

数据湖Hudi与对象存储Minio及Hive\Spark\Flink的集成
本文主要记录对象存储组件Minio、数据湖组件Hudi及查询引擎Hive\Spark之间的兼容性配置及测试情况,Spark及Hive无需多言,这里简单介绍下Minio及Hudi。
MinIO 是在 GNU Affero 通用公共许可证 v3.0 下发布的高性能对象存储。 它是与 Amazon S3 云存储服务兼容的 API。可使用s3a的标准接口进行读写操作。 基于 MinIO 的对象存储(Object Storage Service)服务,能够为机器学习、分析和应用程序数据工作负载构建高性能基础架构。
Minio官网:https://min.io/
Minio中文官网:http://www.minio.org.cn/
GitHub:https://github.com/minio/
Hudi 是由Uber开源的一种数据湖的存储格式,现已属于Apache顶级项目,Hudi在Hadoop文件系统之上提供了更新数据和删除数据的能力以及消费变化数据的能力。
Hudi表类型:Copy On Write
使用Parquet格式存储数据。Copy On Write表的更新操作需要通过重写实现。
Hudi表类型:Merge On Read
使用列式文件格式(Parquet)和行式文件格式(Avro)混合的方式来存储数据。Merge On Read使用列式格式存放Base数据,同时使用行式格式存放增量数据。最新写入的增量数据存放至行式文件中,根据可配置的策略执行COMPACTION操作合并增量数据至列式文件中。
Hudi官网:http://hudi.apache.org/
Hudi中文文档:http://hudi.apachecn.org/
主要的实操步骤如下:
一、测试环境各组件版本说明

spark-3.1.2
hadoop-3.2.2
centos-7
jdk-1.8
hive-3.1.2
flink-1.14.2
scala-2.12.15
hudi-0.11.1
aws-java-sdk-1.11.563
hadoop-aws-3.2.2(需要与hadoop集群版本保持一致)
二、hive/spark的查询兼容性
2.1、hive读取minio文件
hive-3.1.2与hadoop-3.2.2、aws的相关jar包依赖,主要分为以下部分:
aws-java-sdk-1.12.363.jar
aws-java-sdk-api-gateway-1.12.363.jar
aws-java-sdk-bundle-1.12.363.jar
aws-java-sdk-core-1.12.363.jar
aws-java-sdk-s3-1.12.363.jar
aws-lambda-java-core-1.2.2.jar
com.amazonaws.services.s3-1.0.0.jar
hadoop-aws-3.2.2.jar
将以上jar包复制到$HIVE_HOME下;另外需要在$HADOOP_HOME/etc/hadoop下,编辑core-site.xml文件,添加以下内容:
<property>
<name>fs.s3.access.key</name>
<value>minioadmin</value>
</property>
<property>
<name>fs.s3.secret.key</name>
<value>********</value>
</property>
<property>
<name>fs.s3.impl</name>
