爬虫:爬虫介绍、request模块介绍、request发送get请求、request携带参数、url的编码解码、请求携带请求头、发送post请求,携带数据、自动登录,携带cookie的两种方式、 requests.session的使用、补充post请求携带数据编码格式、响应对象Response的属性和方法、编码问题、下载图片,视频
一、爬虫介绍
1、爬虫是什么?
如果我们把互联网比作一张大的蜘蛛网,数据便是存放于蜘蛛网的各个节点,而爬虫就是一只小蜘蛛,
沿着网络抓取自己的猎物(数据)
爬虫是什么?
爬虫就是一个程序,从互联网中,各个网站上,爬取数据[你能浏览的页面才能爬],做数据清洗,入库
爬虫的本质是什么?
模拟http请求,通过访问网站或是对app抓包,获取数据,入库
从技术层面来说就是 通过程序模拟浏览器请求站点的行为,把站点返回的HTML代码/JSON数据/二进制数据(图片、视频) 爬到本地,进而提取自己需要的数据,存放起来使用;
补充知识
百度其实就是一个大爬虫
-百度爬虫一刻不停的在互联网中爬取各个页面---》爬取完后---》保存到自己的数据库中
-你在百度搜索框中搜索---》百度自己的数据库查询关键字---》返回回来
-点击某个页面----》跳转到真正的地址上
-seo:
-sem:充钱的

2、爬虫的基本流程:
用户获取网络数据的方式:
方式1:浏览器提交请求--->下载网页代码--->解析成页面
方式2:模拟浏览器发送请求(获取网页代码)->提取有用的数据->存放于数据库或文件中
爬虫要做的就是方式2;

1、发起请求
使用http库向目标站点发起请求,即发送一个Request
Request包含:请求头、请求体等
Request模块缺陷:不能执行JS 和CSS 代码
2、获取响应内容
如果服务器能正常响应,则会得到一个Response
Response包含:html,json,图片,视频等
3、解析内容
解析html数据:正则表达式(RE模块),第三方解析库如Beautifulsoup,pyquery等
解析json数据:json模块
解析二进制数据:以wb的方式写入文件
4、保存数据
数据库(MySQL,Mongdb、Redis)
文件
3、我们要学习的内容
-模拟发送http请求
- requests模块
- selenium
-反扒:封ip:ip代理,封账号:cookie池
-解析数据:bs4
-入库:mysql,redis,文件中
-爬虫框架:scrapy
二、request模块介绍
使用requests可以模拟浏览器的请求,比起之前用到的urllib,requests模块的api更加便捷(本质就是封装了urllib3)
