模块与包:包的具体使用、编程思想的转变、软件开发目录规范、常用内置模块之collections模块、时间模块、随机数模块等
一、包的具体使用
1、当我们使用包来导入模块的时候需要注意在python2和3中双下滑线init.py的需求不一样,但是为了兼容性考虑我们也应该把双下划线init.py加上去。
2、当我们在导入模块的时候,如果只需要包中的几个模块,可以用from的形式来导入指定模块
3、在使用import方式导入模块的时候需要注意,这里并不是一次性导入所有的包中的模块,而是导入双下划线init文件,在文件内有模块的名称就可以通过:包.模块名的形式调用模块中的名称
二、编程思想的转变
在我们从开始学习到目前为止,编程思想经历了三个阶段:
1、面条版阶段
也就是刚学完流程控制的时候的代码,全部内容都需要一一细分,详细编写,这个阶段并没有持续很久。
2、函数版阶段
当我们学习了函数后我们知道了把功能类似的代码整合成函数,需要使用的时候统一调用就可以实现同样的功能。
3、模块阶段
也就是到昨天为止,我们根据不同的作用,把功能相似的代码整合到一个模块中,在使用的时候导入模块就一样可以实现功能。
这三个阶段可以用我们管理电脑上的文件来进行类比记忆,当我们在使用第一个阶段的时候,就相当于我们把所有常用的文件都放在桌面,第二个阶段就相当于我们对文件进行了分类整理,第三个阶段就相当于我们在分类的基础上进行了优化提高了资源管理效率,把桌面的文件分散到其他盘中。
三、软件开发目录规范
根据上面的编程思想,我们了解到在使用第三类思想进行编程的时候需要根据功能进行详细分类,虽然在开发的时候名称不一样,但是基本思想一致,因此产生了软件开发目录规范:
1、bin目录
内部存放程序的执行文件,文件名称可以是start.py
2、conf目录
内部存放配置文件,比如我们的桌面上的一些设置就是存在对应的配置文件中的,文件名称一般是settings.py
3、core目录
内部存放核心功能的代码,文件名称一般是src.py
虽然说是存放核心功能,但是并不意味着主体功能就需要放在这里,可以放到下面的interface目录
4、lib目录
内部存放一些公共功能的代码文件,文件名称一般是common.py
5、db目录
用于存储数据文件,比如之前编写的员工信息管理系统,我们可以把员工信息的txt文件放到这个目录下
6、interface目录
内部存放端口文件,上面说了,核心功能的文件写在core目录中,但是主体功能是从interface目录下的代码中调用过去的。需要根据具体的业务逻辑划分对应的文件,通常的命名是goods.py等见名知意的名字
7、log目录
这里是日志目录
内部文件就是记录一下平时我们的操作记录
文件名一般是log.log
8、readme文件
通常是一个文本文件用于说明项目相关信息
9、requirements.txt文件
内部存项目所需要的模块以及版本信息
四、常用内置模块
因为功能相似的代码会被归类到一个py文件中,因此我们需要了解一些常用内置模块的功能。
1、collections模块
提供了除基础数据类型外的一些数据类型
1.具名元组:namedtuple
调用语句如下:
from collections import namedtuple
这个数据类型的作用是生成一个可以用名称来访问元素内容的元组,然后我们可以根据数据的名称返回对应的信息。
from collections import namedtuple
# 表示二维坐标系
point = namedtuple('点', ['x', 'y'])
# 生成点信息
p1 = point(1, 2)
print(p1) # 点(x=1, y=2)
print(p1.x) # 1
print(p1.y) # 2
card = namedtuple('扑克牌', ['num', 'color'])
c1 = card('A', '黑♠')
c2 = card('A', '红♥')
print(c1, c1.num, c1.color) # 扑克牌(num='A', color='黑♠') A 黑♠
print(c2, c2.num, c2.color) # 扑克牌(num='A', color='红♥') A 红♥
2.双向列表:deque
使用list存储数据时,按索引访问元素很快,但是插入和删除元素就很慢了,因为list是线性存储,数据量大的时候,插入和删除效率很低。
deque是为了高效实现插入和删除操作的双向列表,适合用于队列和栈:
队列:先进先出
栈:后进先出,也就是先进后出
from collections import deque
q = deque(['a', 'b', 'c'])
q.append('x')
# 往后面插入数据值,跟列表一样
q.appendleft('y')
# 从前面直接插入数据值
print(q)
