爬虫:requests高级用法、代理池搭建、爬取某视频网站、爬取新闻
一、requests高级用法
1.0 解析json格式数据
发送http请求,返回的数据会有xml格式,也有json格式
这里我们介绍反序列化json格式数据的requests模块的方法
这里我们访问肯德基的官网,然后拉到最下面点击餐厅查询
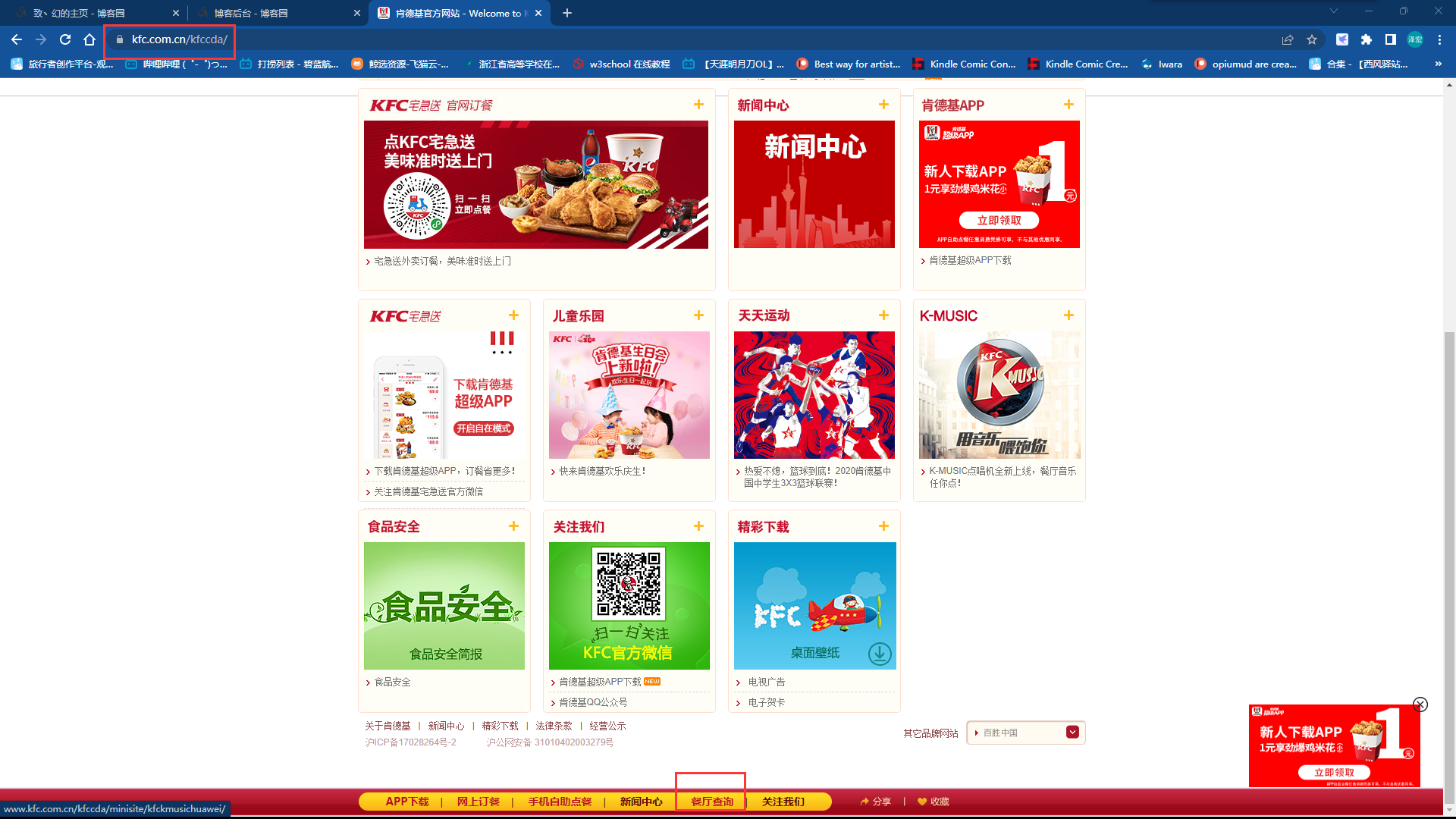
接着我们在这里的搜索框中输入500进行搜索,我们会发现这个网站向kfc的服务器发送了一个请求,请求的内容如下
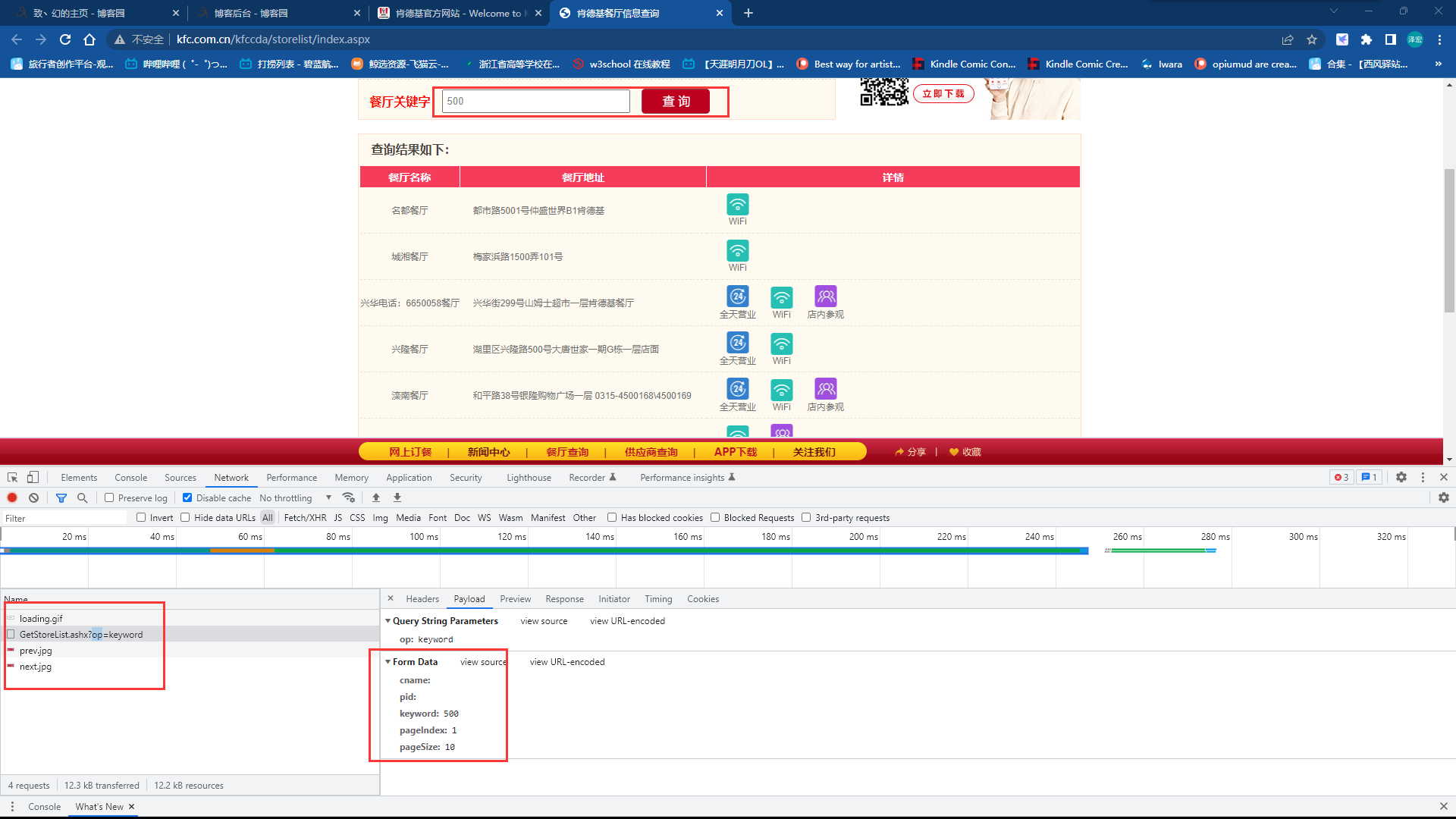
我们拿着这些参数,用python代码发送请求获取,返回结果

运行代码后我们可以得到下面的结果,通过结果可以判断出他返回的数据是json格式的字符串
import requests
data = {
'cname': '',
'pid': '',
'keyword': '500',
'pageIndex': 1,
'pageSize': 10,
}
res = requests.post('http://www.kfc.com.cn/kfccda/ashx/GetStoreList.ashx?op=keyword', data=data)
print(res.text)
print(type(res.text))
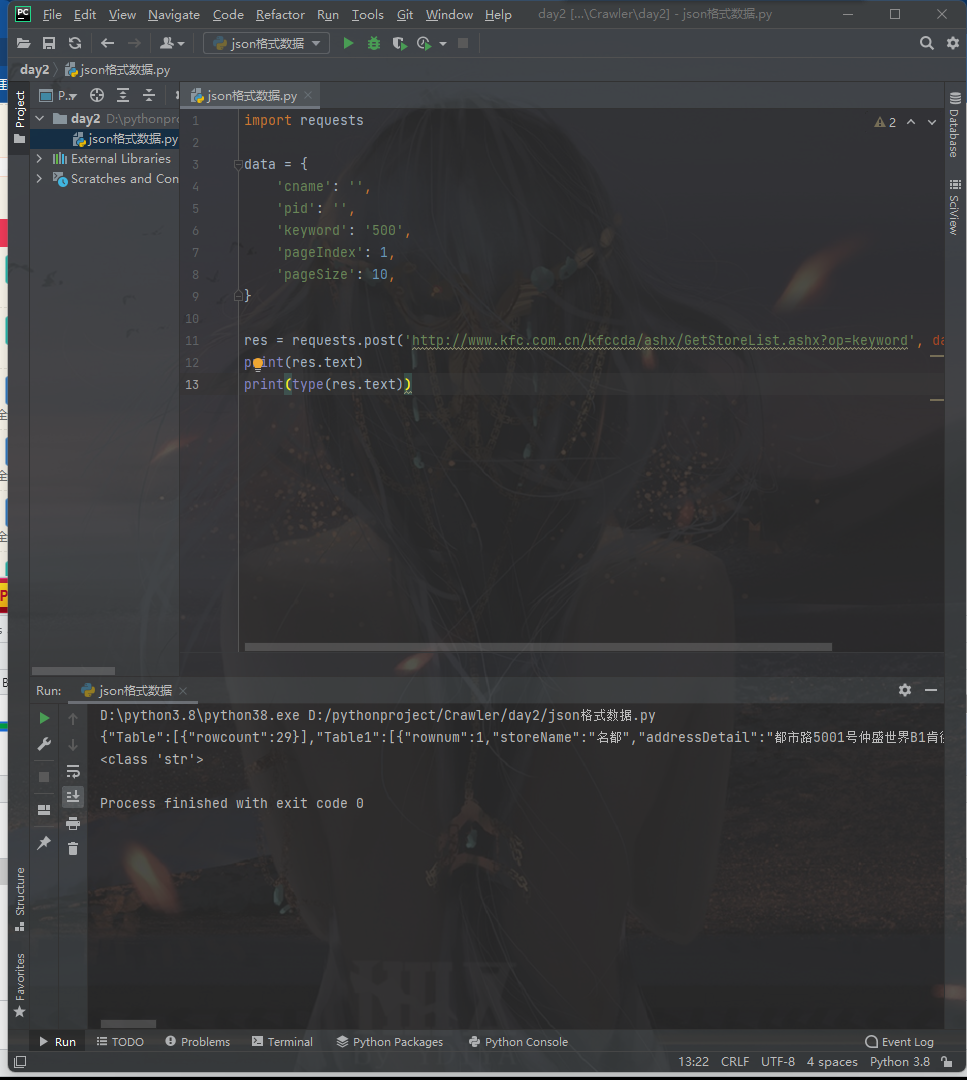
这样的json字符串我们可以在json.cn上线上反序列化,进行临时查看
但是在requests模块中,我们可以使用json方法直接把他反序列化
import requests
data = {
'cname': '',
'pid': '',
'keyword': '500',
'pageIndex': 1,
'pageSize': 10,
}
res = requests.post('http://www.kfc.com.cn/kfccda/ashx/GetStoreList.ashx?op=keyword', data=data)
# print(res.text)
# print(type(res.text))
print(res.json())
print(type(res.json()))

1.1 ssl认证(了解)
# http协议:明文传输
# https协议:http+ssl/tsl
HTTP+ SSL / TLS,也就是在 http上又加了一层处理加密信息的模块,比 http安全,可防止数据在传输过程中被窃取、改变,确保数据的完整性
https://zhuanlan.zhihu.com/p/561907474
# 以后遇到证书提示错误问题 ssl xxx
1 不验证证书
import requests
respone=requests.get('https://www.12306.cn',verify=False) #不验证证书,报警告,返回200
print(respone.status_code)
2 关闭警告
import requests
from requests.packages import urllib3
urllib3.disable_warnings() #关闭警告
respone=requests.get('https://www.12306.cn',verify=False)
