
kubernets之Deployment资源
一 声明式的升级应用
1.1 回顾一下kubernets集群里面部署一个应用的形态应该是什么样子的,通过一副简单的图来描述一下
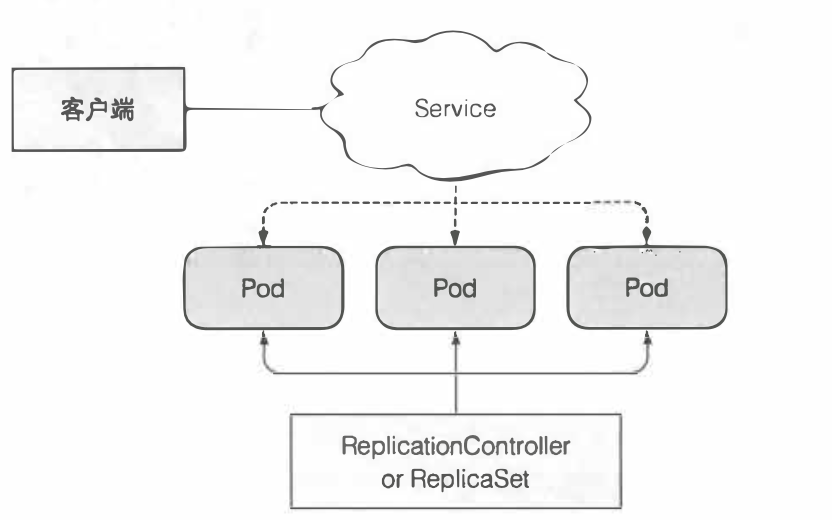
- 通过RC或者RS里面的模板创建了三个pod,之后通过一个servcie跟它进行关联
- 用户通过service访问pod里面应用
- RC或者RS来维护保障集群里面的pod数量始终恒定
二 如何对pod里面应用进行升级
2.1 升级RS/RC里面管控的的pod里面服务,我们无法通过修改某个文件或者代码的形式来替换pod应用的内容,只能通过删除之前的pod,之后重新创建新版本的pod,之后新的版本pod对客户端提供服务,这里有2种方式可以完成这个老版本到新的版本的切换
- 直接删除所有旧的pod,之后创建新的pod
- 也可以创建新的pod,并等待它们全部运行成功,之后再一次性删除所有的旧的pod
- 还可以一边创建新的pod,一边删除旧的pod
2.2 上面提到的办法各有优缺点
- 直接删除所有旧的pod,之后创建新的pod,这种比较简单粗暴,但是会导致服务的短时间的不可用
- 先创建所有新的pod,等待成功之后,在一次全部删除,这样会浪费更多的资源,并且要求,服务能够同时兼容新旧版本
- 一边创建新的pod,一边删除旧的pod,这种方式既不浪费资源并且也不会中断服务,唯一要求就是需要服务能够同时兼容新旧版本,但是对操作要求比较高,也是我们需要深度研究的一种升级版本的方式
三 重点探究第三种实现自动滚动式的升级的方法
3.1 创建第一个版本的RC以及service,创建的mainifest如下图所示
[root@node01 Chapter09]# cat kubia-rc-and-service.yml apiVersion: v1 kind: ReplicationController metadata: name: kubia-v1 spec: replicas: 3 template: metadata: name: kubia labels: app: kubia spec: containers: - image: luksa/kubia:v1 name: nodejs --- apiVersion: v1 kind: Service metadata: name: kubia spec: type: LoadBalancer selector: app: kubia ports: - port: 80 targetPort: 8080
- 在这个mainifest里面创建了2个资源,一个RC以及SVC,SVC的selector是RC的标签
- 若想在一个mainifest里面创建多个资源,需要使用---进行隔离
3.2 观察在没有Deployment之前的如何手动的滚动升级
k rolling-update kubia-v1 kubia-v2 --image=luksa/kubia:v2
- 通过复制之前的RC,并将里面的镜像版本由v1改为v2,但是第二个RC的起始的pod数量为0
