flask:cbv源码分析、模板语法、请求与响应、session及源码分析、闪现(flash)、请求扩展
一、cbv源码分析
1.1 基于类的视图写法
from flask import Flask,request
from flask.views import View, MethodView
app = Flask(__name__)
app.debug = True
# 视图类,继承MethodView,类中写跟请求方式同名的方法即可,之前学的所有都一致
class IndexView(MethodView):
def get(self):
print(request.method)
return 'get 请求'
def post(self):
print(request.method)
return 'post 请求'
app.add_url_rule('/index', endpoint='index', view_func=IndexView.as_view('index'))
if __name__ == '__main__':
app.run()
ps1:在编写视图方法或视图类的时候需要注意,当我们不写endpoint(不编写别名),会自动把当前视图的名称当成别名。如果很多视图方法名称一样,就会出现冲突。
ps2:视图类在编写的时候必须要有别名
1.2 源码分析
flask的cbv源码分析也是从路由开始分析的
1、分析路由中的注册代码
IndexView.as_view('index') 执行完的结果,是个函数(view的)内存地址
2、分析as_view源码
def as_view(cls, name, *class_args, **class_kwargs):
def view(**kwargs: t.Any) -> ft.ResponseReturnValue:
# current_app.ensure_sync 本质是在执行self.dispatch_request,只是用了异步
return current_app.ensure_sync(self.dispatch_request)(**kwargs)
return view
通过分析as_view的主要源码,我们可以得知他的作用也是类似django中的as_view,返回一个view函数,而view函数中,执行了self.dispatch_request,所以接下去的关键就是去读dispatch_request的源码
3、dispatch_request的源码
在view函数中的self就是我们的视图类创建的对象,而我们的视图类是继承了MethodView,所以dispatch_request也要去MethodView中查找(直接ctrl点击查找,会找到View中的dispatch_request函数)
def dispatch_request(self, **kwargs):
# self是视图类的对象
meth = getattr(self, request.method.lower(), None)
# 用异步执行meth()
return current_app.ensure_sync(meth)(**kwargs)
他的作用类似django中的dispatch方法,通过反射执行对应的函数,然后这里也是用异步的方式返回反射得到的方法执行的结果
4、总结
执行原理跟django一样,实现的方式有点区别
1.3 分析源码,查找不传别名的时候为什么函数名会变成别名
上面我们提到过,不传别名,视图函数的别名就是函数名,我们通过源码来寻找原因
而视图类是必须传别名给as_view当参数的
补充知识
函数的双下name,就是函数的名称(不是函数名),
def add():
pass
add.__name__='lqz'
print(add.__name__)
视图函数的路由源码分析
视图函数的注册通常使用装饰器来注册,如果我们传入endpoint就是设置了别名,之前分析路由源码的时候,我们得知路由装饰器,添加路由的方法就是app.add_url_rule方法,在add_url_rule方法的参数中我们也可以找到endpoint。
-@app.route('/index')--》没有传endpoint
-endpoint 就是None---》调用了app.add_url_rule,传入了None
if endpoint is None:
endpoint = _endpoint_from_view_func(view_func) # type: ignore
在add_url_rule方法中我们可以看到他先判断了有没有endpoint参数,如果没传就调用了_endpoint_from_view_func方法去设置别名,因此:
-_endpoint_from_view_func 就是返回函数的名字
这里我们可以看一下他的源码,关键的部分就是我们前面提到的双下name属性,他就是函数名称
def _endpoint_from_view_func(view_func: t.Callable) -> str:
assert view_func is not None, "expected view func if endpoint is not provided."
return view_func.__name__
视图类的路由源码分析
as_view('index') 必须传参数,传进来的参数是,是【别名】
# view是as_view内的内层函数,闭包函数
view.__name__ = name # 修改了函数的名字变成了你传入的
as_view方法返回了view函数,然后把我们传入的别名绑定给了view函数的双下name
# app.add_url_rule('/index',view_func=IndexView.as_view('index'))
可以简写成:app.add_url_rule('/index',view_func=view)
因为as_view执行的结果就是view函数,所以我们其实是可以这样简写的
但是如果不传参数,所有类的别名(endpoint),都是内层函数view,所以就报错了,所以视图类必须要在as_view中加参数,传入别名
视图类的路由也是可以有endpoint的,但是不能没有as_view中的参数
1.4 flask的路由注册使用装饰器,如果写了一个登录认证装饰器,那么应该放在路由装饰器上还是下?
