哈希表和冲突解决
1.散列表
散列表(Hash table,也叫哈希表),是根据键(Key)而直接访问在内存存储位置的数据结构。也就是说,它通过计算一个关于键值的函数,将所需查询的数据映射到表中一个位置来访问记录,这加快了查找速度。这个映射函数称做散列函数,存放记录的数组称做散列表。
2.散列函数
散列函数能使对一个数据序列的访问过程更加迅速有效,通过散列函数,数据元素将被更快定位。
(1). 直接定址法:取关键字或关键字的某个线性函数值为散列地址。即{ hash(k)=k} 或{ hash(k)=a*k+b} ,其中a,b为常数(这种散列函数叫做自身函数)
(2). 数字分析法:假设关键字是以r为基的数,并且哈希表中可能出现的关键字都是事先知道的,则可取关键字的若干数位组成哈希地址。
(3). 平方取中法:取关键字平方后的中间几位为哈希地址。通常在选定哈希函数时不一定能知道关键字的全部情况,取其中的哪几位也不一定合适,而一个数平方后的中间几位数和数的每一位都相关,由此使随机分布的关键字得到的哈希地址也是随机的。取的位数由表长决定。
(4). 折叠法:将关键字分割成位数相同的几部分(最后一部分的位数可以不同),然后取这几部分的叠加和(舍去进位)作为哈希地址。
(5). 随机数法
(6). 除留余数法:取关键字被某个不大于散列表表长m的数p除后所得的余数为散列地址。不仅可以对关键字直接取模,也可在折叠法、平方取中法等运算之后取模。对p的选择很重要,一般取素数或m,若p选择不好,容易产生冲突。
3.冲突解决
为了知道冲突产生的相同散列函数地址所对应的关键字,必须选用另外的散列函数,或者对冲突结果进行处理。而不发生冲突的可能性是非常之小的,所以通常对冲突进行处理。常用方法有以下几种:
(1).开放定址法
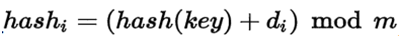
增量序列可有下列取法:{ di=1,2,3...(m-1)}或者为其他线性函数称为线性探测。相当于逐个探测存放地址的表,直到查找到一个空单元,把散列地址存放在该空单元。当称为平方探测、二次探测。伪随机数序列,称为伪随机探测。
(2).单独链表法(链地址法)
将散列到同一个存储位置的所有元素保存在一个链表中。实现时,一种策略是散列表同一位置的所有冲突结果都是用栈存放的,新元素被插入到表的前端还是后端完全取决于怎样方便。
(3).双散列、再散列
根据不同的散列函数,即在同义词产生地址冲突时计算另一个散列函数地址,直到冲突不再发生,这种方法不易产生“聚集”,但增加了计算时间。
(4).建立一个公共的溢出区
4.查询效率
散列表的查找过程基本上和造表过程相同。一些关键码可通过散列函数转换的地址直接找到,另一些关键码在散列函数得到的地址上产生了冲突,需要按处理冲突的方法进行查找。在介绍的三种处理冲突的方法中,产生冲突后的查找仍然是给定值与关键码进行比较的过程。所以,对散列表查找效率的量度,依然用平均查找长度来衡量。查找过程中,关键码的比较次数,取决于产生冲突的多少,产生的冲突少,查找效率就高,产生的冲突多,查找效率就低。因此,影响产生冲突多少的因素,也就是影响查找效率的因素。影响产生冲突多少有以下三个因素:
1. 散列函数是否均匀;
2. 处理冲突的方法;
3. 散列表的装填因子。
散列表的装填因子定义为:α= 填入表中的元素个数 / 散列表的长度
α是散列表装满程度的标志因子。由于表长是定值,α与“填入表中的元素个数”成正比,所以,α越大,填入表中的元素较多,产生冲突的可能性就越大;α越小,填入表中的元素较少,产生冲突的可能性就越小。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号