注意:requests库发送请求将网页内容下载下来以后,并不会执行js代码,这需要我们自己分析目标站点然后发起新的request请求
安装request模块
pip3 install requests
各种请求方式介绍
常用的就是requests.get()和requests.post()
>>> import requests >>> r = requests.get('https://api.github.com/events') >>> r = requests.post('http://httpbin.org/post', data = {'key':'value'}) >>> r = requests.put('http://httpbin.org/put', data = {'key':'value'}) >>> r = requests.delete('http://httpbin.org/delete') >>> r = requests.head('http://httpbin.org/get') >>> r = requests.options('http://httpbin.org/get')
ps:建议在正式学习requests前,先熟悉下HTTP协议
三、request发送get请求
import requests
# 基本请求
res = requests.get('https://www.cnblogs.com/zhihuanzzh/p/17216014.html')
print(res.text)
# res获取到的是一个响应对象,点text后我们可以获取到响应体中 的内容
# 这是博客园的网址,我们访问后就可以获取到内容
# 如果有的网站,发送请求,不返回数据,人家做了反扒---》拿不到数据,学习如何反扒
res = requests.get('https://dig.chouti.com/')
print(res.text)
最后的这个网址因为做了反扒,所以我们会受到请求被拦截的提示,这时候就不要接着访问这个网址了,人家会把我们的ip给禁掉的,这样以后就访问不了了
四、request携带参数
之前学习前端的时候,我们可以在url中携带参数,专递信息,这里也是一样的携带方式
import requests
# 方式一:直接拼接到路径中
res = requests.get('https://www.cnblogs.com/zhihuanzzh/p/17216014.html?name=lqz&age=19')
print(res.text)