结论:
-放在路由下面
-路由必须传endpoint,如果不传,又报错
ps:如果用了装饰器,就必须指定entpoint的别名
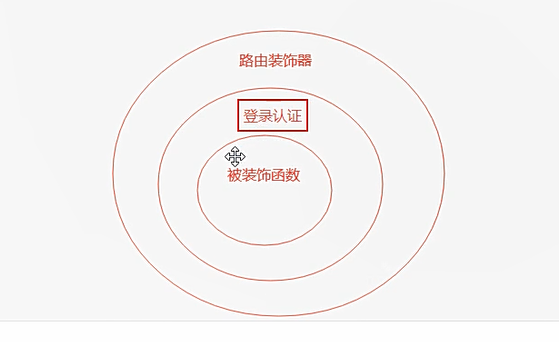
分析:
1、首先我们要回顾多层语法糖的执行过程:语法糖是从下往上加载,从上往下执行的
2、根据逻辑需求,我们可以得知我们要先进入路由装饰器注册路由,然后再进行登陆认证,最后执行被装饰器装饰器的函数
3、因此得出校验登陆的装饰器需要放在路由注册的装饰器下方
拓展
给视图类加装饰器,可以直接配置在类属性【decorators】即可
class IndexView(MethodView):
decorators = [auth,]
'这个auth就是装饰器'
def get(self):
print(request.method)
return 'get 请求'
def post(self):
print(request.method)
return 'post 请求'
这个decorators属性我们可以在as_view的源码中找到
他会把decorators对应的列表中的装饰器执行
# 源码,cls是视图类,中有decorators
if cls.decorators:
view.__name__ = name
view.__module__ = cls.__module__
for decorator in cls.decorators:
view = decorator(view) # view=auth(view)
1.5 dispatch_request讲解
视图类必须继承MethodView,如果继承View,它的dispatch_request没有具体实现,你的视图类必须重写dispatch_request,我们不想重写,继承MethodView
def dispatch_request(self) -> ft.ResponseReturnValue:
raise NotImplementedError()
1.6 知识点总结
- 1 as_view 执行流程跟djagno一样
- 2 路径如果不传别名,别名就是函数名(endpoint)
- 3 视图函数加多个装饰器(上下顺序和必须传endpoint)
- 4 视图类必须继承MethodView,否则需要重写dispatch_request
- 5 视图类加装饰器:类属性decorators = [auth,]
二、模板语法
2.1 py
from flask import Flask, render_template,Markup
app = Flask(__name__, template_folder='templates', static_folder='static') # 模板的路径必须是templates,因为实例化app对象时,传入的
app.debug=True
def add(a,b):
return a+b
@app.route('/')
def index():
a='<a href="http://www.baidu.com">点我看美女</a>' # 不存在xss攻击,处理了xss
a=Markup(a)
return render_template('index.html',name='lqz',a=a,add=add)
if __name__ == '__main__':
app.run()
2.2 html
<!DOCTYPE html>
<html lang="en">
<head>
<meta charset="UTF-8">
<title>Title</title>
</head>
<body>
<h1>模板语法,static</h1>
<img src="/static/1.jpg" alt="">
'通过静态文件接口,放图片'
<h1>模板语法,if</h1>
{% if name %}
<h1>Hello {{ name }}!</h1>
{% else %}
<h1>Hello World!</h1>
{% endif %}
<h1>模板语法,标签渲染</h1>
{{a|safe}}
{{a}}
'默认情况下不允许渲染html代码,会出现xss攻击,需要在后面跟上 |safe '
'如果我们用Markup处理对应的html代码,就可以让他不需要写上 |safe参数 '
<h1>模板语法,执行函数</h1>
{{add(4,5)}}
</body>
</html>
ps:上一天的博客中还有for循环的模版语法,并且flask的模版语法还能执行方法(加括号),字典可以.get .values() .items()
三、请求与响应
请求:全局的request对象
响应:四件套
请求
| 请求名称 | 作用 |
|---|---|
| request.method | 提交的方法 |
| request.args | get请求提及的数据(路由中携带的也在这里) |
| request.form | post请求提交的数据 |
| request.values | post和get提交的数据总和 |
| request.cookies | 客户端所带的cookie |
