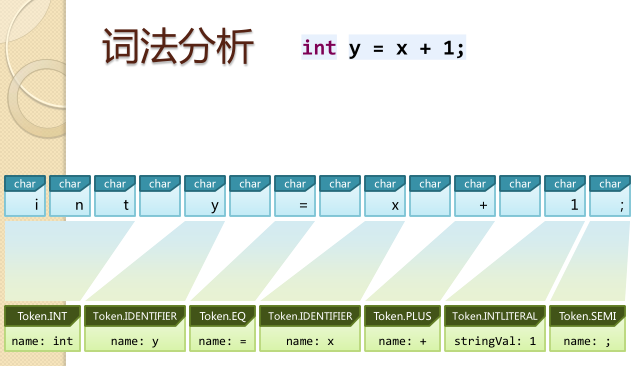
1.词法、语法解析:

词法解析是将字符流转变为标记集合,单个字符是程序编写过程中最小的元素,而标记是编译过程的最小元素,关键字、变量名、字面量、运算符都可以称为标记。
语法分析是根据标记构造抽象语法树的过程,抽象语法树的每一个节点都代表着代码中的一个语法结构,例如包,类型、修饰符、运算符、接口、返回值甚至代码注释等。经过这个步骤以后编译器基本上就不会对源文件进行操作了,后续的操作都建立在抽象语法树之上。

2.填充符号表



③注解处理器



jdk1.5之后,java提供了注解的支持,这些注解与普通的代码一样,在运行期间发挥作用。在jdk1.6中提供了一组插入式注解处理器的标准API在编译期间对注解进行处理,我们可以把它看做一组编译器的插件,在这些插件里面,可以读取、修改、添加抽象语法树中得任意元素。如果这些插件在处理注解期间对语法树进行了修改,编译器将回到解析及填充符号表的过程重新处理,直到所有的插入式朱洁琪都没有再对语法树进行修改为止。
④语义分析和字节码生成
语法分析以后,能保证得到一个结构正确的源程序的抽象,但无法保证是符合逻辑的。语义分析的主要任务是对结构上正确的源程序进行上下文有关性质的审查,如进行类型检查。
比如:
int a=1; boolean b=false; char c=2 ---------------------------------------------------------------- int d=a+c; //编译通过 int d =b+c;//编译错误 char d=a+c//编译错误
三个操作都能形成正确的语法树,但是却无法通过编译。
① 标注检查

语义分析分为标注检查以及数据及控制流分析两个步骤,分别对应attribute方法和flow()方法。
标注检查的内容包括诸如变量使用前是否已被声明、变量和赋值之间的数据类型是否能够匹配等。在标注检查步骤中,还有一个重要的动作称为常量折叠,如果在代码中定义了
int a=1+2
在语法树上仍然能看到1,2,+,但是经过常量折叠,这个插入式表达式的值已经在语法树上标注出来了。由于编译期间进行了常量折叠,所以在代码里面定义a=1+2和a=3没有什么区别。
②数据及控制流分析

对程序上下文逻辑更进一步的验证,可以检查出诸如程序局部变量在使用前是否有赋值、方法的每条路径是否都有返回值、是否所有的受查异常都被正确处理了异常等问题。与类加载时期的数据及控制流分析基本上是一致的,但校检范围由锁区别
//方法1带有final修饰 public void foo(final int arg){ final int var=0; } //方法2没有final修饰 public void foo(int arg){ int var=0; }
将局部变量在常量池中没有符号引用,也就没有访问标志的信息,因此将局部变量声明为final,对运行期是没有影响的,变量的不变性仅仅有编译器在编译期间保证。
③解语法糖


语法糖指在计算机语言中添加的某种语法,这种语法对语言的功能并没与影响,但是更方便程序员使用。
java中最常用的语法糖主要是泛型、变长参数、自动装箱/拆箱等,虚拟机运行时不支持这些语法,它们在编译阶段还原回简单的基础语法结构,这个过程称为解语法糖。
④字节码生成

字节码生成是javac编译过程的最后一个阶段。字节码生成阶段不仅仅把前面各个步骤所生成的信息转化成字节码写到磁盘中,编译器还进行了少量的代码添加和转换工作。
实例构造器<init>()和类构造器<clinit>()方法就是在这个阶段添加到语法树之中的(这里的实例构造器不是指默认函数,如果用户代码中没有提供任何构造函数,那编译器将会添加一个午餐的构造函数,这个工作在填充符号表节段就已经完成了)。这两个构造器的产生过程实际上是一个代码收敛的过程。
<init>()收敛顺序(这里只讨论非静态变量和语句块)为:
1. 父类变量初始化
2. 父类语句块
3. 父类构造函数
4. 子类变量初始化
5. 子类语句块
6. 子类构造函数
<init>()是在new之后才使用的。
<clinit>()
收敛顺序为:
1. 父类静态变量初始化
2. 父类静态语句块
3. 子类静态变量初始化
4. 子类静态语句块
<clinit>()是类加载初始化中使用的。

