
MD5碰撞试验
作业题目
本次实验主要是加深大家对MD5碰撞及其原理的理解,使用SEED实验环境中的工具及编程语言,完成以下任务:
- 使用md5collgen生成两个MD5值相同的文件,并利用bless十六进制编辑器查看输出的两个文件,描述你观察到的情况;
- 参考Lab3_task2.c的代码,生成两个MD5值相同但输出不同的两个可执行文件。
- 参考Lab3_task3.c的代码,生成两个MD5值相同但代码行为不相同的可执行文件。
- 回答问题:通过上面的实验,请解释为什么可以做到不同行为的两个可执行文件具有相同的MD5值?
实验步骤及结果
A.
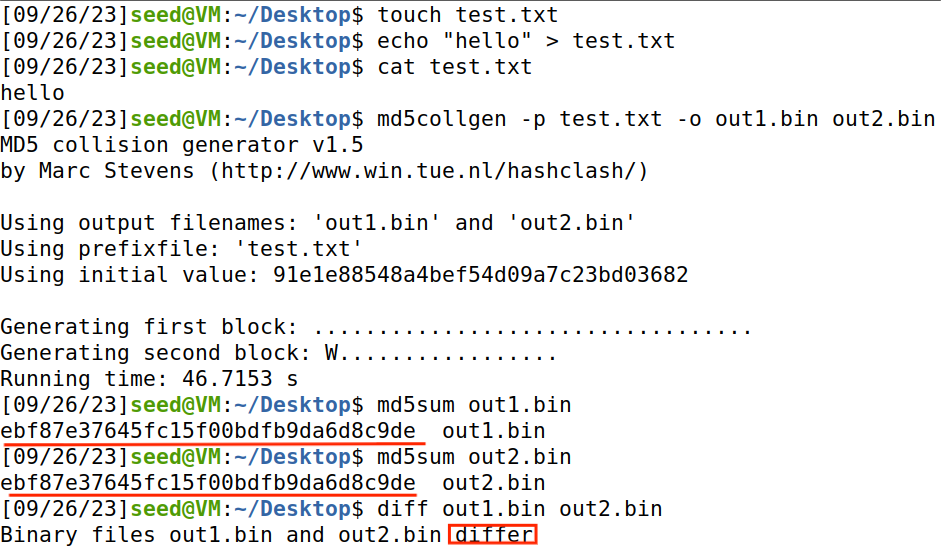
生成一个名为test测试txt文件,往里面存入字符串“hello”,使用md5collgen生成两个文件out1.bin,out2.bin.
这两个文件不同,但md5值相同。
md5算法以64个字节为一组来处理输入,用bless查看out1.bin,out2.bin:


可以发现,输入不足64个字节(或不是64的倍数)时,md5collgen会给输入自动补零。
用test2.txt再测试,test2.txt中有63个字符,加上结束符,一共64个字节作为输入。
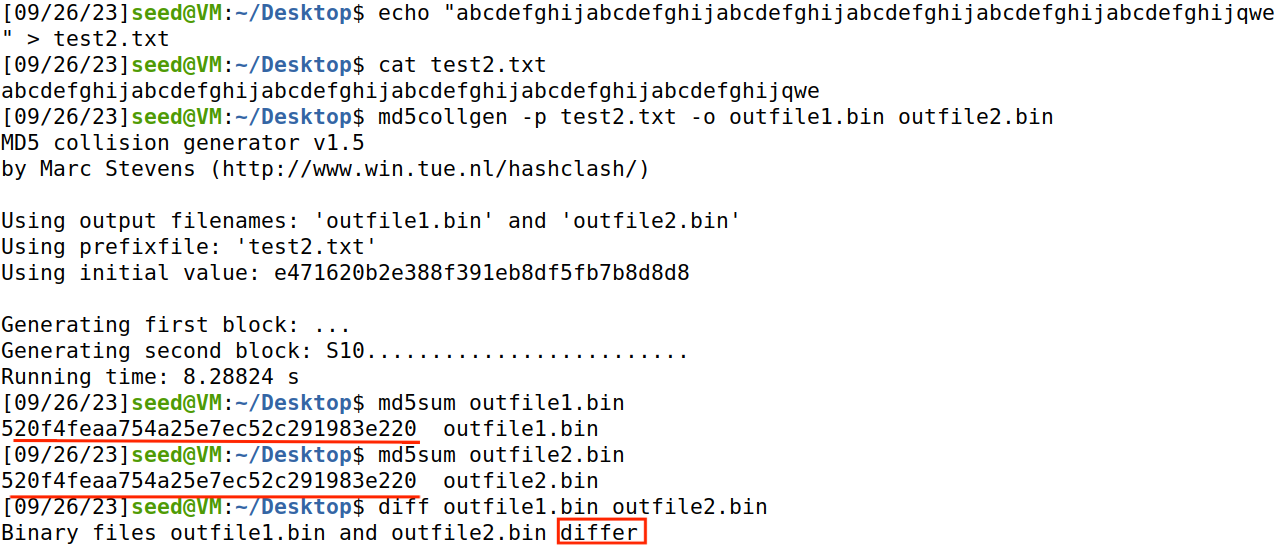
用bless再查看md5collgen生成的文件outfile1.bin,这次没有补零。