# deque(['y', 'a', 'b', 'c', 'x'])
deque除了实现list的append和pop()外,还支持appendleft()和popleft(),这样就可以非常高效地往头部添加或删除元素。
拓展:
队列
1、队列是一种特殊的线性表,特殊之处在于它只允许在表的前端(front)进行删除操作,而在表的后端(rear)进行插入操作,和栈一样,队列是一种操作受限制的线性表。进行插入操作的端称为队尾,进行删除操作的端称为队头。
栈(stack):
1、栈(stack)又名堆栈,它是一种运算受限的线性表。其限制是仅允许在表的一端进行插入和删除运算。这一端被称为栈顶,相对地,把另一端称为栈底,栈就相当于一个有底的水桶,出栈的过程就像倒出水的过程,是先进后出。
2、栈(Stack)是操作系统在建立某个进程或者线程时(在支持多线程的操作系统中是线程)为这个线程建立的存储区域。
堆(Heap):
1、堆是在程序运行时,而不是在程序编译时,请求操作系统分配给自己某个大小的内存空间。即动态分配内存,对其访问和对一般内存的访问没有区别。
2、堆是指程序运行时申请的动态内存,而栈只是指一种使用堆的方法(即先进后出)。栈是先进后出的,但是于堆而言却没有这个特性,两者都是存放临时数据的地方。 对于堆,我们可以随心所欲的进行增加变量和删除变量,不要遵循什么次序,只要你喜欢。
堆、栈、队列之间的区别是?
1、堆是在程序运行时,而不是在程序编译时,申请某个大小的内存空间。即动态分配内存,对其访问和对一般内存的访问没有区别。
2、栈就是一个桶,后放进去的先拿出来,它下面本来有的东西要等它出来之后才能出来。(后进先出)
3、队列只能在队头做删除操作,在队尾做插入操作.而栈只能在栈顶做插入和删除操作。(先进先出)
3.有序字典:OrderedDict
使用dict时,Key是无序的。在对dict做迭代时,我们无法确定Key的顺序。
如果要保持Key的顺序,可以用OrderedDict:
from collections import OrderedDict
d = dict([('a', 1), ('b', 2), ('c', 3)])
print(d)
# {'a': 1, 'c': 3, 'b': 2}
od = OrderedDict([('a', 1), ('b', 2), ('c', 3)])
print(od)
# OrderedDict([('a', 1), ('b', 2), ('c', 3)])
注意,OrderedDict的Key会按照插入的顺序排列,不是Key本身排序:
od = OrderedDict()
od['z'] = 1
od['y'] = 2
od['x'] = 3
print(od.keys()) # 按照插入的Key的顺序返回
# odict_keys(['z', 'y', 'x'])
4.字典集合:ChainMap()
可以将多个字典集合到一个字典中去,对外提供一个统一的视图。注意:该操作并是不将所有字典做了一次拷贝,实际上是在多个字典的上层又进行了一次封装而已。
from collections import ChainMap
user1 = {"name": "admin", "age": "20"}
user2 = {"name": "root", "weight": 65}
users = ChainMap(user1, user2)
print(users.maps)
users.maps[0]["name"] = "tiger"
print(users.maps)
for key, value in users.items():
print(key, value)
# 输出如下
# [{'name': 'admin', 'age': '20'}, {'name': 'root', 'weight': 65}]
# [{'name': 'tiger', 'age': '20'}, {'name': 'root', 'weight': 65}]
# name tiger
# weight 65
# age 20
由此可见,如果 ChainMap() 中的多个字典有重复 key,查看的时候可以看到所有的 key,但遍历的时候却只会遍历 key 第一次出现的位置,其余的忽略。同时,我们可以通过返回的新的视图来更新原来的的字典数据。进一步验证了该操作不是做的拷贝,而是直接指向原字典。
5.当 key 不存在时返回默认值:defaultdict
from collections import defaultdict
default_dict = defaultdict(int)
default_dict["x"] = 10
print(default_dict["x"])
print(default_dict["y"])