print(respone.status_code)
3 手动携带证书(了解)
import requests
respone=requests.get('https://www.12306.cn',
cert=('/path/server.crt',
'/path/key'))
print(respone.status_code)
1.2 使用代理(重要)
当我们使用爬虫访问别人的服务器时,如果使用自身实际的ip访问,很有可能被封ip,这就导致我们以后正常访问该网站也不行了
因此我们需要使用代理ip来访问别人的服务器
他的原理十分类似nginx,你访问代理ip,然后代理ip帮你去访问对方的服务器,再把数据返回给你,这样人家就封不到你的本地ip了
代理分成收费的和免费的(不稳定速度慢,巨慢)
requests模块中使用代理访问
import requests
# 基本格式
# res = requests.post('https://www.cnblogs.com', proxies={'http': '地址+端口'})
# 这里是两个免费的代理ip,我们可以通过相应的状态码来判断是否访问成功了
# res = requests.post('https://www.cnblogs.com', proxies={'http': '27.79.236.66:4001'})
res = requests.post('https://www.cnblogs.com', proxies={'http': '60.167.91.34:33080'})
print(res.status_code)
# 200
拓展知识
1、高匿代理和透明代理
-高匿,服务端拿不到真实客户端的ip地址
-透明:服务端能拿到真实客户端的ip地址
2、后端如何拿到真实客户端ip地址?
http请求头中有个 X-Forwarded-For 字段:是用来识别通过HTTP代理或负载均衡方式连接到Web服务器的客户端最原始的IP地址的HTTP请求头字段。
这一HTTP头一般格式如下:
X-Forwarded-For: client1, proxy1, proxy2, proxy3
其中的值通过一个 逗号+空格 把多个IP地址区分开, 最左边(client1)是最原始客户端的IP地址, 代理服务器每成功收到一个请求,就把请求来源IP地址添加到右边。 在上面这个例子中,这个请求成功通过了三台代理服务器:proxy1, proxy2 及 proxy3。请求由client1发出,到达了proxy3(proxy3可能是请求的终点)。请求刚从client1中发出时,XFF是空的,请求被发往proxy1;通过proxy1的时候,client1被添加到XFF中,之后请求被发往proxy2;通过proxy2的时候,proxy1被添加到XFF中,之后请求被发往proxy3;通过proxy3时,proxy2被添加到XFF中,之后请求的的去向不明,如果proxy3不是请求终点,请求会被继续转发。
鉴于伪造这一字段非常容易,应该谨慎使用X-Forwarded-For字段。正常情况下XFF中最后一个IP地址是最后一个代理服务器的IP地址, 这通常是一个比较可靠的信息来源。
3、X-Forwarded-For在代理转发和反向代理中的使用
在代理转发及反向代理中经常使用X-Forwarded-For 字段。
代理转发