# 这里我们携带了参数,但是因为我们只是访问这篇博客,并不需要参数,所以带了也没啥用
# 方式二:使用params参数
# 这就跟使用axios发送ajax请求时候一样的,使用params携带参数
res = requests.get('https://www.cnblogs.com/zhihuanzzh/p/17216014.html', params={'name': "彭于晏", 'age': 19})
print(res.text)
print(res.url)
五、url的编码解码
当我们在运行上面的代码时,可以发现路由在打印的时候,中文被编码成了别的字符
import requests
res = requests.get('https://www.cnblogs.com/liuqingzheng/p/16005866.html', params={'name': "彭于晏", 'age': 19})
print(res.text)
print(res.url)
# # 如果是中文,在地址栏中会做url的编码:彭于晏:%E5%BD%AD%E4%BA%8E%E6%99%8F
# 'https://www.baidu.com/s?wd=%E5%B8%85%E5%93%A5'
我们也可以使用urllib模块对路由中的中文进行编码和解码
from urllib.parse import quote, unquote
# 编码:
res = quote('彭于晏')
print(res)
# %E5%BD%AD%E4%BA%8E%E6%99%8F
# 解码
res = unquote('%E5%BD%AD%E4%BA%8E%E6%99%8F')
print(res)
# 彭于晏
六、请求携带请求头
上面第三个知识点中,我们提到做了反扒的网站可以识别出我们是不是在执行爬虫程序
人家上了防护手段,我们也有对策解决,那就是携带请求头发送请求
http请求中,请求头中有一个很重要的参数 User-Agent(可以在控制台界面查看)
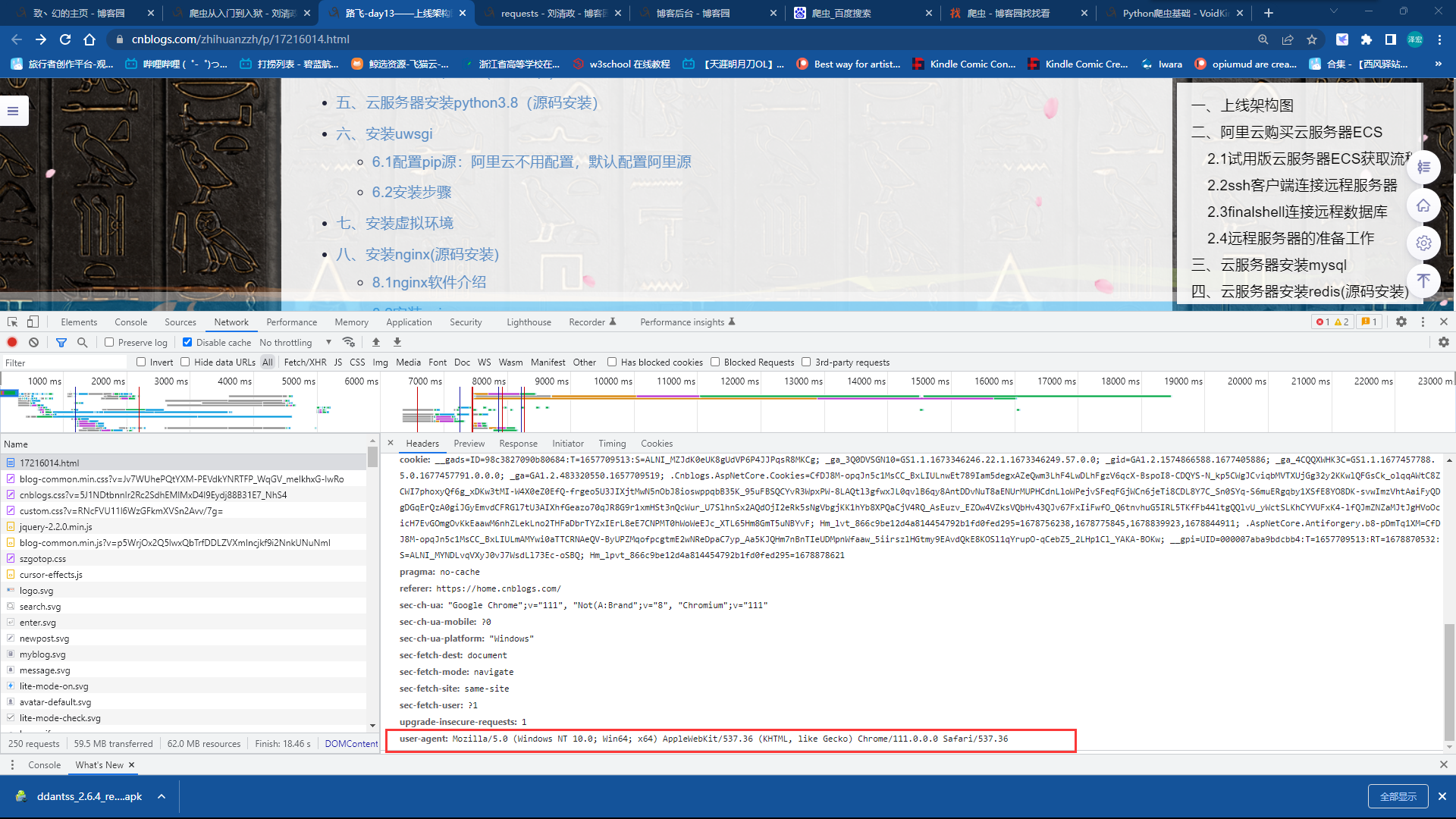
User-Agent作用
-表明了客户端类型是什么:Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/111.0.0.0 Safari/537.36
-如果没有带这个请求头,后端就禁止
-request发送请求,没有携带该参数,所以有的网站就禁止了
代码携带请求头
这里的操作也跟axios相似
import requests