- 观察之前的RC和pod的标签选择器不光只有之前的app=kubia还多了个deployment的标签,并且新的RC里面也是有个app=kubia和deployment的标签,之后对旧的RC管控的pod不断所容,就是不断降低pod数量,并且同时将新的RC的pod不断的进行扩容,两者始终保持一个动态平衡,这个平衡是旧的pod数量和新的pod数量之和总是等于3。
- 同时服务的标签的选择器还是app=kubia,慢慢的之前全部由旧版的pod提供服务转向由新的pod提供服务,最后全部都由新的pod对外提供服务,它们之间的关系图如下所示
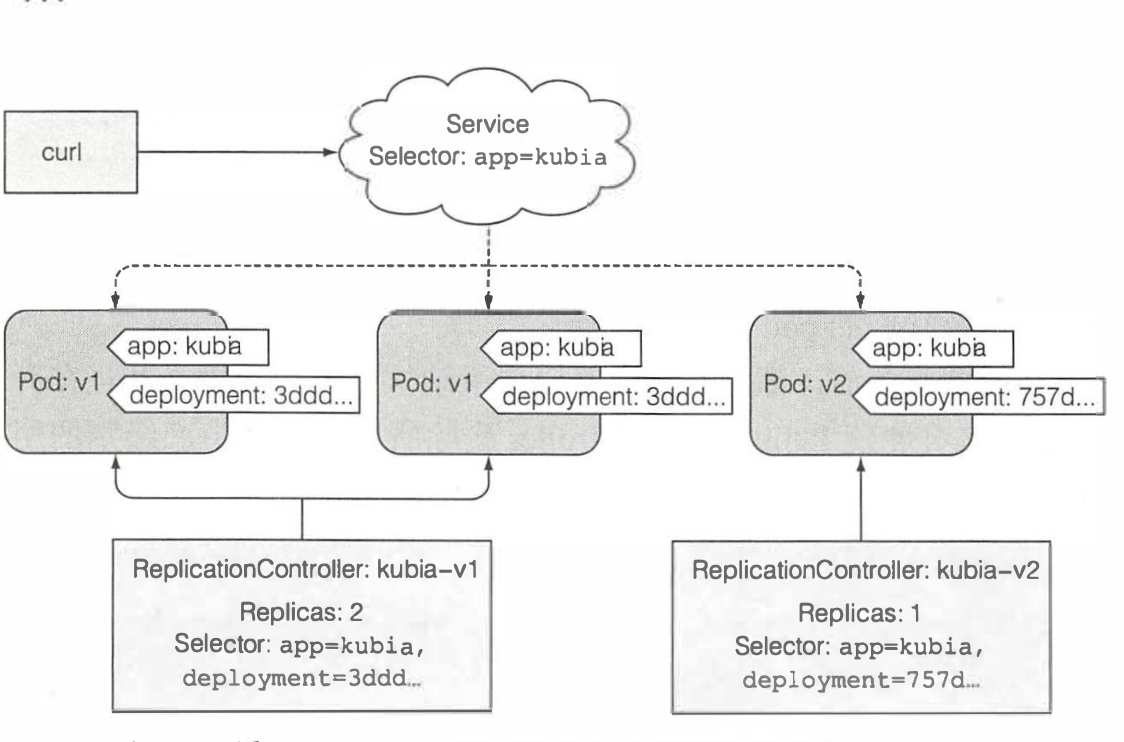
3.3 这种做法现在已经过时了,并且新版的kubernets都不支持这个命令了,原因有如下几点所示
- 首先我们这么操作的话,需要修改已经创建资源的标签,这有可能会带来一些意想不到的问题
- 我们所有的操作,都有客户端发起,这在客户端和API服务器网络联通不顺畅的时候将会直接导致升级失败(理想的情况下所有的操作都是由服务端发起,并且在服务端进行,尽可能杜绝由于网络不顺畅的情况造成的生产环境的升级问题造成客户保障)
- 这里介绍一种新的命令,用来显示在创建资源时候服务器的所有的响应的信息 --v
四 基于以上的手动式的不完美的场景,kubernets的程序员们摸了摸头上仅剩的几根头发,又开发出了一种新的资源Deployment,我们来看看Deployment是如何解决之前提到的问题
4.1 介绍deployment
kubernets是一种更高层的应用(凌驾于RC/RS等这种资源)支持应用声明式的升级,为何说deployment是一种更高阶的资源呢?我们在创建一个Deployment的时候,Rs,pod等等这些低级资源也随之创建,需要申明的一点是这个方式创建出来的pod还有由RS来管控的,deployment不会去管控pod的, 区别于上面的手动滚动式升级,需要创建2个RC来协同的进行滚动升级,Deployment只需要一个资源就可以完成以上的操作。
4.2 创建一个Deployment
它的mainifest文件如下所示
apiVersion: apps/v1beta1 kind: Deployment metadata: name: kubia spec: replicas: 3 template: metadata: name: kubia labels: app: kubia spec: containers: - image: luksa/kubia:v1 name: nodejs
- Deployment属于apps API组,版本为v1beat1
- 需要将原有kind从RC变为Deployment
- Deployment不再需要包含版本号
4.3 我们在创建deployment的时候,注意添加一个--record符号,这样可以方便之后deployment的版本升级以及回滚和查看历史版本,另外还有一个查看部署状态的命令
k create -f kubia-deployment-v1.yml --record
k rollout status deployment kubia
4.4 我们来看一下由deployment生成的pod具有一些什么样子的特征