<value>org.apache.hadoop.fs.s3.S3FileSystem</value>
</property>
<property>
<name>fs.s3a.access.key</name>
<value>minioadmin</value>
</property>
<property>
<name>fs.s3a.secret.key</name>
<value>*********</value>
</property>
<property>
<name>fs.s3a.impl</name>
<value>org.apache.hadoop.fs.s3a.S3AFileSystem</value>
</property>
<property>
<name>fs.s3a.endpoint</name>
<value>192.168.56.101:9000</value>
</property>
<property>
<name>fs.s3a.connection.ssl.enabled</name>
<value>false</value>
</property>
<property>
<name>fs.s3a.path.style.access</name>
<value>true</value>
</property>
添加完以后重启hadoop集群,并将core-site.xml分发到所有datanode,之后再复制到$HIVE_HOME/conf下。并重启hive-server2服务。
测试结果
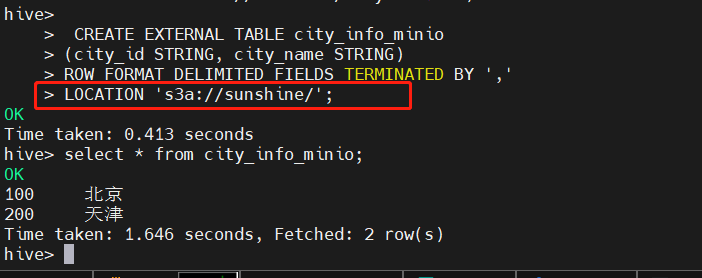
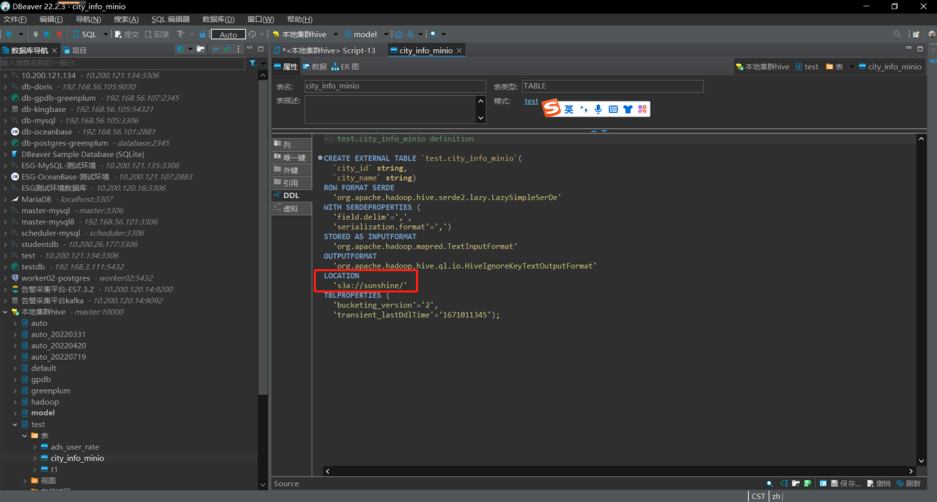
在hive中新建测试表,在此之前,需要在对象存储Minio中提前上传好建表所需的文件。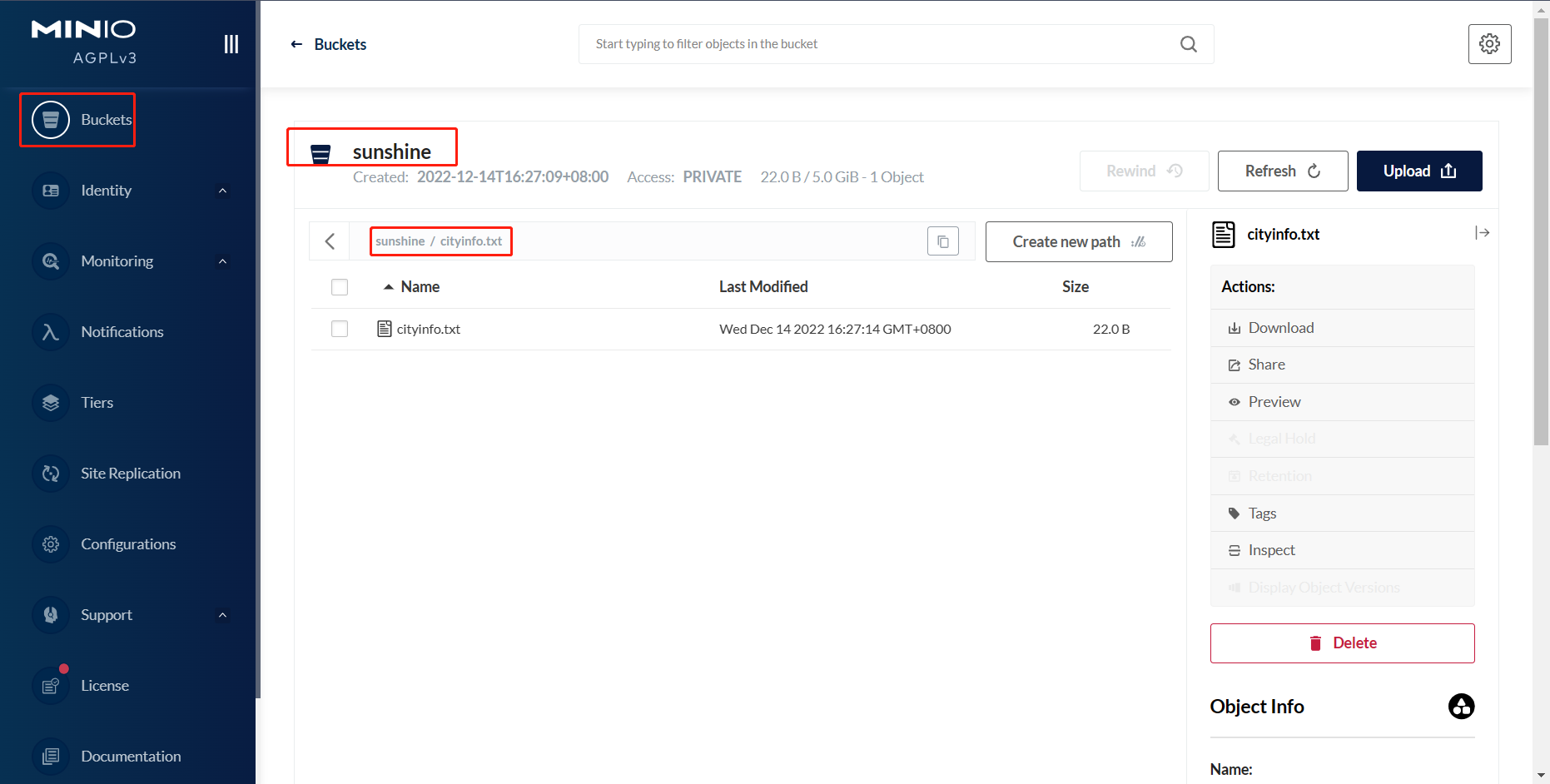
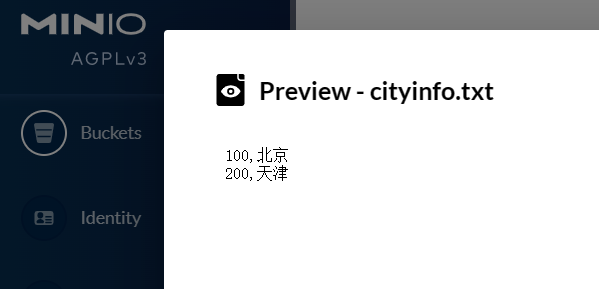
如本次新上传文件为cityinfo.txt,内容为:
2.2、spark读取minio文件
hive-3.1.2与hadoop3.2.2、aws的相关jar包调试,主要分为以下部分:
aws-java-sdk-1.12.363.jar
aws-java-sdk-api-gateway-1.12.363.jar
aws-java-sdk-bundle-1.12.363.jar
aws-java-sdk-core-1.12.363.jar
aws-java-sdk-s3-1.12.363.jar
aws-lambda-java-core-1.2.2.jar
com.amazonaws.services.s3-1.0.0.jar
hadoop-aws-3.2.2.jar
注意:此处一定要在aws官网下载目前最新的aws-java相关jar包,关于hadoop-aws-*.jar,需要与当前hadoop集群的版本适配,否则容易出现一些CLASS或PACKAGE找不到的报错。在此之前,需要将$HIVE_HOME/conf/hive-site.xml复制到$SPARK_HOME/conf下
测试结果
进入spark-shell客户端进行查看,命令为:
$SPARK_HOME/bin/spark-shell \
--conf spark.hadoop.fs.s3a.access.key=minioadmin \
--conf spark.hadoop.fs.s3a.secret.key=********** \