在 代理转发的场景中,你可以通过内部代理链以及记录在网关设备上的IP地址追踪到网络中客户端的IP地址。处于安全考虑,网关设备在把请求发送到外网(因特网)前,应该去除 X-Forwarded-For 字段里的所有信息。这种情况下所有的信息都是在你的内部网络内生成,因此X-Forwarded-For字段中的信息应该是可靠的。
反向代理
在反向代理的情况下,你可以追踪到互联网上连接到你的服务器的客户端的IP地址, 即使你的网络服务器和互联网在路由上是不可达的。这种情况下你不应该信任所有X-Forwarded-For信息,其中有部分可能是伪造的。因此需要建立一个信任白名单来确保X-Forwarded-For中哪些IP地址对你是可信的。
最后一次代理服务器的地址并没有记录在代理链中,因此只记录 X-Forwarded-For 字段是不够的。完整起见,Web服务器应该记录请求来源的IP地址以及X-Forwarded-For 字段信息。 [1]
1.3 超时设置
访问某个网站的时候,如果指定时间内没有成功,就停止
import requests
respone=requests.get('https://www.baidu.com',timeout=0.0001)
1.4 异常处理
这里跟python的异常处理没什么区别,只是多了一些异常类型
import requests
from requests.exceptions import * #可以查看requests.exceptions获取异常类型
try:
r=requests.get('http://www.baidu.com',timeout=0.00001)
except ReadTimeout:
print('===:')
# except ConnectionError: #网络不通
# print('-----')
# except Timeout:
# print('aaaaa')
except RequestException:
print('Error')
1.5 上传文件
做爬虫一般不会上传后端,以后工作中可能需要你上传文件
# 3 上传文件
import requests
files = {'file': open('美女.png', 'rb')}
respone = requests.post('http://httpbin.org/post', files=files)
print(respone.status_code)
二、代理池搭建
2.1 代理池介绍
上文中,我们介绍了使用代理ip运行爬虫发送请求
但是代理ip从哪来的?
一般有两个来源:
- 公司花钱买
- 搭建免费的代理池:
- https://github.com/jhao104/proxy_pool
- 这是一个很牛的开源代理池,有空可以去研究,网站上有文档
- 架构介绍,当我们自己部署了这个项目后,我们运行这个项目,爬取网上免费的代理,然后把能用的代理ip存储到redis中,以后使用爬虫发送请求的时候就会随机从这些ip中拿一个使用
2.2 搭建步骤
步骤一
访问该项目的网站,使用git克隆到本地,或直接以zip的方式下载
步骤二
使用pycharm打开项目后,安装依赖
这里我创建了一个虚拟环境,给这个项目使用
mkvirtualenv -p python3.8 proxy_pool-master