# http请求头:User-Agent,cookie,Connection
# http协议版本间的区别
# Connection: keep-alive
# http协议有版本:主流1.1 0.9 2.x
# http 基于TCP 如果建立一个http链接---》底层创建一个tcp链接
# 1.1比之前多了keep-alive
# 2.x比1.x多了 多路复用
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/111.0.0.0 Safari/537.36'
}
res = requests.get('https://dig.chouti.com/', headers=headers)
print(res.text)
添加了这个请求头之后,我们就可以发现可以访问之前被拦截的网站了
ps:有空可以去了解一下不同版本的http协议有什么改动
七、发送post请求,携带数据
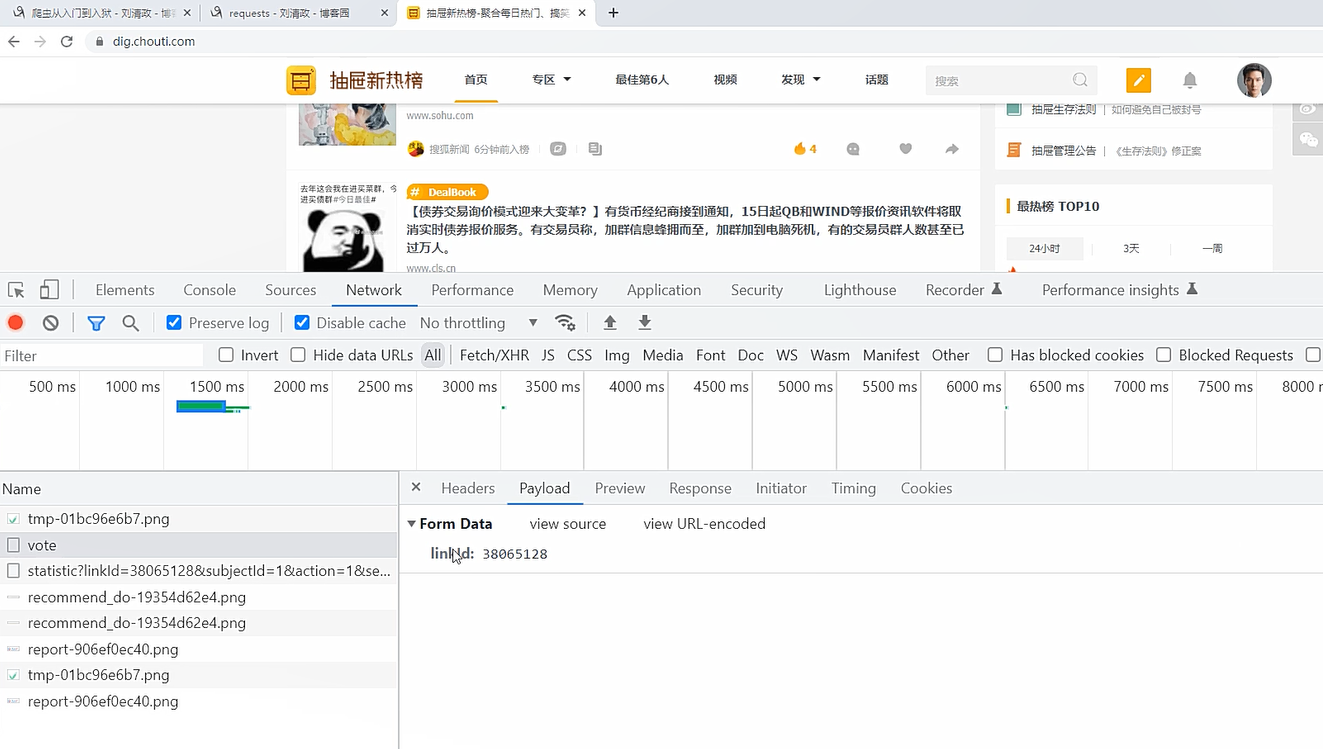
在使用post请求发送数据的时候,我们打开控制台,可以看到我们的动作是会向后端发送请求的,这里我们登陆抽屉新热榜后,可以进行点赞操作,他会向后端发送post请求携带一个linkId,不同的数字参数,对应不同的页面
这时候如果我们想要模仿浏览器用代码去执行点赞功能
首先我们要考虑到,怎么让后端判断我们登陆了
这里我们可以在控制台页面看到刚才那个请求携带了一大串的cookie,他们这个网站使用cookie进行校验的,我们把这个信息也添加到请求头中去
然后需要使用data参数来携带数据,这里带的就是linkId
import requests
# 携带登录信息,携带cookie
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/105.0.0.0 Safari/537.36',
'Cookie': 'cookie的数据'
}
# post请求,携带参数
data = {
'linkId': '38063872'
}
res = requests.post('https://dig.chouti.com/link/vote', headers=headers, data=data)
print(res.text)
执行代码后,就相当于给对应linkId的作品点赞了
ps:通过刚才的代码测试,我们也反向了cookie并不安全,这里我们可以使用双token认证,来提高安全性
八、自动登录,携带cookie的两种方式
这里的自动登陆,我们使用华华手机来测试,不因为别的,就因为他家的验证码其实是不校验的,用户名跟密码对了就可以直接登陆
我们在华华手机的网站上打开控制台,然后随便输入一些信息,点击登陆,就可以找到一个请求,就可以找到请求的内容
