

SQL Serverf 索引 - 索引压缩 、附加特性 <十>
一、索引压缩
数据和索引压缩在SQL Server2008被引入。压缩一个索引意味着将在一个页面中获得更多的关键字信息。这可以造成重大的性能改进,因为存储索引需要的页面和索引级别更少。因为索引中的键值被压缩和解压缩,也将造成CPU和内存的开销,所以这并不是适合所有索引的方案。
默认情况下,索引将不会被压缩。必须明确地在创建索引时要求索引被压缩。有两种压缩类型:行级压缩和页面级压缩。索引中的非叶子页面不接受页面类型压缩。
创建压缩索引的语法如下:
CREATE NONCLUSTERED INDEX IX_Person_Name ON PersonOneMillion(Name) WITH(DATA_COMPRESSION = Page)
下面以一个示例来看看压缩索引的作用:
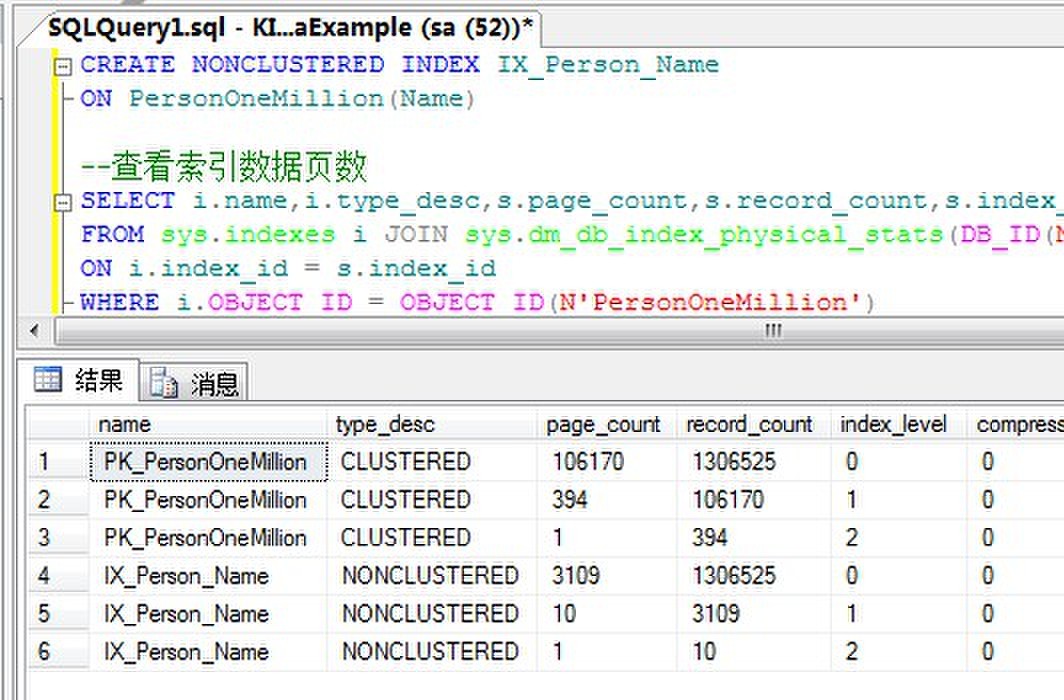
正常索引:
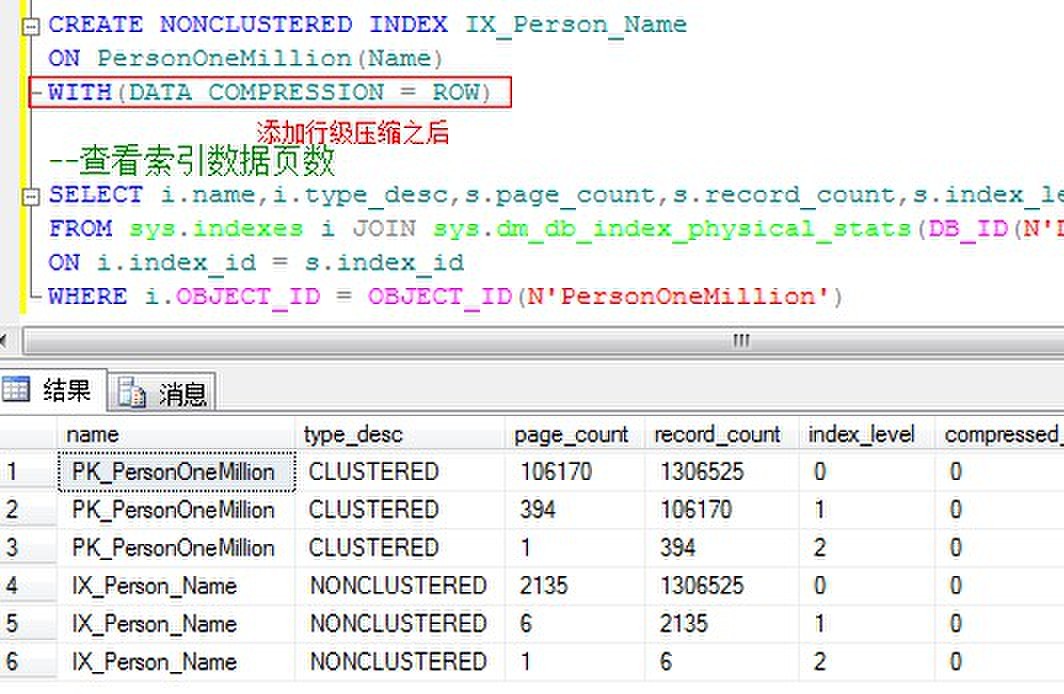
行级压缩索引:
页面级压缩索引:

我们看到对于100万索引的Name列索引,索引数据页面分别是:
| 普通索引 | 行索引 | 页面索引 |
| 3109 | 2135 | 1962 |
从上面的例子我们可以得出结论,的确压缩能够能够大幅减少索引的页面量。但是举个很简单的例子,如果一台数据库服务器上,内存和CPU已是瓶颈,那么压缩数据作用实际上并不大。
至于更具体的哪个更好,这个有时间了再慢慢测试。现在只是知道了索引可以压缩已减少索引数据页面数量。
附上一个查看索引消息的SQL语句:

--查看索引数据页数 SELECT i.name,i.type_desc,s.page_count,s.record_count,s.index_level,compressed_page_count FROM sys.indexes i JOIN sys.dm_db_index_physical_stats(DB_ID(N'DataExample'),OBJECT_ID(N'PersonOneMillion'),NULL,NULL,'DETAILED') AS s ON i.index_id = s.index_id WHERE i.OBJECT_ID = OBJECT_ID(N'PersonOneMillion')
二、 附加特性
1、不同的列排序顺序
SQL Server支持使用不同的排序顺序为索引的不同列创建一个复杂的索引。如果希望一个索引的第一列按照升序排列二第二列按照降序排列,可以用如下语句完成:
CREATE NONCLUSTERED INDEX IX ON Table(c1 ASC,c2 DESC)
2、BIT数据类型列上的索引
SQL Server允许创建在BIT数据类型列上的索引。创建BIT数据类型列上的索引的能力本身不是一个大的优点,因为这样的列只能有两个不同的值。这么低的选择性的列通常不是好的索引后选择。但是,这个功能在考虑覆盖索引时非常有用。因为覆盖索引需要包含所有搜索中的返回列,而在索引中添加BIT数据类型列将使得覆盖索引在需要时包含这样的列。
3、CREATE INDEX语句也会使用索引提升速度
CREATE INDEX操作被集成到查询处理器。优化器可能使用已有的索引来减少扫描开销并在创建索引时排序。
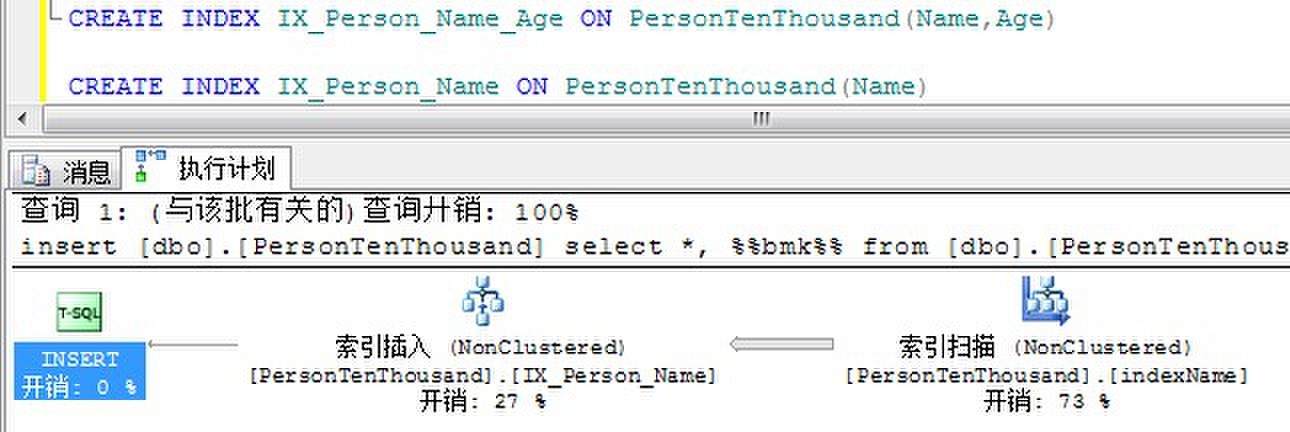
在第一个索引中由于已经包含了Name列,而第二个索引也要使用Name列的时候,创建索引SQL Server直接使用索引扫描的方式来创建索引。
4、并行索引创建
SQL Server支持CREATE INDEX语句的并行计划,正如在其他SQL查询中一样。在一个多处理器的机器上,索引创建不限于单个处理器而是从多个处理器中获益。可以使用SQL Server的max degree of parallelism配置参数来控制用于CREATE INDEX语句中的处理器数量。这个参数的默认值为0,0表示可以使用任意的CPU数量。
EXEC sp_configure 'max degree of parallelism' --默认值为0 EXEC sp_configure 'max degree of parallelism', 2 --使用2个CPU RECONFIGURE WITH OVERRIDE
这个配置设置立即生效,不需要重启服务器。
查询提示MAXDOP可以用于CREATE INDEX语句。而且,CREATE INDEX特性只可以用于SQL Server 2005和2008企业版。

