
kubernetes机理之调度器以及控制器
一 了解调度器
1.1 调度器是如何将一个pod调度到节点上的
我们都已然知晓了,API服务器不会主动的去创建pod,只是拉起系统组件,这些组件订阅资源状态的通知,之后创建相应的资源,而负责调度pod的则是调度器,调度器也不会主动去创建pod,当它从API订阅得知自己需要调度pod的时候,会将pod以一些列调度策略,调度到最佳的节点上,并通过API服务器更新pod定义,API服务器再会告诉kubelte,相应节点上的kubelet则会去拉取镜像和创建容器
可以在集群中运行多个调度器,之后在需要创建的pod上添加schedulerName字段属性指定调度器,所有pod里面默认的这个字段都是默认的调度器,那些pod设置了另外的schedulerName的时候,默认的调度器会忽略它,要么使用其他的调度器来进行调度,要么手动的去调度pod
关于调度过程以及设计的算法绝对不止宏观上面的这些,里面的调度策略以及高度调度策略有很多很多,但是我们不需要特别的去关心这些
二 了解kubernetes集群里面的控制器的工作原理
2.1 前面提到的,API服务器只做了存储资源到etcd以及通知客户端的工作,而调度器只是给pod分配了节点,所以需要有活跃的组件确保系统真实状态朝着API服务器的状态进行收敛,这个工作是由控制器来实现。
2.2 控制器包括以下几种
-
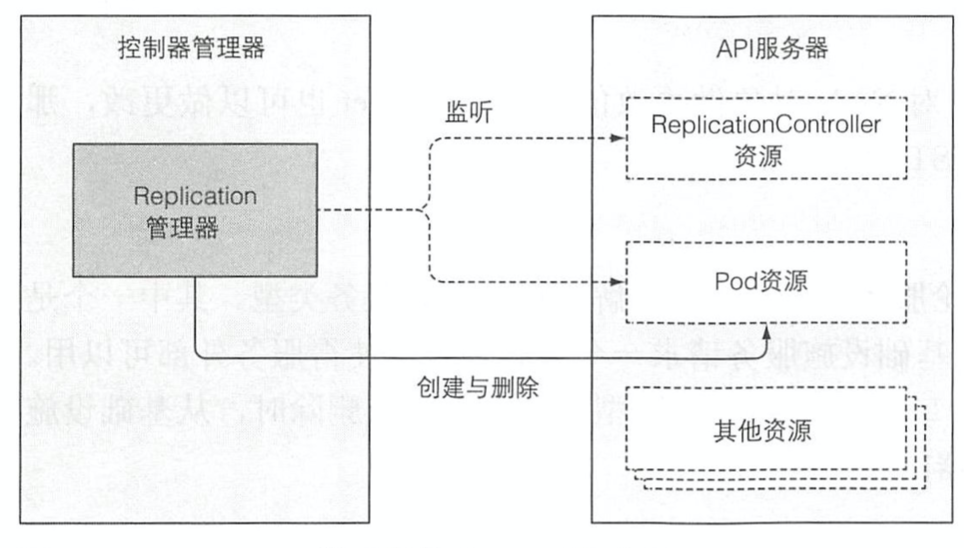
- Replication管理器
- ReplicaSet,DaemonSet以及Job控制器
- Deployment控制器
- StatefulSet控制器
- Node控制器
- Service控制器
- Endpoints控制器
- Namespace控制器
- PersistentVolume控制器
- 其他
2.3 了解控制器做了些什么以及如何做的
控制器做了许多不同的事情,但是它们都通过API服务器监听资源的变更,并且不论是创建对象,更新对象以及删除已有的对象的操作,这些操作甚至涵盖了新建其他资源以及更新监听资源的本身(例如更新资源对象的status)
简单一点来说就是,控制器执行一个调和的循环,将集群实际的资源状态调整为期望状态,然后将新的实际状态写入资源的status部分,控制器之间不会进行通信,它们甚至都不知道其他控制器的存在,每个控制器都连接API服务器,并且通过监听机制,请求订阅该控制器负责的一些列资源的变更
我们来列举几个控制器的作用以及功能
-
- RC/RS/DaemonSet/Job/statefulset的控制器
- 我们知道RC控制器的作用就是用来保障集群中的pod数量符合资源mainifest定义并且随时相应资源mainifest里面的replicas的变化
- 为实时达到以上要求,则必须不停的去对集群里面的pod进行轮询问,这是一个比较过时的办法,通过前面的学习,我们已然知晓在kubernetes集群里面这种场景一般都是通过监听对该类资源发生事情变化的通知,那么我们的RC控制器同样也是监听机制订阅集群内部可能影响replicas变化和符合条件的pod数量变化的事件,任何该类的变化都会触发控制器重新检测pod的期望值以及集群内部符合条件的实际pod数量,并且作出相应的增删操作
- 当需要增加或者删除pod的数量的时候,调度器也不会去创建pod而是通过向API服务器提供pod清单之后API服务器创建pod的流程(鉴权,认证,准入,存储,调度等)
- RC/RS/DaemonSet/Job/statefulset的控制器
