
cppjieba分词学习笔记
cppjieba分词包主要提供中文分词、关键词提取、词性标注三种功能
一、分词
cppjieba分词用的方法是最大概率分词(MP)和隐马尔科夫模型(HMM),以及将MP和HMM结合成的MixSegment分词器。除此之外,cppjieba支持三种模式的分词:
- 精确模式,试图将句子最精确地切开,适合文本分析;
- 全模式,把句子中所有的可以成词的词语都扫描出来, 速度非常快,但是不能解决歧义;
我/ 来到/ 北京/ 清华/ 清华大学/ 华大/ 大学
- 搜索引擎模式,在精确模式的基础上,对长词再次切分,提高召回率,适合用于搜索引擎分词
小明, 硕士, 毕业, 于, 中国, 科学, 学院, 科学院, 中国科学院, 计算, 计算所, 后, 在, 日本, 京都, 大学, 日本京都大学, 深造
1.最大概率分词(MP)
- 默认基于jieba.dict.utf8生成前缀词典,用户可以添加自己的字典,并且按照一定权重比重一起生成前缀词典。构建字典时将utf-8格式的输入转变为unicode格式
- 分词器中有一个类Prefilter,pre_fileter会将输入的字符串转变为unicode格式,根据某些特殊的字符symbols_,将输入的字符串切分成一段一段,对每一段分别分词
- 构建DAG图,从后往前的动态规划算法,回溯概率最大的切词方法
void Cut(RuneStrArray::const_iterator begin, RuneStrArray::const_iterator end, vector<WordRange>& words, size_t max_word_len = MAX_WORD_LENGTH) const { vector<Dag> dags; dictTrie_->Find(begin, end, dags, max_word_len); //构建DAG图 CalcDP(dags); //从后往前的动态规划算法 CutByDag(begin, end, dags, words);//回溯 }
2.隐藏马尔科夫分词(HMM)
参考:中文分词之HMM模型详解
cppjieba分词中提供了HMM模型的参数文件,保存在hmm_model.utf8中。cppjieba的HMM分词器,实际上就是加载HMM模型,然后根据输入的句子(观察序列),计算可能性最大的状态序列。状态空间由B(开始)、M(中间)、E(结束)、S(单个字)构成。下面是Viterbi算法的过程。
输入样例:
小明硕士毕业于中国科学院计算所定义变量
二维数组 weight[4][15],4是状态数(0:B,1:E,2:M,3:S),15是输入句子的字数。比如 weight[0][2] 代表 状态B的条件下,出现'硕'这个字的可能性。
二维数组 path[4][15],4是状态数(0:B,1:E,2:M,3:S),15是输入句子的字数。比如 path[0][2] 代表 weight[0][2]取到最大时,前一个字的状态,比如 path[0][2] = 1, 则代表 weight[0][2]取到最大时,前一个字(也就是明)的状态是E。记录前一个字的状态是为了使用viterbi算法计算完整个 weight[4][15] 之后,能对输入句子从右向左地回溯回来,找出对应的状态序列。
使用InitStatus对weight二维数组进行初始化
已知InitStatus如下:
#B
-0.26268660809250016
#E
-3.14e+100
#M
-3.14e+100
#S
-1.4652633398537678
且由EmitProbMatrix可以得出
Status(B) -> Observed(小) : -5.79545
Status(E) -> Observed(小) : -7.36797
Status(M) -> Observed(小) : -5.09518
Status(S) -> Observed(小) : -6.2475
所以可以初始化 weight[i][0] 的值如下:
weight[0][0] = -0.26268660809250016 + -5.79545 = -6.05814
weight[1][0] = -3.14e+100 + -7.36797 = -3.14e+100
weight[2][0] = -3.14e+100 + -5.09518 = -3.14e+100
weight[3][0] = -1.4652633398537678 + -6.2475 = -7.71276
注意上式计算的时候是相加而不是相乘,因为之前取过对数的原因。
遍历句子计算整个weight二维数组
//遍历句子,下标i从1开始是因为刚才初始化的时候已经对0初始化结束了
for(size_t i = 1; i < 15; i++)
{
// 遍历可能的状态
for(size_t j = 0; j < 4; j++)
{
weight[j][i] = MIN_DOUBLE;
path[j][i] = -1;
//遍历前一个字可能的状态
for(size_t k = 0; k < 4; k++)
{
double tmp = weight[k][i-1] + _transProb[k][j] + _emitProb[j][sentence[i]];
if(tmp > weight[j][i]) // 找出最大的weight[j][i]值
{
weight[j][i] = tmp;
path[j][i] = k;
}
}
}
}
如此遍历下来,weight[4][15] 和 path[4][15] 就都计算完毕。
确定边界条件和路径回溯
边界条件如下:
对于每个句子,最后一个字的状态只可能是 E 或者 S,不可能是 M 或者 B。
所以在本文的例子中我们只需要比较 weight[1(E)][14] 和 weight[3(S)][14] 的大小即可。
在本例中:
weight[1][14] = -102.492;
weight[3][14] = -101.632;
所以 S > E,也就是对于路径回溯的起点是 path[3][14]。
回溯的路径是:
SEBEMBEBEMBEBEB
倒序一下就是:
BE/BE/BME/BE/BME/BE/S
所以切词结果就是:
小明/硕士/毕业于/中国/科学院/计算/所
到此,一个HMM模型中文分词算法过程就阐述完毕了。
也就是给定我们一个模型,我们对模型进行载入完毕之后,只要运行一遍Viterbi算法,就可以找出每个字对应的状态,根据状态也就可以对句子进行分词。