进入虚拟环境后,一次性安装requirements.txt里面所有的依赖包
pip install -r requirements.txt
步骤三
修改配置文件(根据实际情况修改,这里其实没改,哈哈哈)
这是项目运行的ip HOST = "0.0.0.0" 这是端口号 PORT = 5010 这是redis的存储位置,我们获取到可用的免费代理ip就会存储在这里,我的redis没有配置密码 DB_CONN = 'redis://127.0.0.1:6379/0' 爬取哪些免费代理网站 PROXY_FETCHER = [ "freeProxy01", "freeProxy02", "freeProxy03", "freeProxy04", "freeProxy05", "freeProxy06", "freeProxy07", "freeProxy08", "freeProxy09", "freeProxy10" ]
步骤四
启动爬虫程序,我们可以在项目路径下找到proxyPool.py
这一步操作是获取可用的代理ip
python proxyPool.py schedule
步骤五
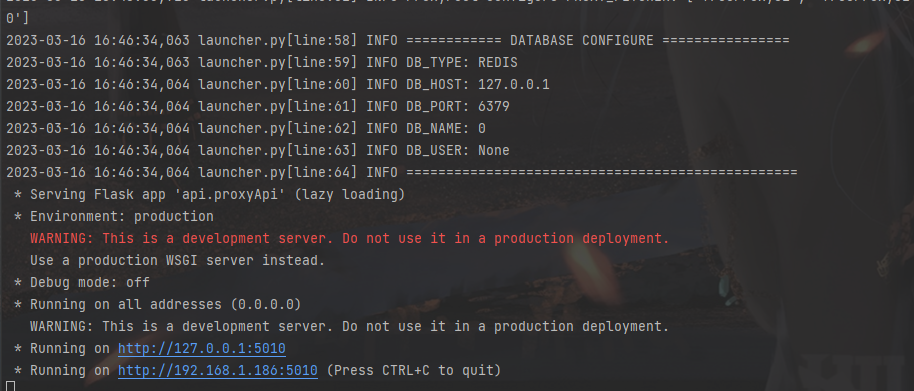
启动服务端
python proxyPool.py server
启动服务端后我们就可以看到下图界面
步骤六
介绍使用
ps:启动后不要关闭服务
- Api
启动web服务后, 默认配置下会开启 http://127.0.0.1:5010 的api接口服务:
| api | method | Description | params |
|---|---|---|---|
| / | GET | api介绍 | None |
| /get | GET | 随机获取一个代理 | 可选参数: ?type=https 过滤支持https的代理 |
| /pop | GET | 获取并删除一个代理 | 可选参数: ?type=https 过滤支持https的代理 |
| /all | GET | 获取所有代理 | 可选参数: ?type=https 过滤支持https的代理 |
| /count | GET | 查看代理数量 | None |
| /delete | GET | 删除代理 | ?proxy=host:ip |
2.3 使用随机代理发送请求
当我们使用127.0.0.1:5010/get/访问的时候我们可以随机获得一个代理ip,这里我们可以发现他的返回信息中会对是否为https请求做出一个判断
# 使用随机代理发送请求
import requests
from requests.packages import urllib3
urllib3.disable_warnings() #关闭警告
# 获取代理
res = requests.get('http://127.0.0.1:5010/get/').json()
proxies = {}
if res['https']:
proxies['https'] = res['proxy']
else:
proxies['http'] = res['proxy']
print(proxies)
# 判断了代理发送的请求类型后,我们就可以使用他发送请求了,然后配置了verify=False关闭了ssl证书的警告
res = requests.post('https://www.cnblogs.com', proxies=proxies,verify=False)