| request.headers | 请求头 |
| request.path | 不带域名,请求路径 |
| request.full_path | 不带域名,带参数的请求路径 |
| request.script_root | 请求的完整 URL,包括查询字符串 |
| request.url | 带域名带参数的请求路径 |
| request.base_url | 带域名请求路径 |
| request.url_root | 域名(请求的完整 URL,包括查询字符串) |
| request.host_url | 域名(完整的应用程序URL,包括协议和端口) |
| request.host | 127.0.0.1:500 |
| request.files | 文件的数据 |
响应
我们之前学习了四件套,也就是四种返回数据的方式
# return "字符串"
# return render_template('html模板路径',**{})
# return redirect('/index.html')
# return jsonify({'k1':'v1'})# return "字符串" # return render_template('html模板路径',**{}) # return redirect('/index.html') # return jsonify({'k1':'v1'})
从本质上来说,其实就是这些方法封装把数据封装到了response对象中去,然后把response对象返回了出去
而我们很多情况下会出现下列需求:
- 1、响应中写入cookie
- 2、响应头中写数据(如果用了新手四件套,都要用make_response包一下)
代码
from flask import Flask, request, make_response,render_template
app = Flask(__name__)
app.debug = True
@app.route('/', methods=['GET', 'POST'])
def index():
print(request.method)
print(request.args)
print(request.form)
print(request.values)
print(request.cookies)
print(request.headers)
print(request.path)
print(request.full_path)
print(request.url)
print(request.base_url)
print(request.host_url)
print(request.host)
obj = request.files['file']
obj.save(obj.filename)
### 响应 四件套
# 1 响应中写入cookie
# response = 'hello'
# res = make_response(response) # flask.wrappers.Response
'这里用了make_response生成了response对象,跟之前没什么区别,如果我们返回的是字符串,flask会帮我们执行这个make_response方法'
# print(type(res))
# res.set_cookie('xx','xx')
'这里我们用到的set_cookie往响应的数据中设置cookie'
# return res
# 2 响应头中写数据(新手四件套,都要用make_response包一下)
response = render_template('index.html')
res = make_response(response) # flask.wrappers.Response
print(type(res))
res.headers['yy']='yy'
'这样就是往响应头中添加数据(键值对)'
return res
if __name__ == '__main__':
app.run()
四、session及源码分析
4.1 session的使用
实现的功能:用户去登陆,登陆成功后,访问index页面可以在该页面展示出登陆用户的名称,如果没登陆就让页面展示匿名用户
python代码
from flask import Flask, request, session, render_template, redirect
app = Flask(__name__)
app.debug = True
app.secret_key = 'asdfas33asdfasf'
@app.route('/login', methods=['GET', 'POST'])
def login():
if request.method == 'GET':
return render_template('login.html')
else:
name = request.form.get('name')
password = request.form.get('password')
print(password)