--conf spark.hadoop.fs.s3a.endpoint=192.168.56.101:9000 \
--conf spark.hadoop.fs.s3a.connection.ssl.enabled=false \
--master spark://192.168.56.101:7077
注意此处命令一定要写明endpoint,需要域名或IP地址,执行以下操作:
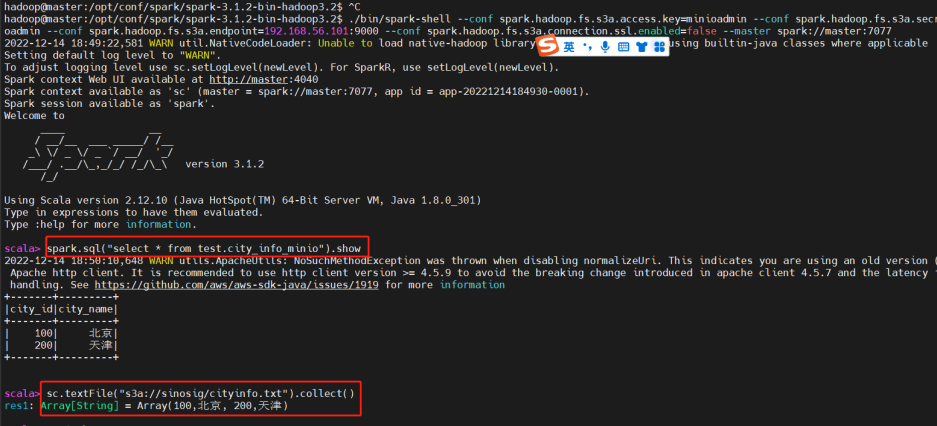
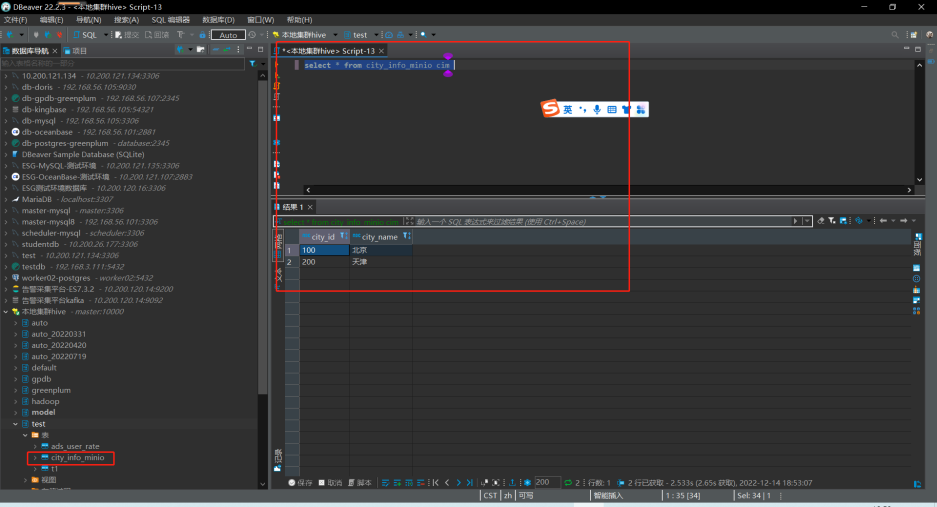
可以看到无论是通过rdd方式还是通过sql方式,都可以读取到minio对象存储的文件。
2.3、dbeaver测试minio文件外部表
可通过dbeaver或其他连接工具,进行简单查询或者关联查询。
三、hudi与对象存储的互相操作可行性
spark操作hudi
需要spark.hadoop.fs.s3a.xxx配置项的一些具体信息,如key\secret\endpoint等信息。
spark-shell \
--packages org.apache.hudi:hudi-spark3-bundle_2.11:0.11.1,org.apache.hadoop:hadoop-aws:3.2.2,com.amazonaws:aws-java-sdk:1.12.363 \
--conf 'spark.serializer=org.apache.spark.serializer.KryoSerializer' \
--conf 'spark.sql.catalog.spark_catalog=org.apache.spark.sql.hudi.catalog.HoodieCatalog' \
--conf 'spark.sql.extensions=org.apache.spark.sql.hudi.HoodieSparkSessionExtension' \
--conf 'spark.hadoop.fs.s3a.access.key=minioadmin' \
--conf 'spark.hadoop.fs.s3a.secret.key=<your-MinIO-secret-key>'\
--conf 'spark.hadoop.fs.s3a.endpoint=192.168.56.101:9000' \
--conf 'spark.hadoop.fs.s3a.path.style.access=true' \
--conf 'fs.s3a.signing-algorithm=S3SignerType'
以上启动spark并初始化加载hudi的jar依赖,大概输出为:
hadoop@master:/opt/conf/spark/spark-3.1.2-bin-hadoop3.2/jars$ spark-shell \
> --packages org.apache.hudi:hudi-spark3-bundle_2.11:0.11.1,org.apache.hadoop:hadoop-aws:3.2.2,com.amazonaws:aws-java-sdk:1.12.363 \
> --conf 'spark.serializer=org.apache.spark.serializer.KryoSerializer' \
> --conf 'spark.sql.catalog.spark_catalog=org.apache.spark.sql.hudi.catalog.HoodieCatalog' \
