面向对象:单例模式实现的多种方式、pickle序列化模块、选课系统需求分析等
目录
一、单例模式实现的多种方式
方式一:使用类
class C1:
__instance = None
def __init__(self, name, age):
self.name = name
self.age = age
@classmethod
# 使用装饰器,让类加括号调用的时候也可以省略一个参数
def singleton(cls):
# 判断cls(也就是self)有没有这个属性,也就是判断之前内部有没有创建出__instance这个对象,如果有了就直接把他返回出去,如果没有就根据设定的参数创建一个
if not cls.__instance:
cls.__instance = cls('jason', 18)
return cls.__instance
# 这里的意思是如果不传参数产生新的对象,始终调用的是同一个对象
obj1 = C1.singleton()
obj2 = C1.singleton()
obj3 = C1.singleton()
print(id(obj1), id(obj2), id(obj3))
obj4 = C1('kevin', 28)
obj5 = C1('tony', 38)
print(id(obj4), id(obj5))
方法二:使用metaclass方式(自定义元类)
class Mymeta(type):
def __init__(self, name, bases, dic): # 定义类Mysql时触发
# 事先先从配置文件中取配置来造一个Mysql的实例出来(创建类的时候就给这个类创建一个默认对象)
self.__instance = object.__new__(self) # 产生对象
self.__init__(self.__instance, 'jason', 18) # 初始化对象
# 上述两步可以合成下面一步
# self.__instance=super().__call__(*args,**kwargs)
# 这里就是用type的代码生成新的类
super().__init__(name, bases, dic)
def __call__(self, *args, **kwargs): # Mysql(...)时触发
# 当类定义好了之后,被用来创建对象的时候就会触发双下call,如果没有传参就直接返回之前创建类时定义的默认对象,如果有参数就会生成新的对象返回出去
if args or kwargs: # args或kwargs内有值
obj = object.__new__(self)
self.__init__(obj, *args, **kwargs)
return obj
return self.__instance
class Mysql(metaclass=Mymeta):
def __init__(self, name, age):
self.name = name
self.age = age
# 这里的思路跟上面的相似,如果不传参数产生新的对象,始终调用的是同一个对象
obj1 = Mysql()
obj2 = Mysql()
print(id(obj1), id(obj2))
obj3 = Mysql('tony', 321)
obj4 = Mysql('kevin', 222)
print(id(obj3), id(obj4))
方法三:自定义双下new
# 类加括号无论执行多少次永远只会产生一个对象
class Singleton_:
def __new__(self, *args, **kwargs):
if not hasattr(self, '_instance'):
self._instance = super(Singleton_, self).__new__(self)
return self._instance
# 我们通过今天的学习得知双下new是产生对象的方法,因此我们在这里进行派生操作,
# 用hasatter检测当前类是是否已经有创建过对象,如果没有就新建一个(使用super拿元类的双下new直接创建),如果有就返回有的那个对象
a = Singleton_()
b = Singleton_()
print(a)
print(b)
方法四:基于模块的单例模式
在一个py文件中创建一个对象,然后让外面的代码一直调用这个类,从而达到单例模式的目的。
'''基于模块的单例模式:提前产生一个对象 之后导模块使用'''
class C1:
def __init__(self, name):
self.name = name
obj = C1('jason')
def outer(cls):
_instance = cls('jason', 18)
def inner(*args, **kwargs):
if args or kwargs:
obj = cls(*args, **kwargs)
return obj
return _instance
return inner
@outer # Mysql=outer(Mysql)
class Mysql:
def __init__(self, host, port):
self.host = host
self.port = port
obj1 = Mysql()
obj2 = Mysql()
obj3 = Mysql()
print(obj1 is obj2 is obj3) # True
obj4 = Mysql('1.1.1.3', 3307)
obj5 = Mysql('1.1.1.4', 3308)
print(obj3 is obj4) # False
二、pickle序列化模块
优势:
python中几乎所有的数据类型(列表,字典,集合,类等)都可以用pickle来序列化,我们的对象也可以。
缺陷:
1、只能够在python中使用,无法跨语言传输
2、pickle序列化后的数据,可读性差,人一般无法识别。(都是二进制,能看懂也不是一般人了)
方法介绍:
pickle.dump(obj, file[, protocol])
序列化对象,并将结果数据流写入到文件对象中。参数protocol是序列化模式,默认值为0,表示以文本的形式序列化。protocol的值还可以是1或2,表示以二进制的形式序列化。
pickle.load(file)
反序列化对象。将文件中的数据解析为一个Python对象。
其中要注意的是,在load(file)的时候,要让python能够找到类的定义,否则会报错:
注:pickle模块保存数据的文件是没有格式的
"""
需求:产生一个对象并保存到文件中 取出来还是一个对象
"""
class C1:
def __init__(self, name, age):
self.name = name
self.age = age
def func1(self):
print('from func1')
def func2(self):
print('from func2')
obj = C1('jason', 18)
# 这里的对象,并不能以对象的格式存储到文件中,因此我们使用pickle模块
import pickle
with open(r'a.txt', 'wb') as f:
pickle.dump(obj, f)
with open(r'a.txt', 'rb') as f:
data = pickle.load(f)
print(data)
# <__main__.C1 object at 0x0000026712C75BB0>
三、选课系统需求分析
选课系统项目需求
角色:
学校、学员、课程、讲师
要求:
1. 创建北京、上海 2 所学校
2. 创建linux , python , go 3个课程 , linux\py 在北京开, go 在上海开
3. 课程包含,周期,价格,通过学校创建课程
4. 通过学校创建班级, 班级关联课程、讲师5. 创建学员时,选择学校,关联班级
5. 创建讲师角色时要关联学校,
6. 提供三个角色接口
6.1 学员视图, 可以注册, 交学费, 选择班级,
6.2 讲师视图, 讲师可管理自己的班级, 上课时选择班级, 查看班级学员列表 , 修改所管理的学员的成绩
6.3 管理视图,创建讲师, 创建班级,创建课程
7. 上面的操作产生的数据都通过pickle序列化保存到文件里
四、功能提炼
1.管理员功能
- 登录功能
- 创建学校
- 创建课程
- 创建老师
2.讲师功能
- 登录功能
- 选择课程
- 查看课程
- 查看学生分数
- 修改学生分数
3.学生功能
- 注册功能
- 登录功能
- 选择学校
- 选择课程
- 查看课程分数
五、选课系统架构设计
使用的也是三层架构结构
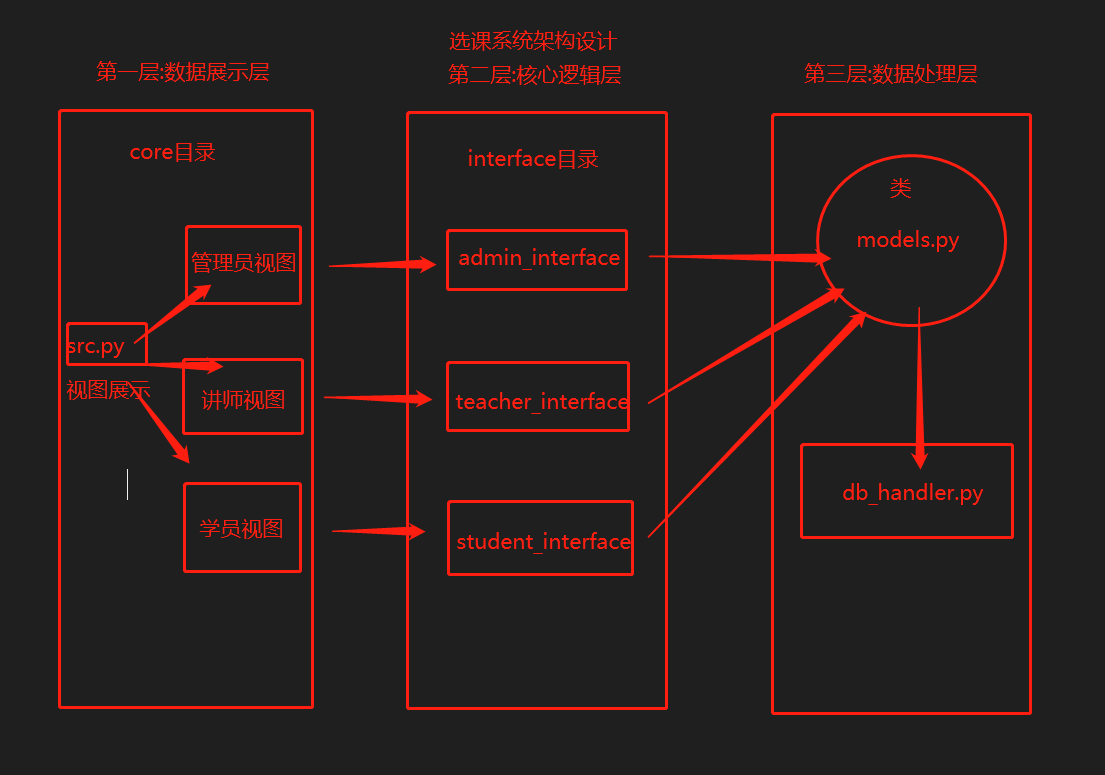
三层架构
功能展示层
- src.py
- admin_view.py
- teacher_view.py
- student_view.py
核心逻辑层
- admin_interface.py
- teacher_interface.py
- student_interface.py
数据处理层
- db_hanlder.py
- model.py
六、选课系统目录搭建和功能划分
目录搭建
这里我们依旧使用软件开发目录规范
功能划分
| 包/文件 | 功能 |
|---|---|
| interface | 登录、注册、选课等接口 |
| core | 注册、登录、选课核心功能 |
| db | 存放注册的用户数据 |
| lib | 存放编写的公共方法文件 |
| conf | 存放配置文件 |
| readme.txt | 项目文档 |
| requirements.txt | 开发文件说明 |