session['name'] = name
return redirect('/index')
@app.route('/index', methods=['GET', 'POST'])
def index():
return 'hello %s' % session.get('name', '匿名用户')
if __name__ == '__main__':
app.run()
login.html
<!DOCTYPE html>
<html lang="en">
<head>
<meta charset="UTF-8">
<title>Title</title>
</head>
<body>
<form method="post">
<p>用户名:<input type="text" name="name"></p>
<p>密码:<input type="password" name="password"></p>
<p><input type="submit" value="提交"></p>
</form>
</body>
</html>
4.2 session执行原理
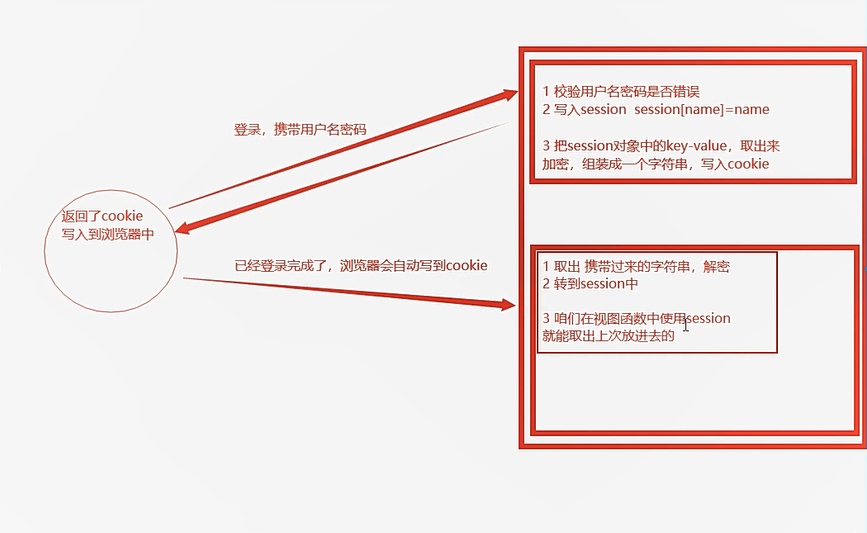
4.3 源码分析
我们在实现上面的需求的时候,会发现两个不同的视图方法,共用了session的数据,我们通过分析session的源码来探索原因
cookie :存在于客户端浏览器的键值对
session:存在于服务端的键值对 # djagno 放在了django_session表中
token:存放在客户端,通过算法来校验
flask中,叫session,问题来了,存哪里了?
-加密后(需要设置secret_key),放到了cookie中,如果session发生了变化,我们的cookie也会跟着变
在django中,改变了cookie,session表中的信息变了,但是前端的cookie不一定变
源码部分分析
1、首先我们要引出一个属性:app.session_interface
他配置了一个类的对象,这个就是session的执行流程
2、我们查看session_interface的源码
session_interface: SessionInterface = SecureCookieSessionInterface()
3、接着我们去看SecureCookieSessionInterface的源码
首先我们会发现他是一个类,但是他不是重点,重点是他内部的open_session、save_session两个方法
请求来了,会执行open_session
请求走了,会执行save_session
open_session源码分析
def open_session(self, app, request) :
#1 根据名字,取出前端传入的cookie的value值
val = request.cookies.get(self.get_cookie_name(app))
#2 如果没有val,构造了一个空session对象
if not val:
return self.session_class()
max_age = int(app.permanent_session_lifetime.total_seconds())
'这里是获取过期时间'
try:
# 如果没有过期,解码,做成session对象,后续直接用session即可
data = s.loads(val, max_age=max_age)
'这里对cookie中的数据进行了解密'
return self.session_class(data)
except BadSignature:
# 如果过期了,也是空session
return self.session_class()
save_session源码分析
def save_session(self, app, session, response) :
name = self.get_cookie_name(app)
'这里跟上面一样,通过cookie中键值对的键,查找session的信息'
# 取出过期时间,并把session加密转成字符串,放到cookie中
expires = self.get_expiration_time(app, session)
val = self.get_signing_serializer(app).dumps(dict(session))
response.set_cookie(
name,
val,
expires=expires,
)
扩展
如果我们想把session放到redis中、mysql中,已经有人帮咱们写了,用第三方的模块即可
当然我们也可以重写一个类来实现这个功能(重写open_session,save_session自己写)
五、闪现(flash)
flash是翻译过来得到闪现这个名称的,他的效果简单描述如下:
- 当次请求先把一些数据,放在某个位置
- 下一次请求,把这些数据取出来,取完,就没了
作用:
1 可以跨请求,来保存数据
2 当次请求,访问出错,被重定向到其他地址,重定向到这个地址后,拿到当时的错误
djagno中有这个东西吗?