> --conf 'spark.sql.extensions=org.apache.spark.sql.hudi.HoodieSparkSessionExtension' \
> --conf 'spark.hadoop.fs.s3a.access.key=minioadmin' \
> --conf 'spark.hadoop.fs.s3a.secret.key=<your-MinIO-secret-key>'\
> --conf 'spark.hadoop.fs.s3a.endpoint=192.168.56.101:9000' \
> --conf 'spark.hadoop.fs.s3a.path.style.access=true' \
> --conf 'fs.s3a.signing-algorithm=S3SignerType'
Warning: Ignoring non-Spark config property: fs.s3a.signing-algorithm
:: loading settings :: url = jar:file:/opt/conf/spark/spark-3.1.2-bin-hadoop3.2/jars/ivy-2.4.0.jar!/org/apache/ivy/core/settings/ivysettings.xml
Ivy Default Cache set to: /home/hadoop/.ivy2/cache
The jars for the packages stored in: /home/hadoop/.ivy2/jars
org.apache.hudi#hudi-spark3-bundle_2.11 added as a dependency
org.apache.hadoop#hadoop-aws added as a dependency
com.amazonaws#aws-java-sdk added as a dependency
:: resolving dependencies :: org.apache.spark#spark-submit-parent-f268e29b-59b7-4ee6-8ace-eae921495080;1.0
confs: [default]
found org.apache.hadoop#hadoop-aws;3.2.2 in central
found com.amazonaws#aws-java-sdk-bundle;1.11.563 in central
found com.amazonaws#aws-java-sdk;1.12.363 in central
found com.amazonaws#aws-java-sdk-sagemakermetrics;1.12.363 in central
found com.amazonaws#aws-java-sdk-core;1.12.363 in central
found commons-logging#commons-logging;1.1.3 in central
found commons-codec#commons-codec;1.15 in central
found org.apache.httpcomponents#httpclient;4.5.13 in central
found org.apache.httpcomponents#httpcore;4.4.13 in central