查看out1.bin和outfile1.bin的内容:
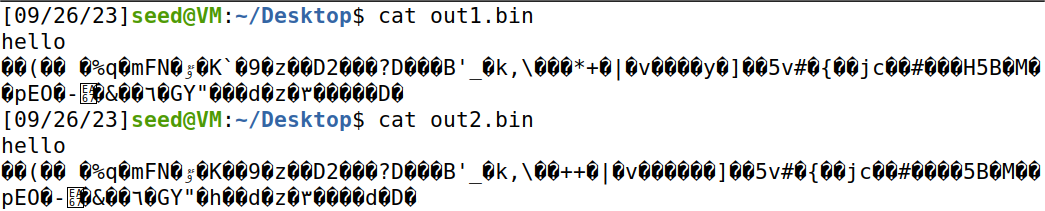
可以发现,除了我们写到txt里的内容,md5collgen又加入了一些东西使生成的两个文件内容不同但md5值相同。
用bless打开out1.bin查看:
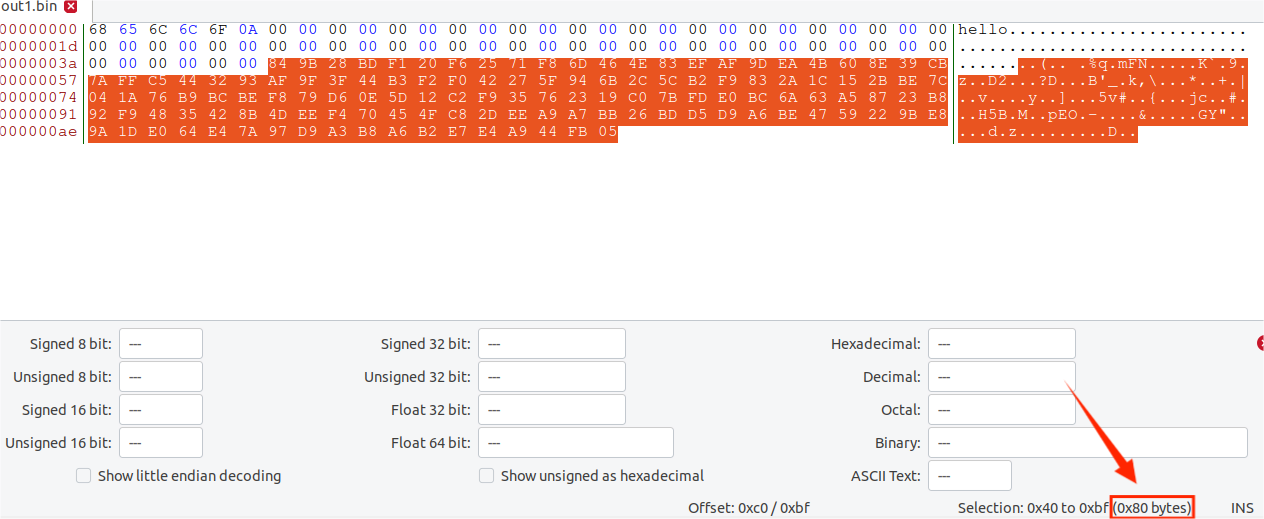
可以发现,这段加入的内容一共128个字节。
在out1.bin和out2.bin中,加入相同的字符串“world”:
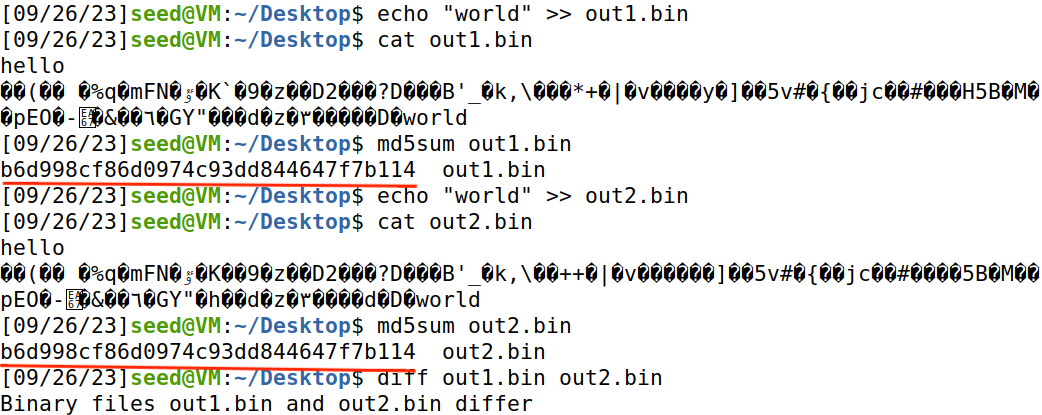
发现两个文件md5值仍然相同,所以,在两个md值相同的文件中分别加入相同的内容,新的两个文件md5值仍然相同。
B.
通过A实验得到的3个技巧可以完成B实验。
修改代码(方便确定数组内容所在位置):
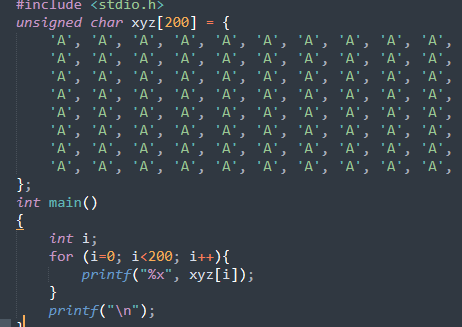
编译c代码为task2:

用bless打开task2,找到数组内容开始的位置在文件的第12320个字节处。
要保证最后得到的是可执行的文件,就要保证md5collgen的输入是64字节的倍数(不能自动补零)。
所以,取task2前12352个字节为prefix,留出128个字节的位置(md5collgen会在生成文件的末尾加上128个字节),取第12480个字节后的内容为suffix。