[root@node01 Chapter09]# k get po NAME READY STATUS RESTARTS AGE kubia-5dfcbbfcff-7n7tr 1/1 Running 0 69s kubia-5dfcbbfcff-mjl7g 1/1 Running 0 69s kubia-5dfcbbfcff-vpp7t 1/1 Running 0 69s
4.5 再看一下由deployment生成的RS具有一些什么样的特征
[root@node01 Chapter09]# k get rs NAME DESIRED CURRENT READY AGE kubia-5dfcbbfcff 3 3 3 7m48s
- 可以看到由deployment生成的低等资源,都会有一串哈希数字(这个哈希值的来源是来自RS的模板),这同时也是deployment管理下层资源的一种方式,deployment每个版本都会创建一个RS,而每个RS所关联的pod资源都具有相同的哈希值
五 升级一个Deployment(上)
5.1 从前面来看,创建一个deployment也并没有比创建RC省多少事,但是从升级的角度来看,就会发现deployment的优势所在了,下面就来对其进行介绍
- deployment升级步骤很简单,仅仅需要修改Deployment中定义的模板
5.2 实际上deployment有2种升级策略
- 第一种为Recreate:这种升级策略是将之前所有的pod都全部删除,之后重新创建pod,这种模式下,主要是应对2个版本的服务不兼容的情况下,其次,应用还需要能够中断
- 第二种策略,也是deployment默认的策略那就是RollingUpdate,这种策略就是滚动升级策略,逐渐的将旧版本的pod删除,同时逐渐的拉起新的版本,这种策略,要求,服务能够同时兼容新版本和旧版本
- 另外一点需要注意的是可以通过添加minReadySecond参数从而降低滚动升级的速度
- k patch deployment kubia -p '{"spec":{"minReadySecond":10}}'
- k patch 对修改少量的资源信息特别有用,不需要使用k edit或者k apply等等
5.3 开始演示滚动升级
[root@node01 Chapter09]# k set image deployment kubia nodejs=luksa/kubia:v2 deployment.extensions/kubia image updated
5.4 观察deployment下面的资源是否符合预期
[root@node01 Chapter09]# k get po NAME READY STATUS RESTARTS AGE kubia-5dfcbbfcff-7n7tr 1/1 Terminating 0 32m kubia-5dfcbbfcff-mjl7g 1/1 Running 0 32m kubia-5dfcbbfcff-vpp7t 1/1 Terminating 0 32m kubia-7c699f58dd-6s8mn 0/1 ContainerCreating 0 1s kubia-7c699f58dd-7lhcp 1/1 Running 0 36s kubia-7c699f58dd-8cp4q 1/1 Running 0 18s [root@node01 Chapter09]# k get po NAME READY STATUS RESTARTS