面向对象:面向对象概念引入(人狗大战)、面向对象核心思路前戏、编程思想分析、面向对象之类与对象、类与对象的创建、对象独有的数据推导流程、对象独有的功能推导流程
一、面向对象概念引入(人狗大战)
在讲面向对象之前我们用一个简单的人狗大战来引入这个概念,让人可以更加直观的感受到什么是面向对象编程。
人狗大战简介
就是用代码编写一个简单的小游戏,人跟狗可以互相攻击,这里我们用字典记录数据值。
推导步骤1:代码定义出人和狗
"""推导步骤1:代码定义出人和狗"""
person1 = {
'name': 'jason',
'age': 18,
'gender': 'male',
'p_type': '猛男',
'attack_val': 8000,
'life_val': 99999999
}
person2 = {
'name': 'kevin',
'age': 28,
'gender': 'female',
'p_type': '淑女',
'attack_val': 1,
'life_val': 100
}
dog1 = {
'name': '小黑',
'd_type': '泰迪',
'attack_val': 100,
'life_val': 8000
}
dog2 = {
'name': '小白',
'd_type': '恶霸',
'attack_val': 2,
'life_val': 80000
}
ps:这里我们不难发现,频繁进行重复的操作不够方便,我们会想到使用函数封装功能,因此有了第二个阶段。
推导步骤2:将产生人和狗的字典封装成函数并封装人和狗的攻击函数
"""推导步骤2:将产生人和狗的字典封装成函数并封装人和狗的攻击函数"""
def create_person(name, age, gender, p_type, attack_val, life_val):
person_dict = {
'name': name,
'age': age,
'gender': gender,
'p_type': p_type,
'attack_val': attack_val,
'life_val': life_val
}
return person_dict
def create_dog(name, d_type, attack_val, life_val):
dog_dict = {
'name': name,
'd_type': d_type,
'attack_val': attack_val,
'life_val': life_val
}
return dog_dict
# 定义好了函数之后只要调用函数并传入参数就可以获得新定义的人与狗
p1 = create_person('jason', 18, 'male', '猛男', 8000, 99999999)
p2 = create_person('kevin', 28, 'female', '淑女', 100, 800)
d1 = create_dog('小黑', '恶霸', 800, 900000)
d2 = create_dog('小白', '泰迪', 100, 800000)
print(p1, p2)
print(d1, d2)
# 定义出人打狗的动作 狗咬人的动作
def person_attack(person_dict, dog_dict):
print(f"人:{person_dict.get('name')}准备揍狗:{dog_dict.get('name')}")
dog_dict['life_val'] -= person_dict.get('attack_val')
print(f"人揍了狗一拳 狗掉血:{person_dict.get('attack_val')} 狗剩余血量:{dog_dict.get('life_val')}")
def dog_attack(dog_dict, person_dict):
print(f"狗:{dog_dict.get('name')}准备咬人:{person_dict.get('name')}")
person_dict['life_val'] -= dog_dict.get('attack_val')