点开后就可以看到他携带的参数
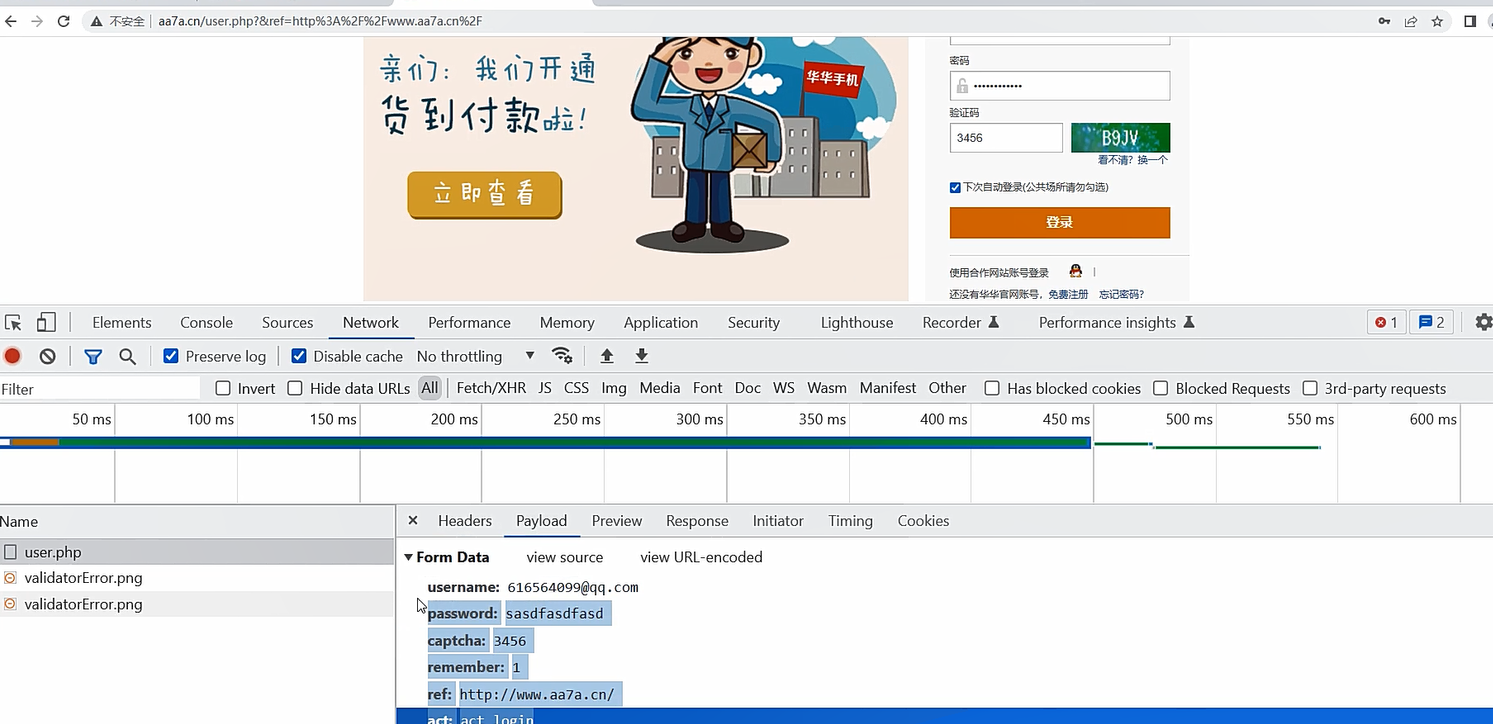
我们把他的参数复制过来放到我们的data中,然后写上正确的账号信息,发送请求后,就可以得到登陆成功的结果
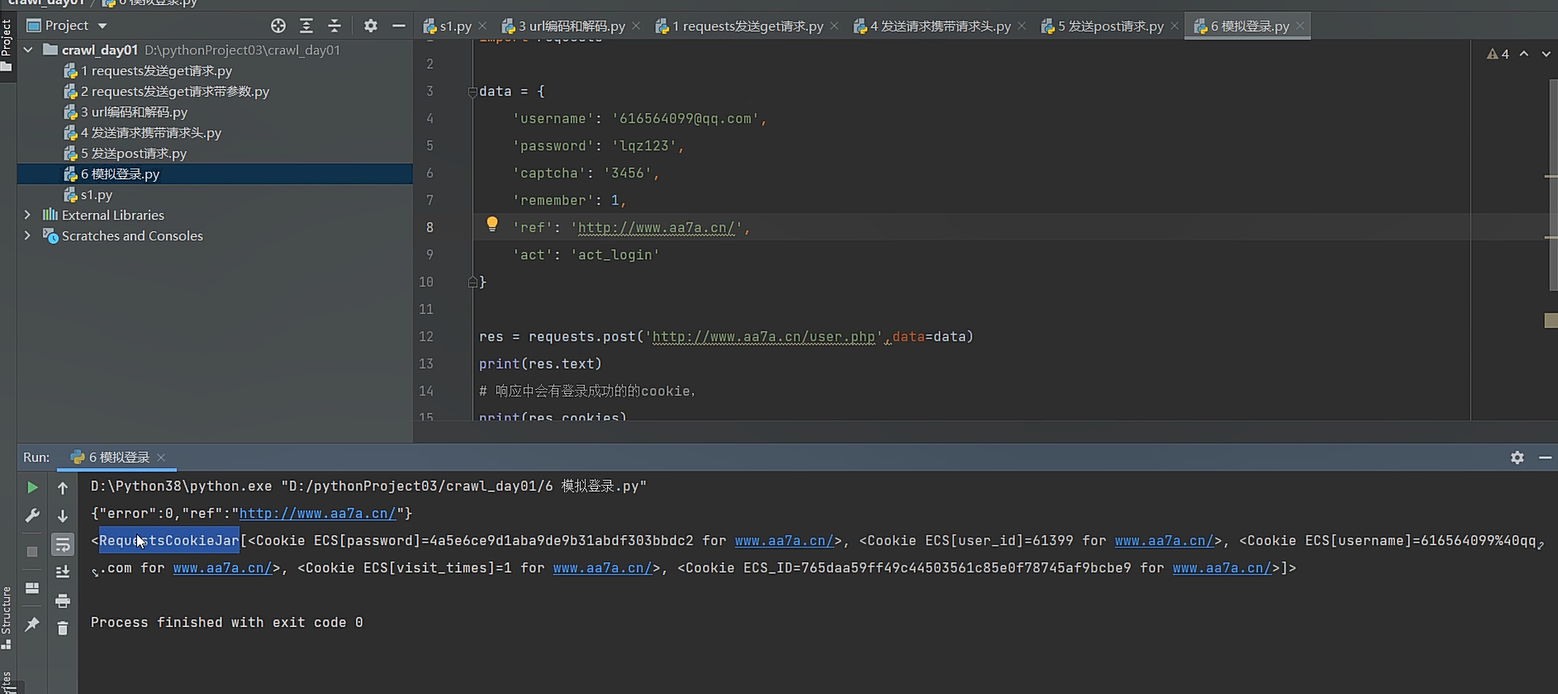
然后我们把这个cookie的信息放到我们代码的请求头中,以后就可以以登陆后的状态去访问网站了
# 登录功能,一般都是post
import requests
data = {
'username': '',
'password': '',
'captcha': '3456',
'remember': 1,
'ref': 'http://www.aa7a.cn/',
# ref相当于是登陆成功后重定向的页面
'act': 'act_login'
}
res = requests.post('http://www.aa7a.cn/user.php',data=data)
print(res.text)
# 响应中会有登录成功的的cookie,
print(res.cookies) # RequestsCookieJar 跟字典一样
# 拿着这个cookie,发请求,就是登录状态
# 访问首页,get请求,携带cookie,首页返回的数据一定会有 我的账号
# 携带cookie的两种方式 方式一是字符串,方式二是字典或CookieJar对象
# 方式二:放到cookie参数中
res1=requests.get('http://www.aa7a.cn/',cookies=res.cookies)
print('616564099@qq.com' in res1.text)
九、requests.session的使用
如果每次请求都需要携带cookie,让人感到很麻烦
这里我们介绍requests.session的使用
当我们使用requests.session()创建了一格session对象后,我们后面都用这个对象来发送请求,这样的话,我们只需要在最开始的请求中登陆一下,后面的请求会自动保持cookie的状态,不需要我们自行配置携带cookie
# 为了保持cookie ,以后不需要携带cookie
import requests
data = {
'username': '用户名',
'password': '密码',
'captcha': '3456',
'remember': 1,
'ref': 'http://www.aa7a.cn/',
'act': 'act_login'
}
session = requests.session()