AGE kubia-5dfcbbfcff-7n7tr 1/1 Terminating 0 32m kubia-5dfcbbfcff-mjl7g 1/1 Terminating 0 32m kubia-5dfcbbfcff-vpp7t 1/1 Terminating 0 32m kubia-7c699f58dd-6s8mn 1/1 Running 0 13s kubia-7c699f58dd-7lhcp 1/1 Running 0 48s kubia-7c699f58dd-8cp4q 1/1 Running 0 30s
- 可以看到v1的版本逐渐减少,v2的版本逐渐增加
- 修改之后,deployment的镜像成功的修改成了v2
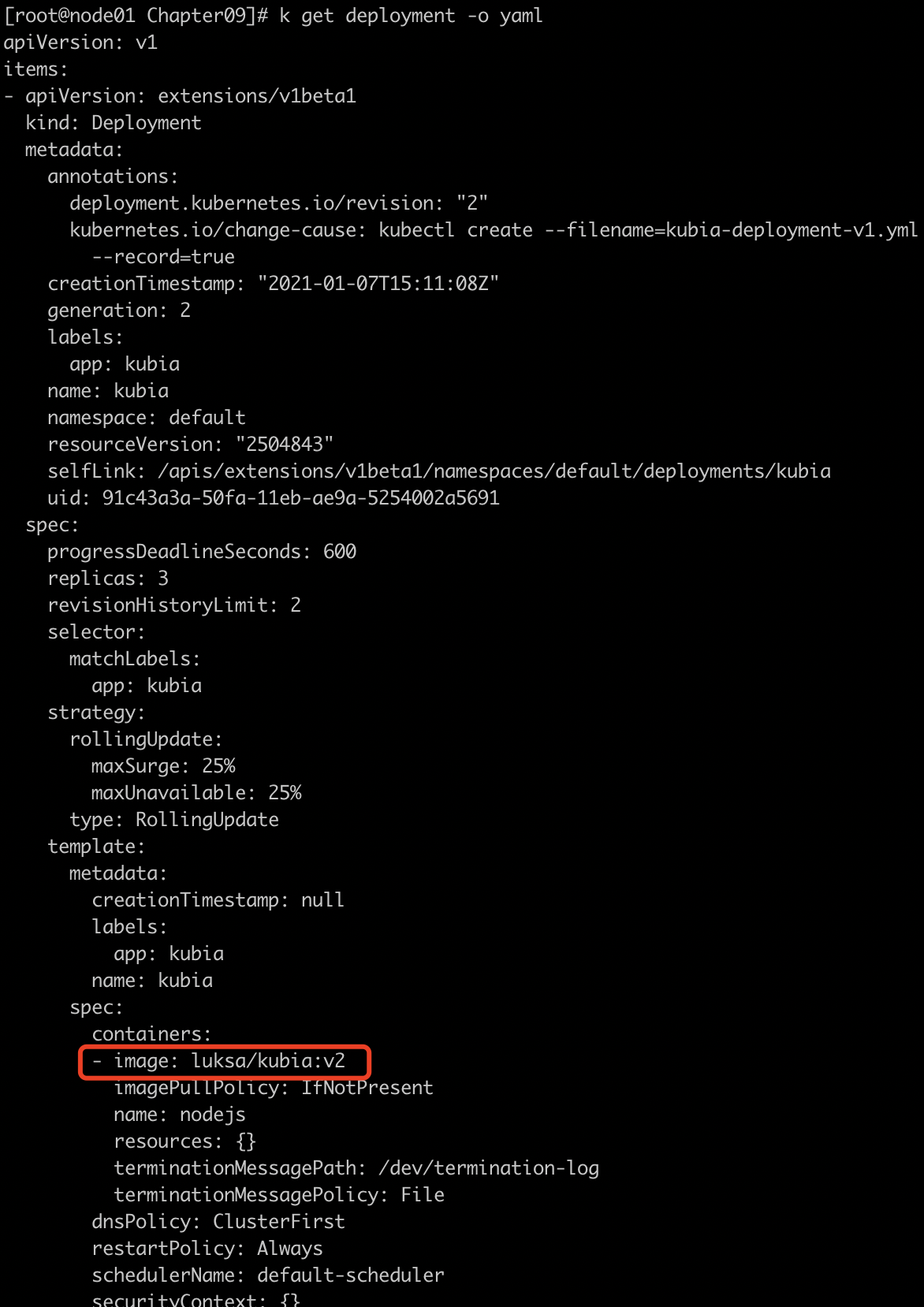
- 列举下常见的几种修改资源的不同方式
- k edid: 使用默认编辑器打开资源配置。修改保存并退出编辑器,资源对象会被更新
- k patch: 修改单个属性,需要准备描述修改属性的完整路径
- k apply: 通过一个完整的YAML或者jSON文件,应用其中新的值来修改,如果资源对象不存在则创建,YAML文件需要是某个资源的完整定义
- k replace: 通过一个完整的YAML或者jSON文件,应用其中新的值来修改,如果资源对象不存在则会报错,YAML文件需要是某个资源的完整定义
- k set image修改pod/RC/RS/DaemonSet/Job/Deployment里面的镜像,例如一个范例:k set image deployment kubia nodejs=luksa/kubia:2
- 对比之前提到的手动滚动式升级,deployment实现的滚动升级仅仅只需要修改deployment资源的一个字段
- 另外一个好处就是整个的升级流程都是在主节点的控制器上面,客户端没有任何参与,这样就避免了升级过程中可能遇到的网络不通导致的问题
- 还有一点,如果deployment引用的configmap进行了更改,是不会引起deployment的升级的,如果真的需要修改deployment升级的话,就需要重新创建一个configmap/secrets然后让deployment里面的pod去引用新的configmap或者secrets
- 我们发现集群里面还保留了之前的RS,这个要归功于之前创建deployment时候加的参数--record,并且有了它对deployment的版本回退成了可能
六 升级一个Deployment(下)
前言:上篇介绍了deployment的一些基础升级的方式以及技巧,下篇我们来看看deployment还支持哪些更牛逼的功能
6.1 取消本次升级
我们在之前的基础上,添加另一个版本v3,这个版本里面引入了一个bug,你在升级过程中就已经发现,但是已经开始升级了,你需要快速取消本次升级
k rollout undo deployment kubia
6.2 显示deployment滚动升级的历史
我们来看一下deployment的升级历史