print(f"狗咬了人一口 人掉血:{dog_dict.get('attack_val')} 人剩余血量:{person_dict.get('life_val')}")
# 其实就是根据字典的值进行加减
person_attack(p1, d1)
dog_attack(d2, p2)
推导步骤3:人和狗的攻击混乱
到了这一步,这个小游戏就可以运行起来玩了,但是我们又发现一个小问题,人的攻击函数和狗的攻击函数,并没有限制使用对象,这就导致有时候会出现如下问题:
jason这个人会扮成狗狗咬人
有的狗又会扮成人打人
"""推导步骤3:人和狗的攻击混乱"""
person_attack(d1, p1)
dog_attack(p1, d2)
为了解决这个问题,我们想到了可以使用功能字典的方式把函数名称传进去。通过这样的方式限制功能的调用方式。
二、面向对象核心思路前戏
推导步骤4:如何实现只有人只能调用的人的攻击动作,狗只能调用狗的攻击动作>>>:数据与功能的绑定
"""推导步骤4:如何实现只有人只能调用的人的攻击动作 狗只能调用狗的攻击动作>>>:数据与功能的绑定"""
def get_person(name, age, gender, p_type, attack_val, life_val):
# 产生人的函数(功能)
def person_attack(person_dict, dog_dict):
print(f"人:{person_dict.get('name')}准备揍狗:{dog_dict.get('name')}")
dog_dict['life_val'] -= person_dict.get('attack_val')
print(f"人揍了狗一拳 狗掉血:{person_dict.get('attack_val')} 狗剩余血量:{dog_dict.get('life_val')}")
# 表示人的信息(数据)
person_dict = {
'name': name,
'age': age,
'gender': gender,
'p_type': p_type,
'attack_val': attack_val,
'life_val': life_val,
'person_attack': person_attack
}
return person_dict
def get_dog(name, d_type, attack_val, life_val):
def dog_attack(dog_dict, person_dict):
print(f"狗:{dog_dict.get('name')}准备咬人:{person_dict.get('name')}")
person_dict['life_val'] -= dog_dict.get('attack_val')
print(f"狗咬了人一口 人掉血:{dog_dict.get('attack_val')} 人剩余血量:{person_dict.get('life_val')}")
dog_dict = {
'name': name,
'd_type': d_type,
'attack_val': attack_val,
'life_val': life_val,
'dog_attack': dog_attack
}
return dog_dict
person1 = get_person('jason', 18, 'male', '猛男', 8000, 99999999)
dog1 = get_dog('小黑', '恶霸', 800, 900000)
person1.get('person_attack')(person1, dog1)
由于功能字典定义在生成人或生成狗的函数内,而查找变量名和函数名称的时候只能向外面的名称空间查找,因此我们就把攻击的函数定义在生成函数内,让功能字典刚好可以调用到攻击函数。
面向对象核心思想:数据与功能的绑定
通过上面的推导流程,其实就是达成了一个目的,让一个对象的数据值和功能绑定到一起,只有这个对象才能调用。
三、编程思想分析
我们平时听到的面向对象本质其实是一种编程思想大致可以分为两种
- 面向过程编程
- 面向对象编程
1、编程思想之面向过程编程
过程即流程,面向过程就是按照固定的流程解决问题,将程序的执行流程化,即分步操作,分步的过程中解决问题。