- message框架
flash用法
设置 闪现
-flash('%s,我错了'%name) ,可以设置多次,放到列表中
-flash('超时错误',category="debug") 分类存
获取 闪现
-get_flashed_messages() ,取完就删除
-get_flashed_messages(category_filter=['debug'])分类取
本质:放到session中(使用的时候可以查到的)
六、请求扩展
这里的请求扩展可以类比django的中间件
- 在请求来了,或请求走了,可以绑定一些函数,到这里就会执行这个函数,类似于django的中间件
- 在flask中就用请求扩展,来代替djagno的中间件
请求扩展方法
| 方法名称 | 触发条件及简介 |
|---|---|
| before_request | 请求来了会走,如果他返回了四件套,就结束了(类比django中间件中的process_request) |
| after_request | 请求走了会走,一定要返回response对象(类比django中间件中的process_response) |
| before_first_request | 第一次来请求的时候会走,跟浏览器无关 |
| teardown_request | 每一个请求之后绑定的一个函数,即使遇到了异常也会走他 |
| errorhandler | 监听状态码,404 500 |
| template_global | 标签 |
| template_filter | 过滤器 |
总结:
1、重点掌握before_request和after_request,
2、注意有多个的情况,执行顺序
3、before_request请求拦截后(也就是有return值),response所有都执行
操作代码
from flask import Flask, request,render_template
app = Flask(__name__)
####1 before_request 和 after_request
# 请求来了,执行一个函数,来的时候从上往下执行
# @app.before_request
# def before():
# print('我来了111')
# # if 'index' in request.path:
# return '不让看了' # 如果不是retrun了None,说明被拦截了,直接返回
#
#
# @app.before_request
# def before1():
# print('我来了222')
#
#
# # 请求走了,执行一个函数,走的时候,从下往上执行
# @app.after_request
# def after(response):
# print('我走了111')
# return response
#
#
# @app.after_request
# def after2(response):
# print('我走了222')
# return response
# 2 项目启动后的第一个请求
# @app.before_first_request
# def first():
# print('我的第一次')
# 3 teardown_request,无论视图函数是否出错,都会执行它,做错误日志
# @app.teardown_request
# def teardown(e):
# print(e)
# '这里的e就是报错信息'
# print('执行我了')
# 4 errorhandler 监听响应状态码,如果符合监听的状态码,就会走它
# @app.errorhandler(404)
# def error_404(arg):
# return "404错误了"
# @app.errorhandler(500)
# def error_500(arg):
# return "500错误了"
##5 template_global 在模板中直接使用该标签
@app.template_global()
def add(a1, a2):
return a1 + a2
# 6 template_filter 这个过滤器也是在模版中使用,但是使用方式有讲究
@app.template_filter()
def db(a1, a2, a3):
return a1 + a2 + a3
@app.route('/')
def index():
# a = [1, 2, 3]
# print(a[9])
return render_template('index1.html')
if __name__ == '__main__':
app.run()
index1.html
<!DOCTYPE html>
<html lang="en">
<head>
<meta charset="UTF-8">
<title>Title</title>
</head>
<body>
<h1>标签和过滤器</h1>
{{add(6,6)}}
<br>
{{8|db(2,3)}}
</body>
</html>
我们可以看到过滤器需要先写一个变量,然后再在db中添加两个变量
七、作业
1、脏读,不可重复读,幻读 ,mysql5.7以后默认隔离级别是什么?
什么是脏读,不可重复读,幻读?
1、脏读:一个事务读取了另一个事务未提交的数据,而这个数据是有可能回滚的。
2、不可重复读:一个事务内两个相同的查询却返回了不同数据。这是由于查询时系统中其他事务修改的提交而引起的。
3、幻读:一个事务对一个表中的数据进行了修改,这种修改涉及到表中的全部数据行。同时,另一个事务也修改这个表中的数据,这种修改是向表中插入一行新数据。那么,操作前一个事务的用户会发现表中还有没有修改的数据行,就好象发生了幻觉一样。
4、丢失更新:两个事务同时读取同一条记录,A先修改记录,B也修改记录(B不知道A修改过),B提交数据后B的修改结果覆盖了A的修改结果。
不同的事务级别处理的问题
1.read uncommitted(未提交读)
事务中的修改即使没有提交,对其他事务也都是可见的,事务可以读取未提交的数据,这一现象也称之为"脏读"
2.read committed(提交读)
大多数数据库系统默认的隔离级别
一个事务从开始直到提交之前所作的任何修改对其他事务都是不可见的,这种级别也叫做"不可重复读"
3.repeatable read(可重复读) # MySQL默认隔离级别
能够解决"脏读"问题,但是无法解决"幻读"
所谓幻读指的是当某个事务在读取某个范围内的记录时另外一个事务又在该范围内插入了新的记录,当之前的事务再次读取该范围的记录会产生幻行,InnoDB和XtraDB通过多版本并发控制(MVCC)及间隙锁策略解决该问题
4.serializable(可串行读)
强制事务串行执行,很少使用该级别
mysql5.7以后默认隔离级别是什么?
