一步一步理解word2Vec
一、概述
关于word2vec,首先需要弄清楚它并不是一个模型或者DL算法,而是描述从自然语言到词向量转换的技术。词向量化的方法有很多种,最简单的是one-hot编码,但是one-hot会有维度灾难的缺点,而且one-hot编码中每个单词都是互相独立的,不能刻画词与词之间的相似性。目前最具有代表性的词向量化方法是Mikolov基于skip-gram和negative sampling开发的,也是大家通常所认为的word2vec。这种方法基于分布假设(Distributed Hypothesis)理论,认为不同的词语如果出现在相同的上下文环境中就会有的相似的语义。word2vec最终将向量表示为低维的向量,具有相似语义的单词的向量之间的距离会比较小,部分词语之间的关系能够用向量的运算表示。例如 vec("Germany")+vec("capital")=vec("Berlin")。tensorflow官网中有关于word2vec的教程,可视化的结果非常直接的表现了word2vec的优点。这篇笔记尝试一步一步梳理word2vec,主要是skip-gram和negative sampling,大部分的内容来自于参考资料1,资料1是国外MIT博士word2vec的解读,最为总结学习非常适合。
二、skip-gram 模型
skip-gram是简单的三层网络模型,由输入、映射和输出三层组成。skip-gram是神经网络语言模型的一种,与CBOW相反,skip-gram是由目标词汇来预测上下文词汇,最终目标是最大化语料库Text出现的概率。例如:语料库为“the quick brown fox jumped over the lazy dog”(实际语料库中单词的数量会很非常大),当上下文窗口为1时,skip-gram的任务是从‘quick’预测‘the’和‘brown’,从‘brown’预测‘quick’和‘fox’...因此训练skip-gram的输入输出对(input,output)为:(quick, the), (quick, brown), (brown, quick), (brown, fox), ...
假设给定语料库Text,w是Text中的一个单词,c是w的上下文,skip-gram的目标是最大化语料库Text的概率。theta 是模型的参数,C(w)是单词w的上下文,skip-gram的目标函数如下:
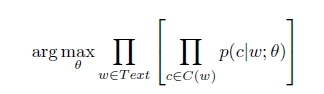
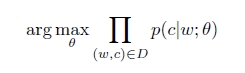
使用softmax表示条件概率p(c|w),Vc,Vw分别表示单词c和w的向量表示,C表示所有可能的上下文,就是语料库Text中所有不同的单词。
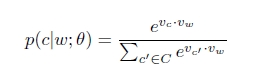
取对数,最终得到skip-gram的目标函数:
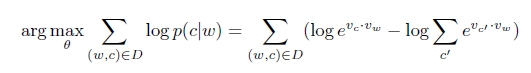
这个目标函数由于需要对所有可能的c‘求和,c’的数量为整个语料库Text中的词,一般会非常大,因此优化上述的目标是的计算代价是非常大的。有两种方法解决这个问题,一是使用层级softmax(Hierarchy softmax)代替softmax,另一种使用Negative sampling。看paper发现两种方法的效果都挺不错的,但是Mikolov挺推荐使用Negative sampling的。
三、Negative sampling
Mikolov 在paper证实了Negative sampling 非常高效。实际上,negative sampling 基于skip-gram模型的,但是使用了另一个优化函数。它的基本思想是考虑(w,c)对是不是来自训练数据,p(D=1|w,c)表示这个(w,c)队来自于语料库,p(D=0|w,c)=1-p(D=1|w,c)表示(w,c)队不是来自于语料库Text。现在优化的目标是:
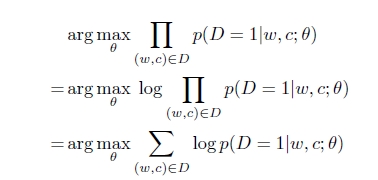
p(D=1|w,c)可以使用sofmax,准确的来说是逻辑回归表示:
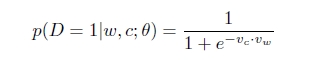
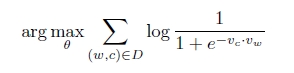
这个目标函数有一个非常简单的解,迭代调整theta使得Vc=Vw,Vc.Vw=k,当比较大的时候k≈40时,p(D=1|w,c)=1,很显然这并不是我们所要的解。我们需要一种机制去防止所有的向量都相等,一种方法是给模型提供一些(w,c)对,使得p(D=1|w,c)=1很小,例如这些(w,c)对并不是Text中真实存在的,而是随机产生的,这就称之为“Negative sampling”。这些随机产生的(w,c)对组成集合D‘。因此最终的Negative sampling 的优化函数如下所示,可以看出求解的计算量并不是很大。Mikolov 在论文中提到,对高频词汇做二次抽样(subsampling)和去除出现次数非常少的词(pruning rare-word)不仅能加快训练的速度,而且能提高模型的准确度,效果会更好。
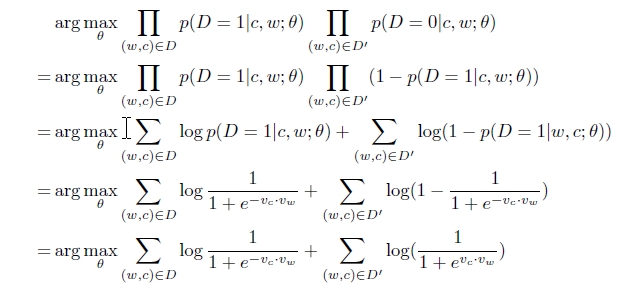
四、实现
参考tennsorflow官方教程:https://www.tensorflow.org/versions/r0.9/tutorials/word2vec/index.html
reference:
[1]. word2vec Explained: Deriving Mikolov et al.'s Negative-Sampling Word-Embedding Method
[2]. Distributed Representations of Words and Phrases and their Compositionality
[3]. Vector Representations of Words
[4]. 深度学习word2Vec笔记

 浙公网安备 33010602011771号
浙公网安备 33010602011771号