found software.amazon.ion#ion-java;1.0.2 in central
found com.fasterxml.jackson.core#jackson-databind;2.12.7.1 in central
found com.fasterxml.jackson.core#jackson-annotations;2.12.7 in central
found com.fasterxml.jackson.core#jackson-core;2.12.7 in central
found com.fasterxml.jackson.dataformat#jackson-dataformat-cbor;2.12.6 in central
found joda-time#joda-time;2.8.1 in local-m2-cache
found com.amazonaws#jmespath-java;1.12.363 in central
found com.amazonaws#aws-java-sdk-pipes;1.12.363 in central
found com.amazonaws#aws-java-sdk-sagemakergeospatial;1.12.363 in central
found com.amazonaws#aws-java-sdk-docdbelastic;1.12.363 in central
found com.amazonaws#aws-java-sdk-omics;1.12.363 in central
found com.amazonaws#aws-java-sdk-opensearchserverless;1.12.363 in central
found com.amazonaws#aws-java-sdk-securitylake;1.12.363 in central
found com.amazonaws#aws-java-sdk-simspaceweaver;1.12.363 in central
found com.amazonaws#aws-java-sdk-arczonalshift;1.12.363 in central
found com.amazonaws#aws-java-sdk-oam;1.12.363 in central
found com.amazonaws#aws-java-sdk-iotroborunner;1.12.363 in central
found com.amazonaws#aws-java-sdk-chimesdkvoice;1.12.363 in central
found com.amazonaws#aws-java-sdk-ssmsap;1.12.363 in central
found com.amazonaws#aws-java-sdk-scheduler;1.12.363 in central
found com.amazonaws#aws-java-sdk-resourceexplorer2;1.12.363 in central
found com.amazonaws#aws-java-sdk-connectcases;1.12.363 in central
found com.amazonaws#aws-java-sdk-migrationhuborchestrator;1.12.363 in central
found com.amazonaws#aws-java-sdk-iotfleetwise;1.12.363 in central