# res = requests.post('https://www.cnblogs.com')
不用代理就访问的特别快
print(res)
2.4 django后端获取客户端的ip
建立一个django后端---》让客户端可以通过ip地址直接访问到我们编写的视图函数---》视图函数的作用:访问就返回访问者的ip
urls.py
from django.urls import path
from app01.views import index
urlpatterns = [
# path('admin/', admin.site.urls),
path('', index),
]
views.py
from django.shortcuts import render, HttpResponse
# Create your views here.
def index(request):
ip = request.META.get('REMOTE_ADDR')
print('ip地址是', ip)
return HttpResponse(ip)
测试端代码
# import requests
# from requests.packages import urllib3
# urllib3.disable_warnings() #关闭警告
# # 获取代理
# res = requests.get('http://127.0.0.1:5010/get/').json()
# proxies = {}
# if res['https']:
# proxies['https'] = res['proxy']
# else:
# proxies['http'] = res['proxy']
#
# print(proxies)
# res=requests.get('http://101.43.19.239/', proxies=proxies,verify=False)
# print(res.text)
from threading import Thread
import requests
def task():
res = requests.get('http://101.43.19.239/')
print(res.text)
for i in range(10000000):
t = Thread(target=task)
t.start()
三、爬取某视频网站
我们去梨视频网站,爬点视频
当我们去访问的时候,我们发现他是用的我们之前说的第三种分页方式,每当页面到最底下,就会发送请求获取后面一页的内容,把他渲染成html代码直接插入到网页中
这里我们用控制台查看获取下一页的请求的内容
https://pearvideo.com/category_loading.jsp?reqType=5&categoryId=1&start=48&mrd=0.7909549649519632&filterIds=1429224,1266814,1461920,1304665,1400149,1015006,1212452,1437805,1129766,1056968,1404541,1402208,1398086,1005137,1380123,1070860,1304050,1050495,1394977,1361567,1392742,1001185,1404074,1399659