eg:截止ATM为止 使用的几乎都是面向过程编程
注册功能 登录功能 转账功能
上述功能都需要列举出每一步的流程,并且随着步骤的深入,问题的解决越来越简单。
ps:过程可以理解成是流水线,面向过程编程可以理解成是在创建一条流水线。我们先提出问题,然后制定出该问题的解决方案。
2.面向对象编程
对象的概念
”面向对象“的核心是“对象”二字,而对象的精髓在于“整合“,什么意思?
所有的程序都是由”数据”与“功能“组成,因而编写程序的本质就是定义出一系列的数据,然后定义出一系列的功能来对数据进行操作。在学习”对象“之前,程序中的数据与功能是分离开的。如下所示:
# 数据:name、age、sex
name='lili'
age=18
sex='female'
# 功能:tell_info
def tell_info(name,age,sex):
print('<%s:%s:%s>' %(name,age,sex))
# 此时若想执行查看个人信息的功能,需要同时拿来两样东西,一类是功能tell_info,另外一类则是多个数据name、age、sex,然后才能执行,非常麻烦
tell_info(name,age,sex)
对象其实就是一个"容器" 将数据与功能整合到一起,只要是符合上述描述的事物都可以称之为是对象!!! (python中一切皆对象)。
在学习了“对象”之后,我们就有了一个容器,该容器可以盛放数据与功能,所以我们可以说:对象是把数据与功能整合到一起的产物,或者说”对象“就是一个盛放数据与功能的容器/箱子/盒子。
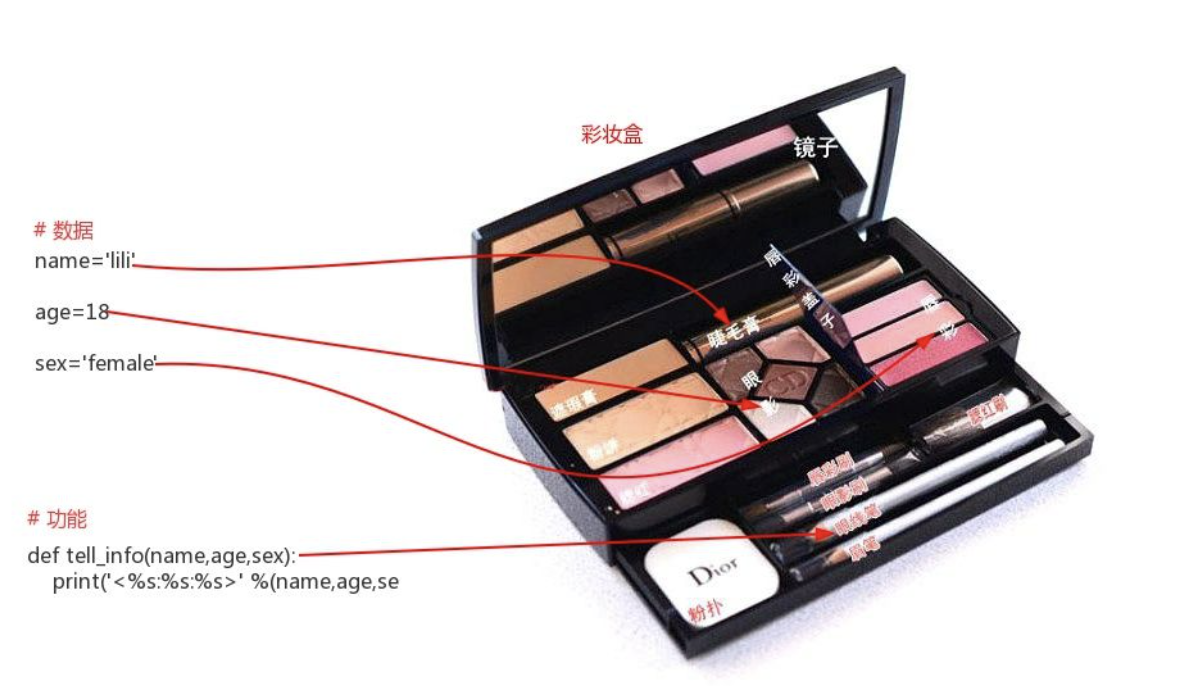
如果把”数据“比喻为”睫毛膏“、”眼影“、”唇彩“等化妆所需要的原材料;把”功能“比喻为眼线笔、眉笔等化妆所需要的工具,那么”对象“就是一个彩妆盒,彩妆盒可以把”原材料“与”工具“都装到一起。
如果我们把”化妆“比喻为要执行的业务逻辑,此时只需要拿来一样东西即可,那就是彩妆盒,因为彩妆盒里整合了化妆所需的所有原材料与功能,这比起你分别拿来原材料与功能才能执行,要方便的多。
eg:游戏人物:亚索 劫 盲僧
面向对象编程有点类似于造物主的感觉 我们只需要造出一个个对象
至于该对象将来会如何发展跟程序员没关系 也无法控制
上述两种编程思想没有优劣之分 需要结合实际需求而定:
如果需求是注册 登录 人脸识别肯定面向过程更合适
如果需求是游戏人物肯定是面向对象更合适
实际编程两种思想是彼此交融的 只不过占比不同
在了解了对象的基本概念之后,理解面向对象的编程方式就相对简单很多了,面向对象编程就是要造出一个个的对象,把原本分散开的相关数据与功能整合到一个个的对象里,这么做既方便使用,也可以提高程序的解耦合程度,进而提升了程序的可扩展性(需要强调的是,软件质量属性包含很多方面,面向对象解决的仅仅只是扩展性问题)
四、面向对象之类与对象
类即类别/种类,是面向对象分析和设计的基石,如果多个对象有相似的数据与功能,那么该多个对象就属于同一种类。有了类的好处是:我们可以把同一类对象相同的数据与功能存放到类里,而无需每个对象都重复存一份,这样每个对象里只需存自己独有的数据即可,极大地节省了空间。所以,如果说对象是用来存放数据与功能的容器,那么类则是用来存放多个对象相同的数据与功能的容器。
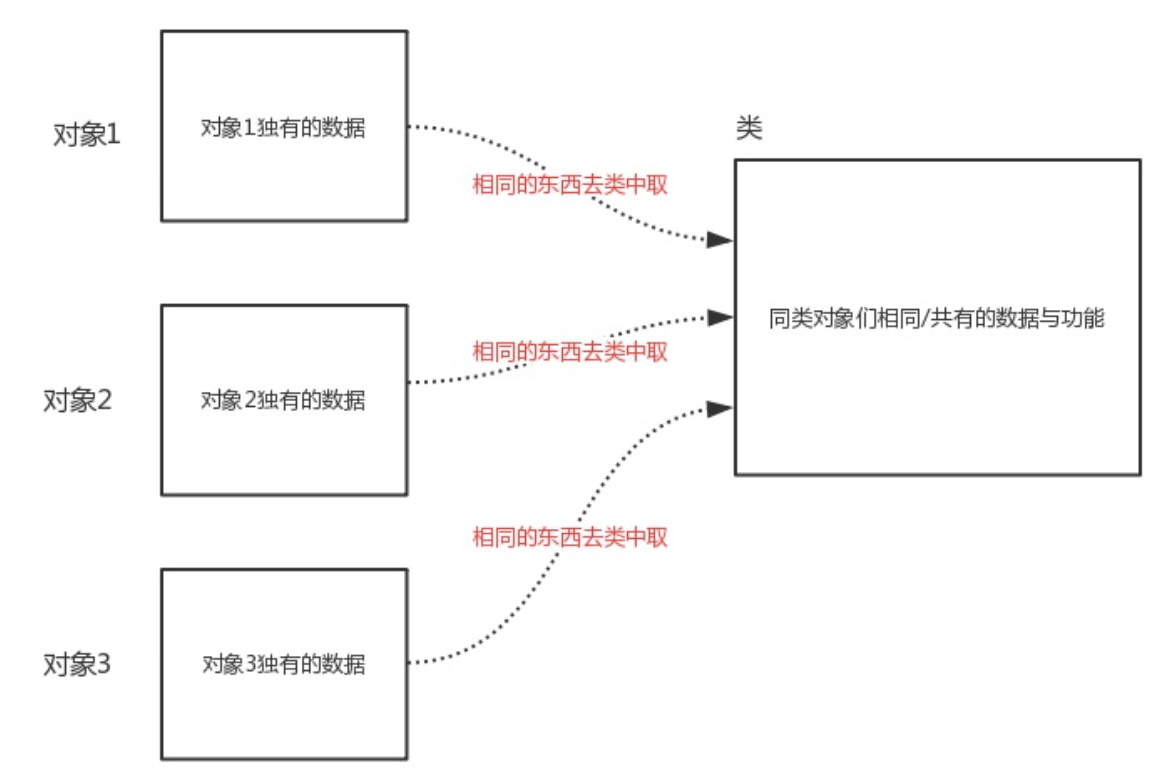
综上所述,虽然我们是先介绍对象后介绍类,但是需要强调的是:在程序中,必须要事先定义类,然后再调用类产生对象(调用类拿到的返回值就是对象)。产生对象的类与对象之间存在关联,这种关联指的是:对象可以访问到类中共有的数据与功能,所以类中的内容仍然是属于对象的,类只不过是一种节省空间、减少代码冗余的机制,面向对象编程最终的核心仍然是去使用对象。
在了解了类与对象这两大核心概念之后,我们就可以来介绍一下面向对象编程啦。
对象:数据与功能的结合体 对象才是核心
类:多个对象相同数据和功能的结合体 类主要就是为了节省代码
"""
一个人 对象
一群人 人类(所有人相同的特征)
一条狗 对象
一群狗 犬类(所有狗相同的特征)
"""
现实中一般是先有对象再有类
程序中如果想要产生对象 必须要先定义出类