[root@node01 Chapter09]# k rollout history deployment kubia deployment.extensions/kubia REVISION CHANGE-CAUSE 1 kubectl create --filename=kubia-deployment-v1.yml --record=true 5 kubectl create --filename=kubia-deployment-v1.yml --record=true 6 kubectl create --filename=kubia-deployment-v1.yml --record=true
6.3 回滚到指定的某个版本
[root@node01 Chapter09]# k rollout undo deployment kubia --to-revision=6 deployment.extensions/kubia rolled back
6.4 控制滚动升级速率
deployment可以通过2个参数来限制升级速率,具体如下所示
spec: strategy: rollingUpdate: maxSurge: 1 maxUnavailable: 0 type: RollingUpdate
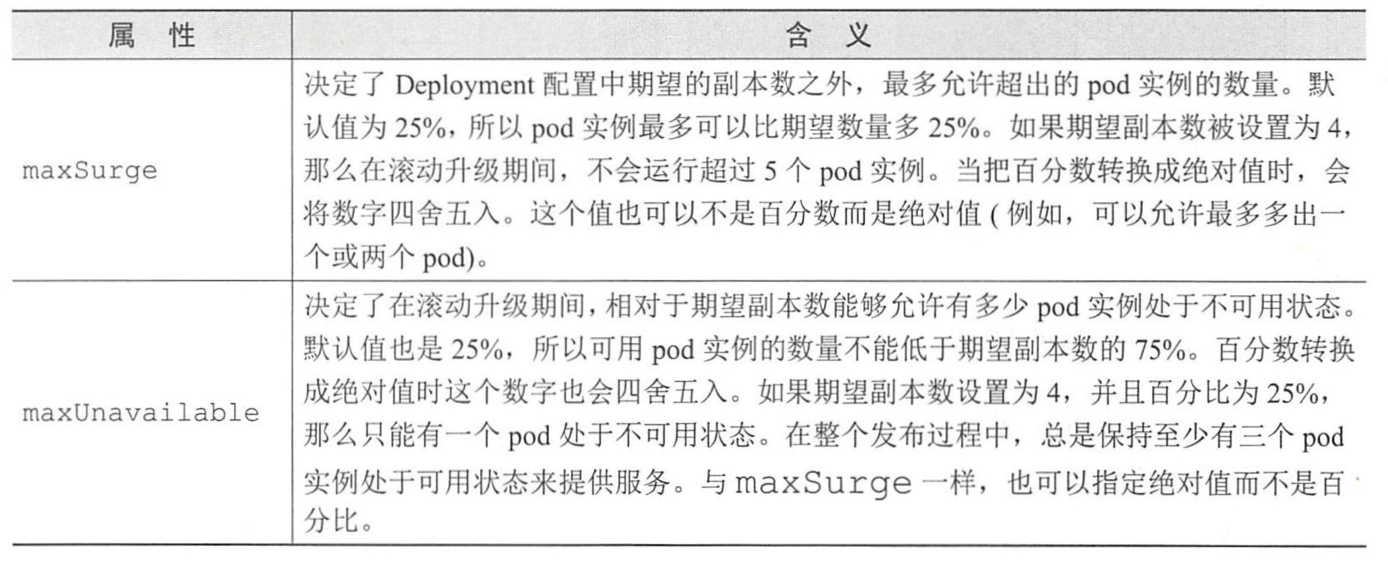
- maxSurge:表示升级过程中多于配置中期望的数量
- maxUnavailable:表示升级过程中期望数量中不可用数量或者比例(四舍五入)
6.5 滚动升级的速率属性
6.6 除了以上参数之外还可以临时暂停滚动升级
步骤为首先进行滚动升级之后马上暂停滚动升级,这样就能至少保障有一个pod被替换,可以用这个金丝雀版本来让一小部分用户来体验是否升级成功,具体操作流程如下所示
-
- 先开始进行升级:k set image deployment kubia nodejs=luksa/kubia:v4
- 之后马上第一时间进行暂停:k rollout pause deployment kubia
- 验证完成之后继续滚动升级:k rollout resume deployment kubia
6.7 阻止出错版本的滚动升级
minReadySecond这个参数作用是单个pod在成功持续多久之后才将pod视为可用,再这之前deployment的滚动升级将不会继续进行,让我们来加上就绪探针综合的看一下,新加入一个pod的时候如果就绪探针在minReadySecond的时间内出现失败则标记失败并且会阻止滚动升级,这时候需要采取版本回退等措施,下面展示一下一个包含minReadySecond和就绪探针的mainifest的实例,我们来用之前实验的v3版本,并且试一下刚学会的apply命令来更新已经存在的资源
[root@node01 Chapter09]# cat kubia-deployment-v3-with-readinesscheck.yml apiVersion: apps/v1beta1 kind: Deployment metadata: name: kubia spec: #replicas: 3 minReadySeconds: 10 strategy: rollingUpdate: maxSurge: 1 maxUnavailable: 0 template: metadata: name: kubia labels: app: kubia spec: containers: - image: luksa/kubia:v3 name: nodejs readinessProbe: periodSeconds: 1 httpGet: path: / port: 8080