found com.amazonaws#aws-java-sdk-controltower;1.12.363 in central
found com.amazonaws#aws-java-sdk-supportapp;1.12.363 in central
found com.amazonaws#aws-java-sdk-private5g;1.12.363 in central
found com.amazonaws#aws-java-sdk-backupstorage;1.12.363 in central
found com.amazonaws#aws-java-sdk-licensemanagerusersubscriptions;1.12.363 in central
found com.amazonaws#aws-java-sdk-iamrolesanywhere;1.12.363 in central
found com.amazonaws#aws-java-sdk-redshiftserverless;1.12.363 in central
found com.amazonaws#aws-java-sdk-connectcampaign;1.12.363 in central
found com.amazonaws#aws-java-sdk-mainframemodernization;1.12.363 in central
初次加载会稍慢,需要等候全部加载完毕。以上加载完毕后,进入改界面,证明所有依赖全部不存在冲突。如果服务器无法连接公网,则需手动安装依赖到本地仓库。
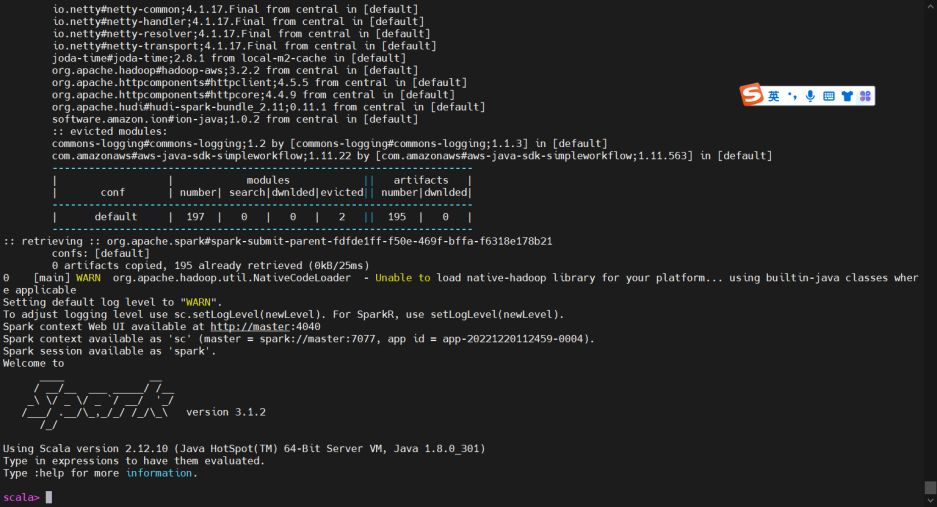
成功加载hudi部分jar包进入spark-shell客户端
之后需要依照自行编译的hudi源代码,查看hadoop、spark、hudi、scala四者之间互相依赖的jar包,大概有10数个,要注意,scala小版本之间的变化也比较频繁看,如scala-2.12.10与scala-2.12.12之间一些基础类包都有版本差异,API调用会报错,目前已针对spark-3.1.2、hadoop-3.2.3、scala-2.12.12、java8、aws-1.12.368之间的互相依赖进行了调整,能够进入spark-shell通过hudi操作minio的s3a接口,需要主要的错误如:
aws小版本与hadoop-aws协议的冲突问题,这里选定aws-java-sdk-1.12.368即可
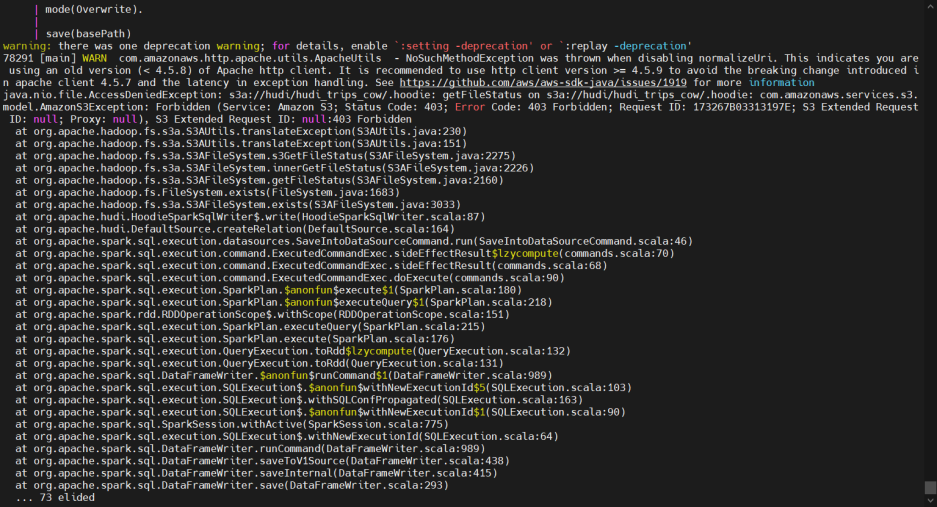
以下是比较复杂的多方依赖jar包,需要通过源码的pom文件来确认小版本。
其他需要注意的点就是,某些内网环境或者屏蔽阿里云maven镜像等的服务器,需要手动安装
org.apache.spark.sql.adapter.BaseSpark3Adapter
org/apache/spark/internal/Logging
com.fasterxml.jackson.core.jackson-annotations/2.6.0/jackson-annotations-2.6.0.jar
mvn install:install-file -Dmaven.repo.local=/data/maven/repository -DgroupId=com.fasterxml.jackson.core -DartifactId=jackson-annotations -Dversion=2.6.0 -Dpackaging=jar -Dfile=/opt/conf/spark/spark-3.1.2-bin-hadoop3.2/jars/jackson-annotations-2.6.0.jar