说的再直白一点,就是先通过类创建对象,这时候的对象内部没有自己特有的内容,但是有类中公共的数据值和功能,当我们给他加上自己特有的内容后,这个对象就有了其他的功能和数据。
五、类与对象的创建
面向对象并不是一门新的技术 但是为了很好的一眼区分开 针对面向对象设计了新的语法格式
python中一定要有类 才能借助于类产生对象
1.类的语法结构
class 类名:
'''代码注释'''
对象公共的数据
对象公共的功能
1.class是定义类的关键字
2.类名的命名与变量名几乎一致 需要注意的时候首字母推荐大写用于区分
3.数据:变量名与数据值的绑定 功能(方法)其实就是函数
2.类的定义与调用
类在定义阶段就会执行类体代码 但是属于类的局部名称空间 外界无法直接调用
# 需求:清华大学学生选课系统
# 定义类
class Student:
# 对象公共的数据
school_name = '清华大学'
# 对象公共的功能
def choice_course(self):
print('学生选课功能')
1.查看名称空间
我们使用点+双下dict的方法获得类的名称空间,但是这并不意味类就是一个字典,只是我们用字典的形式给他表现出来。其次我们还可以在双下dict后接点+get(名称)来获得值或函数地址
# 查看名称空间
print(Student.__dict__)
# {'__module__': '__main__', 'school_name': '清华大学', 'choice_course': <function Student.choice_course at 0x0000024179E670D0>, '__dict__': <attribute '__dict__' of 'Student' objects>, '__weakref__': <attribute '__weakref__' of 'Student' objects>, '__doc__': None}
print(Student.__dict__.get('school_name'))
# 清华大学
print(Student.__dict__.get('choice_course'))
# <function Student.choice_course at 0x0000024179E670D0>
2.类和对象访问数据或者功能
在面向对象中,类和对象访问数据或者功能,可以统一采用句点符。
print(Student.school_name)
# 清华大学
print(Student.choice_course)
# <function Student.choice_course at 0x0000024602B770D0>
3.产生对象和查看\修改对象中的内容
类名加括号就会产生对象,并且每执行一次都会产生一个全新的对象。
obj1 = Student()
变量名obj1接收类名加括号之后的返回值(结果)是产生一个新的对象,这里会产生三个不同对象。
obj2 = Student()
obj3 = Student()
print(obj1, obj2, obj3)
# <__main__.Student object at 0x0000020A848A4A60> <__main__.Student object at 0x0000020A848DF100> <__main__.Student object at 0x0000020A848DF2E0>
print(obj1.__dict__)
对象自己目前什么都没有
# {}
print(obj2.__dict__)
# {}
print(obj3.__dict__)
# {}
通过点+名称的方式修改类中的值
print(obj1.school_name)
# 清华大学
print(obj2.school_name)
# 清华大学
print(obj3.school_name)
# 清华大学
Student.school_name = '家里蹲大学'
print(obj1.school_name)
# 家里蹲大学
print(obj2.school_name)
# 家里蹲大学
print(obj3.school_name)
# 家里蹲大学
ps:数据和功能,也可以统称为属性
数据>>>属性名
功能>>>:方法
六、对象独有的数据推导流程