-
- Deployment的控制器
- deployment控制器负责使deployment的状态与API对象同步
- 每次Deployment对象修改时,deployment都会创建一个RS并且滚动升级至新的版本
- 同时收缩旧的版本,生成新的版本,并不会直接创建pod
- Node控制器
- node控制器第一个作用是来描述 集群节点信息
- 使节点对象于集群中的实际运行的节点保持同步,并且同时监控各个节点的监控状态,删除不可达节点
- 但是能够对node节点做更改的不止node控制器一个,kubelet可以,用户发起的RESTAPI调用同样可以
- service控制器
- 这个控制器的作用就是在当创建或者删除一个负载均衡器或者新建的时候,将基础服务里面的负载均衡器用于服务,或者删除服务的时候将资源里面的负载均衡器归还基础资源
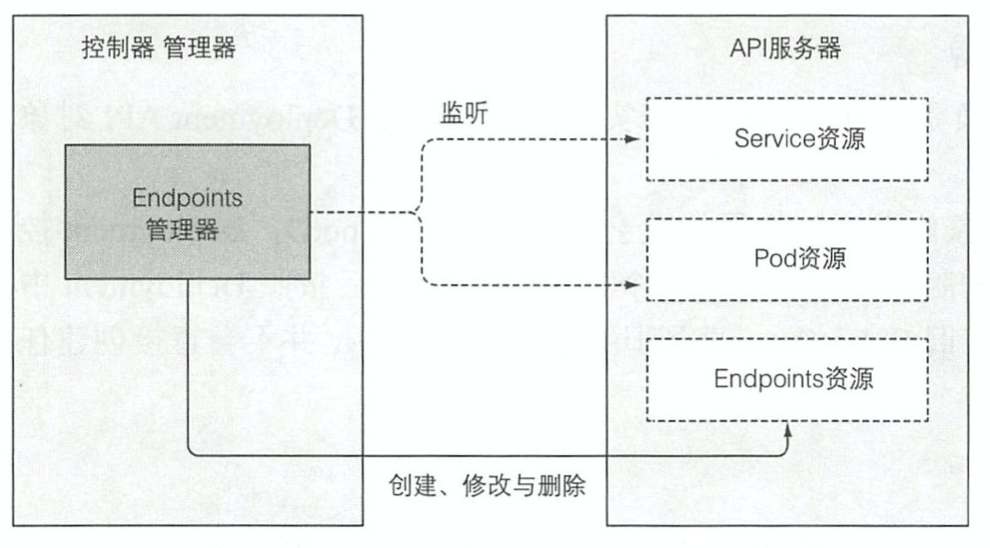
- Endpoint控制器
- 这个控制器是用作管控服务的的后端列表,当修改service定义(修改与之关联的endpoints)或者修改与之关联pod的时候,该控制器会监听这类事件的订阅,当收到通知之后则会对维护的列表作出相应的修改
![]()
- PersistentVolume控制器
- 之前学习了持久卷以及持久卷声明,当创建了持久卷声明之后,集群就会有某种神秘的力量将其与相适应的持久卷相绑定,这种神秘的力量就是pv控制器,
- 当客户端在创建一个持久卷的时候,PV控制器会维护一个当前系统里面已有的PV列表,找出最佳的卷并与之绑定
- 在删除卷的时候,会根据mainifest里面的回收策略,对PV进行相关的回收或者删除操作
- Deployment的控制器
小提示:以上这些说明所有控制器都不会去直接创建和修改资源都会通过API服务器继而kubelet去创建和修改集群的pod相关的资源
2.4 kubelet的作用
-
- kubelet的第一个作用就是在其所在的节点上注册到API服务器中
- 第二个作用就是通过监听API服务器的订阅,发现有pod被调度到这个节点上的时候,将去拉取镜像启动容器,并且持续监控容器状态,向API服务器报告其运行状态,事件和资源消耗
- kubelet也是运行存活探针的地方,当存活探针运行失败的时候,会去重新启动容器
- 当pod在API服务器被删除的时候,kubectl终止容器,并汇报给API服务器
2.5 kube-proxy的作用
-
- kube-proxy的作用是将客户端的请求转发到相关的后端pod中
- 同时也被称作为代理模式,其工作原理如下所示
![]()

2.6 DNS服务器是如何工作
-
- 集群中所有的pod默认配置使用集群的DNS,这使得内部服务的应用通过名称来查询服务
- DNS服务通过kube-dns服务对外暴露,服务的IP地址会写入每个容器中的/etc/resolv.conf文件中的namerserver中
- 之后通过监听API服务器的service以及endpoints的订阅
- 某种层面来说,从endpoint更新到到DNSpod收到通知的这个极短时间内,DNS可能无法工作
2.7 Ingress控制器如何工作
-
- Ingress原理是在集群中运行一个反向代理服务器
- 然后集群中的Ingress,service以及endpoint资源来配置该服务器
- 因而需要订阅这些资源(通过监听机制)然后每次其中一个发生变化则更新代理服务器配置

 浙公网安备 33010602011771号
浙公网安备 33010602011771号