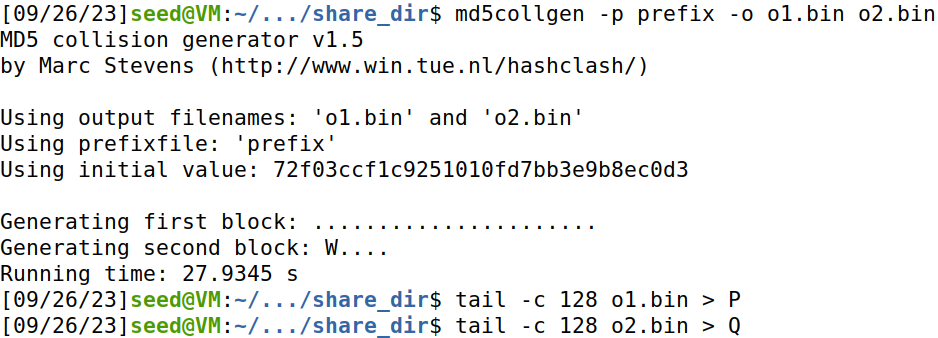
用prefix作为md5collgen的输入,生成两个md5值相同的文件o1.bin,o2.bin。

取出这两个文件的后128个字节为P,Q。
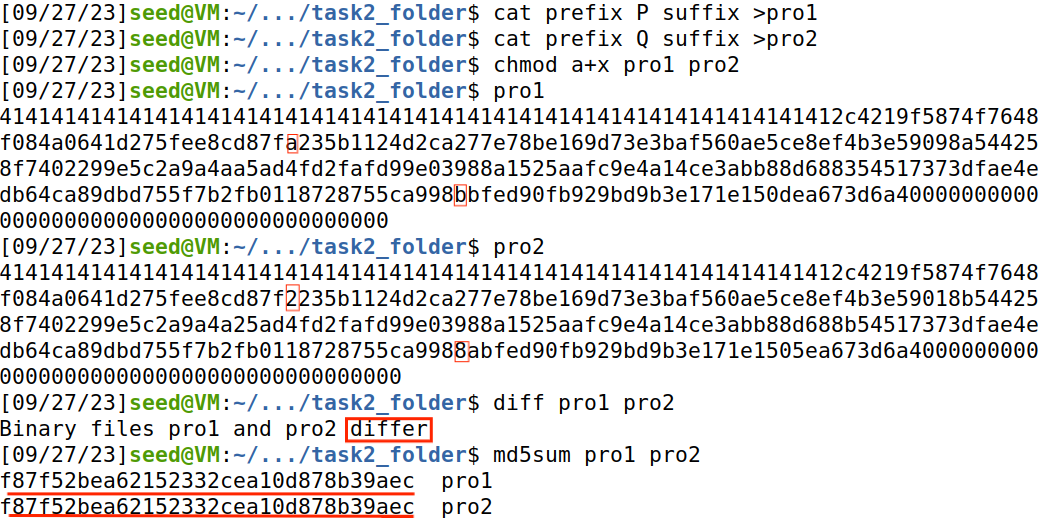
将prefix,P/Q,suffix合并为pro1/pro2,执行,pro1和pro2输出内容不同,md5值相同。
也可以用o1.bin和o2.bin直接和suffix拼接:
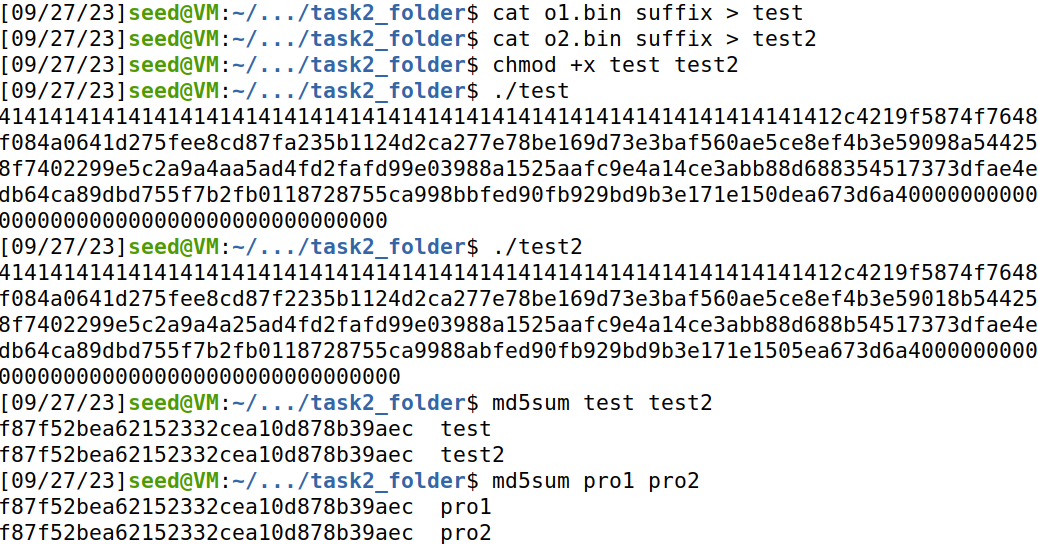
两种方法得到的可执行文件相同:

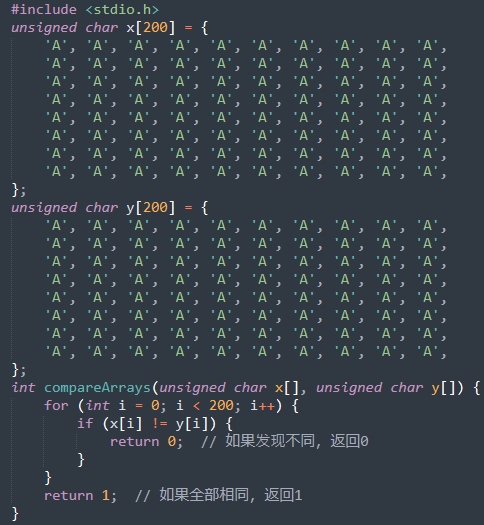
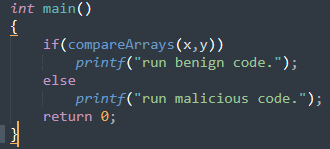
完善task3代码,x和y内容相同就执行良性代码,内容不相同就执行恶性代码:
编译c代码为task3:

用bless查看task3,找到数组开始的位置(12320)
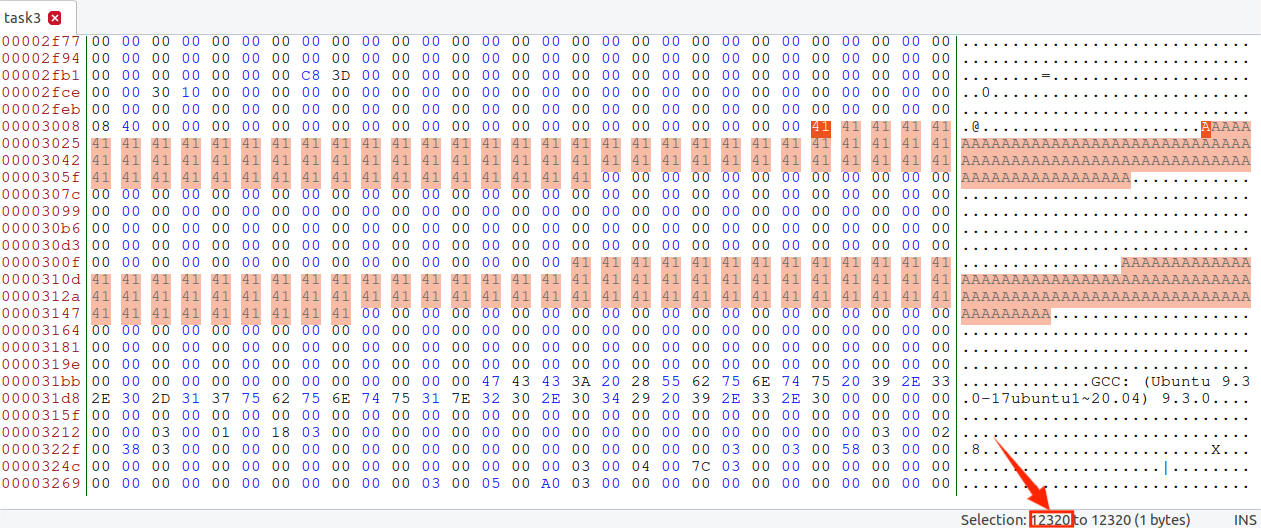
用前12352个字节作为md5cllgen输入,得到o1.bin,o2.bin:
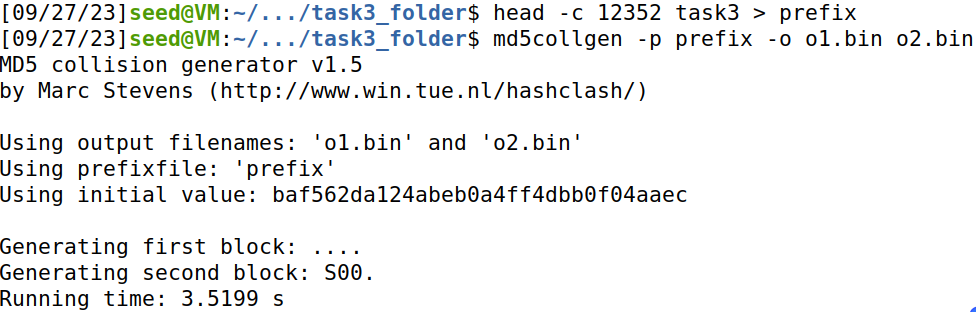
用bless查看o1.bin:

发现数组内容对应o1.bin最后160个字节(数组x前面的一部分)。

取这最后160个字节为P。
从task3中取第12480后的全部字节为suffix:

用bless查看suffix:
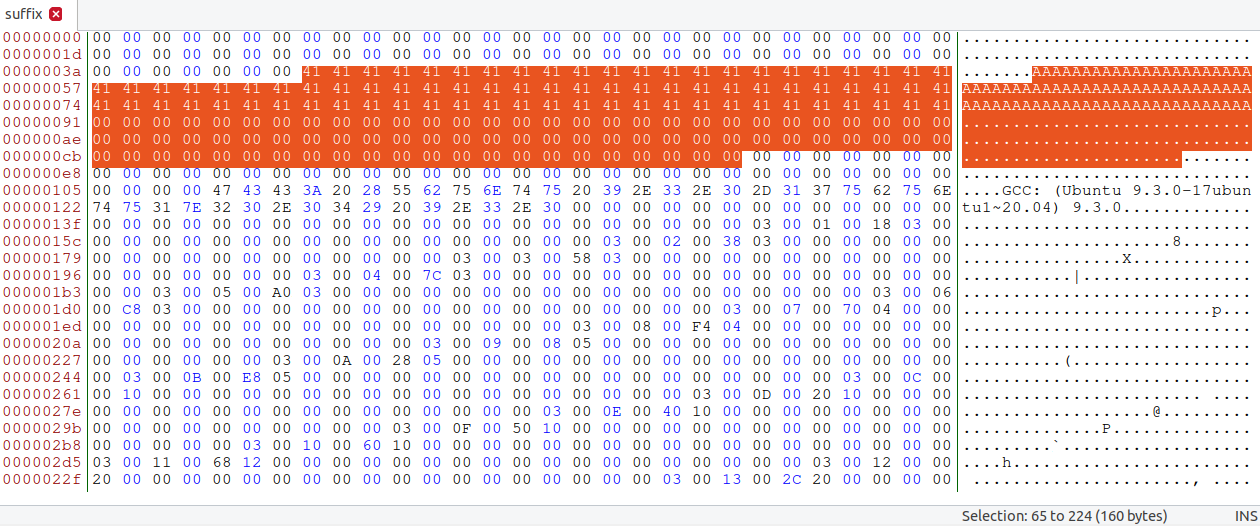
将suffix分割成三部分,a1(数组x剩下的部分),中间部分(数组y前面的一部分,和P字节相同),a2(文件剩余全部):
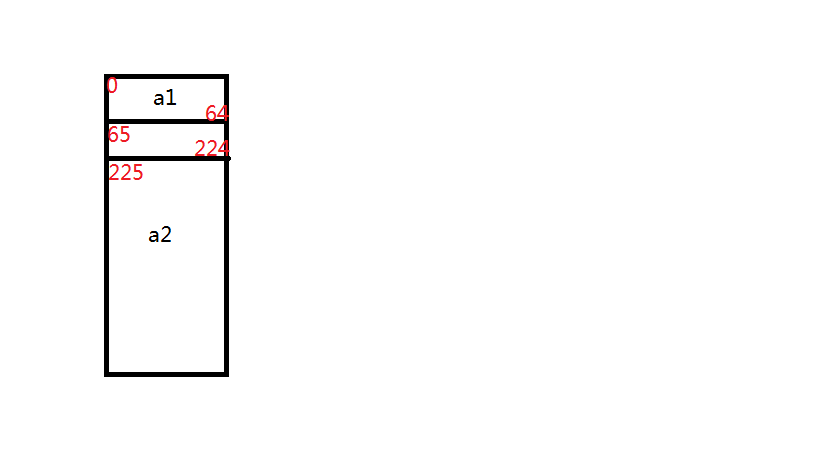
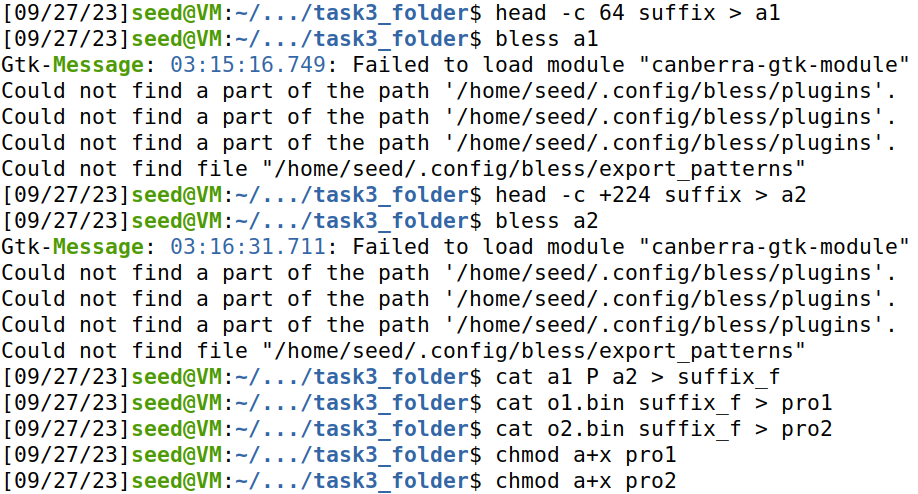

将中间部分替换为P,得到新的suffix_f:
再将suffix_f分别与o1.bin和o2.bin拼接,得到pro1,pro2。

pro1,pro2行为不相同,md5值却相同。
D.
md5的输出是128bit的值,一共有2的128次方种不同的可能,但md5的输入却是无限可能的,所以,不同的输入数据也可以映射到相同的md5值上。
对于两个可执行文件,我们只改变对应代码中数组内容的部分,而不改变代码结构,再利用if判断数组内容来选择不同的行为,这样就可以使它们md5值相同但行为不同了。


【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· winform 绘制太阳,地球,月球 运作规律
· 震惊!C++程序真的从main开始吗?99%的程序员都答错了
· AI与.NET技术实操系列(五):向量存储与相似性搜索在 .NET 中的实现
· 超详细:普通电脑也行Windows部署deepseek R1训练数据并当服务器共享给他人
· 【硬核科普】Trae如何「偷看」你的代码?零基础破解AI编程运行原理