mvn install:install-file -Dmaven.repo.local=/data/maven/repository -DgroupId=org.apache.spark -DartifactId=hudi-spark-bundle_2.12 -Dversion=0.11.1 -Dpackaging=jar -Dfile=/opt/conf/hudi/hudi-0.11.1/packaging/hudi-spark-bundle/target/original-hudi-spark-bundle_2.11-0.11.1.jar
vn install:install-file -Dmaven.repo.local=/data/maven/repository -DgroupId=org.apache.hudi -DartifactId=hudi-spark-bundle_2.12 -Dversion=0.11.1 -Dpackaging=jar -Dfile=/opt/conf/hudi/hudi-0.11.1/packaging/hudi-spark-bundle/target/original-hudi-spark-bundle_2.11-0.11.1.jar
mvn install:install-file -Dmaven.repo.local=/data/maven/repository -DgroupId=com.amazonaws -DartifactId=aws-java-sdk-bundle -Dversion=1.12.368 -Dpackaging=jar -Dfile=/opt/conf/spark/spark-3.1.2-bin-hadoop3.2/jars/aws-java-sdk-bundle-1.12.363.jar
四、通过spark操作hudi进行对象存储minio的s3a接口读写
在spark集群中初始化hudi
引入相关的jar包
import org.apache.hudi.QuickstartUtils._
import scala.collection.JavaConversions._
import org.apache.spark.sql.SaveMode._
import org.apache.hudi.DataSourceReadOptions._
import org.apache.hudi.DataSourceWriteOptions._
import org.apache.hudi.config.HoodieWriteConfig._
import org.apache.hudi.common.model.HoodieRecord
val tableName = "hudi_trips_cow"
val basePath = "s3a://sunshine/hudi_trips_cow"
val dataGen = new DataGenerator
val inserts = convertToStringList(dataGen.generateInserts(10))
val df = spark.read.json(spark.sparkContext.parallelize(inserts, 2))
df.write.format("hudi").