repeatable read(可重复读)
2、什么是qps,tps,并发量,pv,uv
Web网站性能指标:PV、UV、IP、QPS、TPS、并发量、RT等
PV:即 page view,页面浏览量。用户每一次对网站中的每个页面访问均被记录1次。用户对同一页面的多次刷新,访问量累计。
UV:即 Unique visitor,独立访客。通过客户端的cookies实现。即同一页面,客户端多次点击只计算一次,访问量不累计。
IP:即 Internet Protocol,本意本是指网络协议,在数据统计这块指通过ip的访问量。即同一页面,客户端使用同一个IP访问多次只计算一次,访问量不累计。
UV、IP的区别:
- 比如你是ADSL拨号上网,拨一次号自动分配一个IP,进入了网站,就算一个IP;断线了而没清理Cookies,又拨号一次自动分配一个IP,又进入了同一个网站,又统计到一个IP,这时统计数据里IP就显示统计了2次。但是UV没有变,是1次。
- 同一个局域网内2个人,在2台电脑上访问同一个网站,他们的公网IP是相同的。IP就是1,但UV是2。
QPS:即Queries Per Second的缩写,每秒能处理的查询数目(发出请求到服务器处理完成功返回结果)。是一台服务器每秒能够相应的查询次数,是对一个特定的查询服务器在规定时间内所处理流量多少的衡量标准。
TPS:即Transactions Per Second的缩写,每秒处理的事务数目。一个事务是指一个客户机向服务器发送请求然后服务器做出反应的过程。客户机在发送请求时开始计时,收到服务器响应后结束计时,以此来计算使用的时间和完成的事务个数,最终利用这些信息作出的评估分。
并发量:系统能同时处理的请求数。
RT:响应时间,处理一次请求所需要的平均处理时间。
计算关系:
QPS = 并发量 / 平均响应时间
并发量 = QPS * 平均响应时间
3、什么是接口幂等性问题,如何解决?
幂等性概念
幂等性原本是数学上的概念,用在接口上就可以理解为:同一个接口,多次发出同一个请求,必须保证操作只执行一次。
调用接口发生异常并且重复尝试时,总是会造成系统所无法承受的损失,所以必须阻止这种现象的发生。
比如下面这些情况,如果没有实现接口幂等性会有很严重的后果:
支付接口,重复支付会导致多次扣钱
订单接口,同一个订单可能会多次创建。
幂等性的解决方案
1、唯一索引
使用唯一索引可以避免脏数据的添加,当插入重复数据时数据库会抛异常,保证了数据的唯一性。
2、乐观锁
这里的乐观锁指的是用乐观锁的原理去实现,为数据字段增加一个version字段,当数据需要更新时,先去数据库里获取此时的version版本号
select version from tablename where xxx
更新数据时首先和版本号作对比,如果不相等说明已经有其他的请求去更新数据了,提示更新失败。
update tablename set count=count+1,version=version+1 where version=#{version}
3、悲观锁
乐观锁可以实现的往往用悲观锁也能实现,在获取数据时进行加锁,当同时有多个重复请求时其他请求都无法进行操作
4、分布式锁
幂等的本质是分布式锁的问题,分布式锁正常可以通过redis或zookeeper实现;在分布式环境下,锁定全局唯一资源,使请求串行化,实际表现为互斥锁,防止重复,解决幂等。
5、token机制
token机制的核心思想是为每一次操作生成一个唯一性的凭证,也就是token。一个token在操作的每一个阶段只有一次执行权,一旦执行成功则保存执行结果。对重复的请求,返回同一个结果。token机制的应用十分广泛。