res = session.post('http://www.aa7a.cn/user.php', data=data)
print(res.text)
res1 = session.get('http://www.aa7a.cn/') # 自动保持登录状态,自动携带cookie
print('616564099@qq.com' in res1.text)
# 结果会是True
十、补充post请求携带数据编码格式
import requests
# data对应字典,这样写,编码方式是urlencoded
requests.post(url='xxxxxxxx',data={'xxx':'yyy'})
# json对应字典,这样写,编码方式是json格式
requests.post(url='xxxxxxxx',json={'xxx':'yyy'})
# 终极方案,编码就是json格式,这里我们可以自己指定编码方式
requests.post(url='',
data={'':1,},
headers={
'content-type':'application/json'
})
十一、响应对象Response的属性和方法
# Response相应对象的属性和方法
import requests
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/105.0.0.0 Safari/537.36'
}
respone=requests.get('http://www.jianshu.com',headers=headers)
# respone属性
print(respone.text) # 响应体转成了字符串
print(respone.content) # 响应体的二进制内容
print(respone.status_code) # 响应状态码
print(respone.headers) # 响应头
print(respone.cookies) # cookie是在响应头,cookie很重要,它单独做成了一个属性
print(respone.cookies.get_dict()) # cookieJar对象---》转成字段
print(respone.cookies.items()) # cookie的键值对
print(respone.url) # 请求地址
print(respone.history) # 不用关注
print(respone.encoding) # 响应编码格式
十二、编码问题
#编码问题
import requests