class Student:
# 对象公共的数据
school_name = '清华大学'
# 对象公共的功能
def choice_course(self):
print('学生选课功能')
obj1 = Student()
obj2 = Student()
推导流程1:每个对象手动添加独有的数据
添加方式跟字典新增键值对类似
print(obj1.__dict__)
# {} 手动加入独有数据前
obj1.__dict__['name'] = 'jason'
obj1.__dict__['age'] = 18
obj1.__dict__['hobby'] = 'study'
print(obj1.__dict__)
# {'name': 'jason', 'age': 18, 'hobby': 'study'}
print(obj1.name)
# jason
print(obj1.age)
# 18
print(obj1.hobby)
# study
print(obj2.__dict__)
# {}
obj2.__dict__['name'] = 'kevin'
obj2.__dict__['age'] = 28
obj2.__dict__['hobby'] = 'music'
print(obj2.__dict__)
# {'name': 'kevin', 'age': 28, 'hobby': 'music'}
print(obj2.name)
# kevin
print(obj2.age)
# 28
print(obj2.hobby)
# music
推导流程2:将添加对象独有数据的代码封装成函数
def init(obj, name, age, hobby):
obj.__dict__['name'] = name
obj.__dict__['age'] = age
obj.__dict__['hobby'] = hobby
stu1 = Student()
stu2 = Student()
生成两个对象
init(stu1, 'jason', 18, 'music')
init(stu2, 'kevin', 29, 'read')
添加独有数据
print(stu1.__dict__)
# {'name': 'jason', 'age': 18, 'hobby': 'music'}
print(stu2.__dict__)
# {'name': 'kevin', 'age': 29, 'hobby': 'read'}
推导流程3:给学生对象添加独有数据的函数只有学生对象有资格调用
这里就是人狗大战中限制调用的那一步
class Student:
# 对象公共的数据
school_name = '清华大学'
# 专门给学生添加独有数据的功能
def init(obj, name, age, hobby):
obj.__dict__['name'] = name
obj.__dict__['age'] = age
obj.__dict__['hobby'] = hobby
# 对象公共的功能
def choice_course(self):
print('学生选课功能')
创建对象谈价独有数据
stu1 = Student()
Student.init(stu1, 'jason', 18, 'music')
stu2 = Student()
Student.init(stu2, 'kevin', 29, 'read')
print(stu1.__dict__, stu2.__dict__)
# {'name': 'jason', 'age': 18, 'hobby': 'music'} {'name': 'kevin', 'age': 29, 'hobby': 'read'}
stu1.choice_course()
# 学生选课功能
推导步骤4:init方法变形
这里其实没什么变化,就是把init变成了双下init然后查看调用的时候需要几个参数。
class Student:
# 对象公共的数据
school_name = '清华大学'
# 专门给学生添加独有数据的功能 类产生对象的过程中自动触发
def __init__(obj, name, age, hobby):