- depyoyment使用的api组是apps/v1beta1
- 第二个使用k apply -f new_deployment_config.yml来更新集群内部之前已经有的资源
- 对于spec.replicas这个属性,如果修改的话,就会对现有资源进行缩/扩容,如果不改动则可以不用添加
- maxUnavailable这个属性限制了deployment里面的pod不能少于预期不可使用pod
- 对于加入pod容器里面的就绪探针,每一秒会对容器进行http的探测
6.8观察升级的结果
集群中升级的结果如下所示
[root@node01 Chapter09]# k get po NAME READY STATUS RESTARTS AGE kubia-6976f5b8f8-66qft 1/1 Running 0 3h8m kubia-6976f5b8f8-qhzss 1/1 Running 0 3h8m kubia-6976f5b8f8-wpjfp 1/1 Running 0 3h8m kubia-84b59979b9-9hzmh 0/1 Running 0 4m12s [root@node01 Chapter09]# k get rs NAME DESIRED CURRENT READY AGE kubia-5c98f77977 0 0 0 3h50m kubia-6976f5b8f8 3 3 3 3h9m kubia-7c699f58dd 0 0 0 15h kubia-84b59979b9 1 1 0 4m22s
- 集群里面的server端全部仍然还是之前的版本提供服务
- 创建了一个新的pod版本,但是状态一只不是ready
- 同时创建了一个该版本的rc
6.8 对出现该现象进行解释
- 为啥服务一个都没切换到新版本,并且滚动升级过程好像也已经暂停了,这是由于我们在资源里面添加了就绪探针,升级策略参数maxUnavailable:0属性以及minReadySecond:10,并且这个是符合预期的
- 我们的v3版本里面在进行第五次访问的时候就会抱一个错误异常返回给客户端,我们的就绪探针设置的每一秒发起一次http探测,从开始探测到发现异常这小于5s时间内,就绪探针就会发现异常并报告给API服务器,而我们升级策略里面minReadySecond:10,要求10spod能够正常服务,但是5s的时候就已经不正常了,service就会将它维护的endpoints里面的清单就该pod的ip移除,由于我们设置的maxUnavailable:0设置了,我们的deployment里面可用的pod不得低于预设值,反过来讲就是不允许存在不可用的pod,那旧的pod就不会被删除,新的pod也不会继续创建,升级流程就停留在了这个姿态
- 综上所示,有限的设置这些参数是很有必要的,需要各位小主针对不同的业务场景仔细斟酌
6.9 介绍最后一个参数
如果在配置里面添加了progressDeadlineSecond:600,则整个升级流程如果大于10分钟会自动取消

 浙公网安备 33010602011771号
浙公网安备 33010602011771号