options(getQuickstartWriteConfigs).
option("PRECOMBINE_FIELD_OPT_KEY", "ts").
option("RECORDKEY_FIELD_OPT_KEY", "uuid").
option("PARTITIONPATH_FIELD_OPT_KEY", "partitionpath").
option("TABLE_NAME", tableName).
mode(Overwrite).
save(basePath)
五、通过Flink操作hudi进行对象存储minio的s3a接口读写
- Flink添加Hive支持:
想让Flink集群支持Hive访问,需要在Flink的conf/flink-conf.yaml文件中添加以下配置:
# Use Hive catalog
catalogs:
- name: hive
type: hive
hive-conf-dir: /path/to/hive/conf
hive-version: 2.3.4
注意需要将hive-conf-dir替换为你的Hive配置目录的路径。
- Flink添加亚马逊s3a接口支持,需要在Flink的conf/flink-conf.yaml文件中添加以下配置:
# Use S3A file system
fs.s3a.access.key: your_access_key
fs.s3a.secret.key: your_secret_key
fs.s3a.endpoint: your_s3a_endpoint
fs.s3a.path.style.access: true
注意需要将your_access_key、your_secret_key、your_s3a_endpoint替换为你的S3A访问密钥、S3A访问密钥、S3A访问地址。
- 通过Flink在Hive中创建hudi表
-- 注册Hive表 CREATE TABLE hudi_table ( id BIGINT, name STRING, age INT, city STRING, ts TIMESTAMP, action STRING, partition STRING ) WITH ( 'connector' = 'hive', 'database-name' = 'your_database_name', 'table-name' = 'hudi_table', 'sink.partition-commit.trigger' = 'partition-time', 'sink.partition-commit.delay' = '1 h', 'sink.partition-commit.policy.kind' = 'metastore,success-file', 'sink.writer.type' = 'hudi', 'sink.writer.hudi.table.type' = 'MERGE_ON_READ', 'sink.writer.hudi.record-key.field' = 'id', 'sink.writer.hudi.precombine.field' = 'ts', 'sink.writer.hudi.partition.path.field' = 'partition', 'sink.writer.hudi.table.name' = 'hudi_table', 'sink.writer.hudi.table.path' = 's3a://your_minio_bucket/hudi_table', 'sink.writer.hudi.options' = 'hoodie.datasource.hive_sync.enable=true', 'sink.writer.hudi.hive.database' = 'your_database_name', 'sink.writer.hudi.hive.table' = 'hudi_table' ); -- 查询Hudi表 SELECT * FROM hudi_table;
注意需要将your_database_name、your_minio_bucket替换为你的数据库名称和Minio存储桶名称。


【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· 被坑几百块钱后,我竟然真的恢复了删除的微信聊天记录!
· 没有Manus邀请码?试试免邀请码的MGX或者开源的OpenManus吧
· 【自荐】一款简洁、开源的在线白板工具 Drawnix
· 园子的第一款AI主题卫衣上架——"HELLO! HOW CAN I ASSIST YOU TODAY
· Docker 太简单,K8s 太复杂?w7panel 让容器管理更轻松!