当我们修改start参数的时候,页面发生了变化,由此我们可以判断出他是控制当前展示网页的页数的
而categoryId在修改成2后变成了别的版块的数据,因此我们可以判断出他是控制分类的
但是当reqType被修改的时候,页面也出现了变化,课时我们不太好分辨变化的内容是什么,因此我们不对他做更改,单页不能删除他,把他带在请求中即可
import requests
import re
res = requests.get('https://www.pearvideo.com/category_loading.jsp?reqType=5&categoryId=1&start=0')
# print(res.text)
# 解析出真正视频地址
video_list = re.findall('<a href="(.*?)" class="vervideo-lilink actplay">', res.text)
# print(video_list)
for i in video_list:
# i='video_1212452'
video_id = i.split('_')[-1]
real_url = 'https://www.pearvideo.com/' + i
# print('真正视频地址是:',real_url)
headers = {
'Referer': 'https://www.pearvideo.com/video_%s' % video_id
}
res1 = requests.get('https://www.pearvideo.com/videoStatus.jsp?contId=%s&mrd=0.29636538326105044' % video_id,
headers=headers).json()
# print(res1["videoInfo"]['videos']['srcUrl'])
mp4_url = res1["videoInfo"]['videos']['srcUrl']
mp4_url = mp4_url.replace(mp4_url.split('/')[-1].split('-')[0], 'cont-%s' % video_id)
print(mp4_url)
res2 = requests.get(mp4_url)
with open('./video/%s.mp4' % video_id, 'wb') as f:
for line in res2.iter_content():
f.write(line)
# headers={
# 'Referer': 'https://www.pearvideo.com/video_1212452'
# }
# res=requests.get('https://www.pearvideo.com/videoStatus.jsp?contId=1212452&mrd=0.29636538326105044',headers=headers)
#
# print(res.text)
# https://video.pearvideo.com/mp4/short/20171204/ 1678938313577 -11212458-hd.mp4
# https://video.pearvideo.com/mp4/short/20171204/ cont-1212452 -11212458-hd.mp4
mp4_url = 'https://video.pearvideo.com/mp4/short/20171204/ 1678938313577-11212458-hd.mp4'