response=requests.get('http://www.autohome.com/news')
# response.encoding='gbk' #汽车之家网站返回的页面内容为gb2312编码的,而requests的默认编码为ISO-8859-1,如果不设置成gbk则中文乱码
print(response.text)
# 有的网站,打印
res.text --->发现乱码---》请求回来的二进制---》转成了字符串---》默认用utf8转---》
response.encoding='gbk'
再打印res.text它就用gbk转码
十三、下载图片,视频
在前面的属性介绍中,我们提到respone.content 可以返回响应体的二进制内容
因此我们下载图片跟视频,就是用代码获取资源的url,然后再使用content保存他的二进制数据
import requests
# res=requests.get('http://pic.imeitou.com/uploads/allimg/230224/7-230224151210-50.jpg')
# # print(res.content)
# with open('美女.jpg','wb') as f:
# f.write(res.content)
#
res=requests.get('https://vd3.bdstatic.com/mda-pcdcan8afhy74yuq/sc/cae_h264/1678783682675497768/mda-pcdcan8afhy74yuq.mp4')
with open('致命诱惑.mp4','wb') as f:
for line in res.iter_content():
f.write(line)
stream参数
一点一点的取数据,比如下载视频时,如果视频100G,用response.content然后一下子写到文件中是不合理的
import requests
response=requests.get('https://gss3.baidu.com/6LZ0ej3k1Qd3ote6lo7D0j9wehsv/tieba-smallvideo-transcode/1767502_56ec685f9c7ec542eeaf6eac93a65dc7_6fe25cd1347c_3.mp4',
stream=True)
with open('b.mp4','wb') as f:
for line in response.iter_content():
f.write(line)

 浙公网安备 33010602011771号
浙公网安备 33010602011771号