obj.__dict__['name'] = name
obj.__dict__['age'] = age
obj.__dict__['hobby'] = hobby
# 对象公共的功能
def choice_course(self):
print('学生选课功能')
stu1 = Student('jason', 18, 'read')
print(stu1.__dict__)
# {'name': 'jason', 'age': 18, 'hobby': 'read'}
print(stu1.name)
# jason
print(stu1.school_name)
# 清华大学
我们不难发现,现在这个状况下调用类创建对象只需要三个参数了,并且不需要先创建对象了。其实双下init的作用就是在你调用类方法的时候会自动把当前对象当作第一个参数传进来,让你节省了一步。
推导步骤5:变量名修改
class Student:
# 对象公共的数据
school_name = '清华大学'
# 专门给学生添加独有数据的功能 类产生对象的过程中自动触发
def __init__(self, name, age, hobby):
self.name = name # self.__dict__['name'] = name
self.age = age
self.hobby = hobby
# 对象公共的功能
def choice_course(self):
print('学生选课功能')
stu1 = Student('jason', 18, 'read')
print(stu1.name)
# jason
print(stu1.school_name)
# 清华大学
因为上面把init变成双下init之后就不需要传第一个参数确定方法执行对象了,因此python这边是建议我们使用self来充当这里的参数名称,当然了,其他名字也是一样的效果。
七、对象独有的功能推导流程
所谓功能,其实就是具有一定功能的函数,把这个函数变成对象独有的。
class Student:
# 对象公共的数据
school_name = '清华大学'
# 专门给学生添加独有数据的功能 类产生对象的过程中自动触发
def __init__(self, name, age, hobby):
self.name = name # self.__dict__['name'] = name
self.age = age
self.hobby = hobby
# 对象公共的功能
def choice_course(self):
print(f'学生{self.name}正在选课')
stu1 = Student('jason', 18, 'music')
stu2 = Student('kevin', 28, 'read')
1.直接在全局定义功能
直接在全局定义功能,但是该函数就不是学生对象独有的了。
def eat():
print('吃东西')
stu1.eat = eat
print(stu1.__dict__)
# {'name': 'jason', 'age': 18, 'hobby': 'music', 'eat': <function eat at 0x000001DCB291A4C0>}
stu1.eat()
# 吃东西
2.把功能定义在类中
定义在类中的功能,默认就是绑定给对象使用的,谁来调谁就是主人公
# Student.choice_course(123) # 类调用需要自己传参数
# choice_course(stu1) 对象调用会自动将对象当做第一个参数传入
stu1.choice_course()
stu1.choice_course()
stu2.choice_course()
# 学生jason正在选课
# 学生jason正在选课
# 学生kevin正在选课
# 对象修改数据值
stu1.name = 'tony' # 当点的名字已经存在的情况下 则修改对应的值
# 对象新增数据值
stu1.pwd = 123 # 当点的名字不存在的情况下 则新增数据
print(stu1.__dict__)
# {'name': 'tony', 'age': 18, 'hobby': 'music', 'pwd': 123}