流程讲解
在上面的分析中我们知道了怎么爬视频的请求地址,从而获取一页的网页信息
我们从里面筛选出每个视频的id,把所有视频的路由都组合出来
然后我们去视频的播放页面查找每个视频的获取路由,这里我们会发现进入页面的时候获取的是假视频的路由,实际播放的时候是发送了一个ajax请求获取到真正的视频地址,因此我们要用真正的地址去跟我们的视频id进行组合
然后我们就会发现这里我们还是访问不到视频,跟原本的请求对比,我们发现我们需要一个Referer字段,指定前来的路由
这样之后,我们再在请求中携带上Referer字段,发送请求会获得一串返回的数据,我们可以发现真正的视频地址是存在这里的,而这些地址也不能访问到对应的视频
这时候我们把新获取的地址跟浏览器中实际播放时的地址进行对比,我们发现他们的路由有些参数要更改
到此为止就可以访问到真正的视频了,但是他的视频全带水印
四、爬取新闻
这里我们用bs4对新闻的数据做一个过滤
import requests
# pip install beautifulsoup4 解析xml的库
from bs4 import BeautifulSoup
res = requests.get('https://www.autohome.com.cn/all/1/#liststart')
# print(res.text)
# 第一个参数是要解析的文本 str
# 第二个参数是:解析的解析器 html.parser:内置解析器 lxml:第三方需要额外安装
soup = BeautifulSoup(res.text, 'html.parser')
# 查找所有类名叫article的ul标签 find_all
ul_list = soup.find_all(name='ul', class_='article')
for ul in ul_list:
li_list = ul.find_all(name='li')
# print(len(li_list))
for li in li_list:
h3 = li.find(name='h3')
if h3: # 不是广告
title = h3.text
url = 'https:' + li.find('a').attrs['href']
desc = li.find('p').text
img = li.find(name='img').attrs['src']
print('''
新闻标题:%s
新闻连接:%s
新闻摘要:%s
新闻图片:%s
''' % (title, url, desc, img))
# 把所有图片下载到本地,把爬完的数据,存到mysql中---》pymysql---》commit
五、作业
1、多线程5页爬视频
2、爬100页新闻,存到mysql,图片下载到本地
3、什么是反向代理,什么是正向代理
https://www.cnblogs.com/liuqingzheng/p/10521675.html

 浙公网安备 33010602011771号
浙公网安备 33010602011771号