TensorFlow中的优化算法
搭建好网络后,常使用梯度下降类优化算法进行模型参数求解,模型越复杂我们在训练神经网络的过程上花的时间就越多,为了解决这一问题,我们就需要找一些优化算法来提高训练速度,TF的tf.train模块中提供了丰富的优化算法,这一节对这些优化器做下简单的对比。
Stochastic Gradient Descent(SGD)
最基础的方法就是GD了,将整个数据集放入模型中,不断的迭代得到模型的参数,当然这样的方法计算资源占用的比较大,那么有没有什么好的解决方法呢?就是把整个数据集分成小批(mini-batch),然后再进行上述操作这就是SGD了,这种方法虽然不能反应整体的数据情况,不过能够很大程度上加快了模型的训练速度,并且也不会丢失太多的准确率
参数的迭代公式
\(w:=w-\alpha*dw\)
Momentum
传统的GD可能会让学习过程十分的曲折,这里我们引入了惯性这一分量,在朝着最优点移动的过程中由于惯性走的弯路会变少
\(m=\beta*m-\alpha*dw\)
\(w:=w-m\)
AdaGrad
这个方法主要是在学习率上面动手脚,每个参数的更新都会有不同的学习率
\(s=s+dw^2\)
\(w:=w-\alpha*dw/\sqrt{s}\)
RMSProp
AdaGrad收敛速度快,但不一定是全局最优,为了解决这一点,加入了Momentum部分
\(s=\beta*s+(1-\beta)dw^2\)
\(w:=w-\alpha*dw/\sqrt{s}\)
Adam
adam是目前比较好的方法,它融合了Momentum和RMSProp方法

代码示例
下面部分使用TF来比较一下这些方法的效果
# -*- coding: utf-8 -*-
"""
@author: VasiliShi
"""
import tensorflow as tf
import matplotlib.pyplot as plt
import numpy as np
def reset_graph(seed=42):
tf.reset_default_graph()
tf.set_random_seed(seed)
np.random.seed(seed)
reset_graph()
plt.figure(1,figsize=(10,8))
x = np.linspace(-1,1,100)[:,np.newaxis] #<==>x=x.reshape(100,1)
noise = np.random.normal(0,0.1,size = x.shape)
y=np.power(x,2) + x +noise #y=x^2 + x+噪音
plt.scatter(x,y)
plt.show()
learning_rate = 0.01
batch_size = 10 #mini-batch的大小
class Network(object):
def __init__(self,func,**kwarg):
self.x = tf.placeholder(tf.float32,[None,1])
self.y = tf.placeholder(tf.float32,[None,1])
hidden = tf.layers.dense(self.x,20,tf.nn.relu)
output = tf.layers.dense(hidden,1)
self.loss = tf.losses.mean_squared_error(self.y,output)
self.train = func(learning_rate,**kwarg).minimize(self.loss)
SGD = Network(tf.train.GradientDescentOptimizer)
Momentum = Network(tf.train.MomentumOptimizer,momentum=0.5)
AdaGrad = Network(tf.train.AdagradOptimizer)
RMSprop = Network(tf.train.RMSPropOptimizer)
Adam = Network(tf.train.AdamOptimizer)
networks = [SGD,Momentum,AdaGrad,RMSprop,Adam]
record_loss = [[], [], [], [], []] #踩的坑不能使用[[]]*5
plt.figure(2,figsize=(10,8))
with tf.Session() as sess:
sess.run(tf.global_variables_initializer())
for stp in range(200):
index = np.random.randint(0,x.shape[0],batch_size)#模拟batch
batch_x = x[index]
batch_y = y[index]
for net,loss in zip(networks,record_loss):
_,l = sess.run([net.train,net.loss],feed_dict={net.x:batch_x,net.y:batch_y})
loss.append(l)#保存每一batch的loss
labels = ['SGD','Momentum','AdaGrad','RMSprop','Adam']
for i,loss in enumerate(record_loss):
plt.plot(loss,label=labels[i])
plt.legend(loc="best")
plt.xlabel("steps")
plt.ylabel("loss")
plt.show()
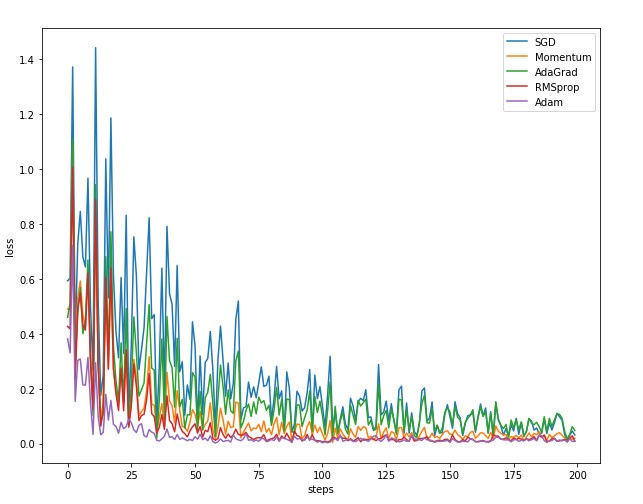
下图是batch_size=10的结果
下图是batch_size=30的结果
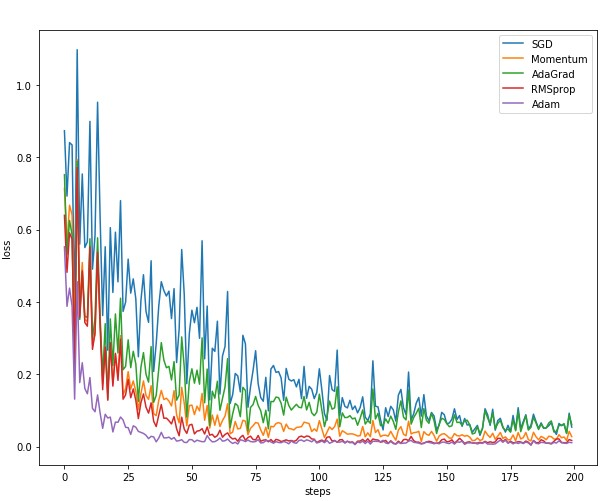
可以看的出Adam方法收敛速度最快,并且波动最小。


 浙公网安备 33010602011771号
浙公网安备 33010602011771号