3、MixSegment是MP和HMM的结合,首先使用MP分词,然后对MP分词的结果使用HMM分词。其实,第二次使用HMM再分对原有分词结果调整得并不多,只是将MP结果中单字顺序收集再分词。
void Cut(RuneStrArray::const_iterator begin, RuneStrArray::const_iterator end, vector<WordRange>& res, bool hmm) const { if (!hmm) { mpSeg_.Cut(begin, end, res); return; } vector<WordRange> words; assert(end >= begin); words.reserve(end - begin); mpSeg_.Cut(begin, end, words); vector<WordRange> hmmRes; hmmRes.reserve(end - begin); for (size_t i = 0; i < words.size(); i++) { //if mp Get a word, it's ok, put it into result if (words[i].left != words[i].right || (words[i].left == words[i].right && mpSeg_.IsUserDictSingleChineseWord( words[i].left->rune))) { res.push_back(words[i]); continue; } // if mp Get a single one and it is not in userdict, collect it in sequence size_t j = i; while (j < words.size() && words[j].left == words[j].right && !mpSeg_.IsUserDictSingleChineseWord(words[j].left->rune)) { j++; } // Cut the sequence with hmm assert(j - 1 >= i); // TODO hmmSeg_.Cut(words[i].left, words[j - 1].left + 1, hmmRes); //put hmm result to result for (size_t k = 0; k < hmmRes.size(); k++) { res.push_back(hmmRes[k]); } //clear tmp vars hmmRes.clear(); //let i jump over this piece i = j - 1; } }
二、关键词提取
cpp结巴的提供了两种关键词提取方法,分别基于TF-IDF和TextRank算法,下面分别介绍
1.基于TF-IDF算法的关键词抽取
TF(term frequency):一个词语在单个文档出现的次数
IDF(Inverse document frequency): 逆文档频率,是一个词语普遍度的度量。某一特定词语的IDF,有总文件数目除以包含该词语的文件数目,再将取得商取对数的得到。
总的来说某一特定文件内的高频率词语,以及词语在整个文件集合中的低文件频率,可以产生出高权重的TF-IDF。
cppjieba中提供接近26万词语的IDF(idf.utf8),对于在idf.utf8中没出现的词语,idf权重取平局值。除此之外,有些词语在文档的出现的频率TF很高,但是对于文档来说没什么实在的意义比如“的”,“是”等,因此cppjieba还提供了了一个1534个词语的stop_words.utf8。
cppjieba中根据权重(tf*idf)排序,取出topN个关键词。
partial_sort(keywords.begin(), keywords.begin() + topN, keywords.end(),Compare);
参考:http://blog.csdn.net/awj3584/article/details/18604901
2.基于TextRank的关键词提取
PageRank根据网页之间的链接关系,建立网页之间的有向图,图中的节点表示每个网页,然后根据这个有向图迭代计算出每个网页的PER值,作为网页重要性排名的依据。TextRank方法与PageRank的方法非常类似,当使用TextRank方法做文本的关键字提取时,首先在给定的共现窗口内(cppjieba中默认为5)根据词语之间的共现关系建立链接关系图,图中的每个节点代表每个节点,每条边的权重表示词语共现的次数。然后根据词语之间链接关系图,迭代计算出每个词语的权重值,根据权重值选出文本中权重值大的几个关键词。
TextRank 一般模型可以表示为一个有向有权图 G =(V, E), 由点集合 V和边集合 E 组成, E 是V ×V的子集。图中任两点 Vi , Vj 之间边的权重为 wji , 对于一个给定的点 Vi, In(Vi) 为 指 向 该 点 的 点 集 合 , Out(Vi) 为点 Vi 指向的点集合。点 Vi 的得分定义如下:
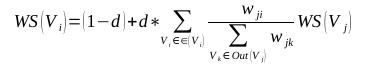
其中, d 为阻尼系数, 取值范围为 0 到 1, 代表从图中某一特定点指向其他任意点的概率, 一般取值为 0.85。使用TextRank 算法计算图中各点的得分时, 需要给图中的点指定任意的初值, 并递归计算直到收敛, 即图中任意一点的误差率小于给定的极限值时就可以达到收敛。cppjieba在实现默认迭代10次。
参考:http://www.cnblogs.com/clover-siyecao/p/5726480.html
参考:http://blog.sohu.com/s/MTAzMjM1NDY0/239636012.html(矩阵形式)
三、词性标注
cppjieba中的词性标注实现过程总的来说是基于词典的查询,词典中存有大约35万词汇的词性。单个词语的词性标注,直接查询词典,词典中不存在一个词语多个词性的问题。词典没有的词语,根据词语的特点的简单的标注为数字(m),英文(eng),以及x。对于整个句子的词性标注是用分词算法分词,然后用上述单个词语词性标注的方法逐个标注词性。由此可见cppjieba的词性标注非常依赖词典。对于句子的词性标注,没有考虑词性之间的关系。
参考: CppJieba代码详解