# 这里的y可以看到没有添加进去
# 输出如下
# 10
# 0
注意,defaultdict 的参数必须是可操作的。比如 python 内置类型,或者无参的可调用的函数。
def getUserInfo():
return {
"name" : "",
"age" : 0
}
default_dict = defaultdict(getUserInfo)
admin = default_dict["admin"]
print(admin)
admin["age"] = 34
print(admin)
# 输出如下
# {'name': '', 'age': 0}
# {'name': '', 'age': 34}
6.可以重新排序的字典:OrderedDict
- OrderedDict 类有一个 move_to_end() 方法,可以有效地将元素移动到任一端。
from collections import OrderedDict
user = OrderedDict()
user["name"] = "admin"
user["age"] = 23
user["weight"] = 65
print(user)
user.move_to_end("name") # 将元素移动至末尾
print(user)
user.move_to_end("name", last = False) # 将元素移动至开头
print(user)
# 输出如下
# OrderedDict([('name', 'admin'), ('age', 23), ('weight', 65)])
# OrderedDict([('age', 23), ('weight', 65), ('name', 'admin')])
# OrderedDict([('name', 'admin'), ('age', 23), ('weight', 65)])
7.计数器:Counter
Counter 可以简单理解为一个计数器,可以统计每个元素出现的次数,同样 Counter() 是需要接受一个可迭代的对象的。
from collections import Counter
animals = ["cat", "dog", "cat", "bird", "horse", "tiger", "horse", "cat"]
animals_counter = Counter(animals)
print(animals_counter)
print(animals_counter.most_common(2))
Counter({'cat': 3, 'horse': 2, 'dog': 1, 'bird': 1, 'tiger': 1})
# 输出如下
# Counter({'cat': 3, 'horse': 2, 'dog': 1, 'bird': 1, 'tiger': 1})
# [('cat', 3), ('horse', 2)]
其实一个 Counter 就是一个字典,其额外提供的 most_common() 函数通常用于求 Top k 问题。
2、时间模块
这个模块我们就比较熟悉了,之前学的时候调用过内部的几个功能
三种时间表现形式
1.时间戳(timestamp)
返回秒数。通常来说,时间戳表示的是从1970年1月1日00:00:00开始按秒计算的偏移量。我们运行“type(time.time())”,返回的是float类型。
2.结构化时间(struct_time)
主要是给计算机看的,人看不适应,但是根据中间的单词意思也可以看懂
这里需要注意,因为外国的日期和星期跟我们不太一样,我们需要根据具体情况修改。
3.格式化时间(Format String)
主要是给人看的,通过一定的符号表示对应的年月日时分秒
代码演示:
#导入时间模块
import time
#时间戳
print(time.time())
# 结果:1666168973.8717413
#时间字符串
print(time.strftime("%Y-%m-%d %X"))
# 结果:2022-10-19 16:42:53
print(time.strftime("%Y-%m-%d %H-%M-%S"))
# 前面三个表示日期的%字符可以用%+小写的x表示,后面三个表示时间的%字符可以用大写的X表示
# 结果:2022-10-19 16-42-53
#时间元组:localtime将一个时间戳转换为当前时区的struct_time
print(time.localtime())
# 结果:time.struct_time(tm_year=2022, tm_mon=10, tm_mday=19, tm_hour=16, tm_min=42, tm_sec=53, tm_wday=2, tm_yday=292, tm_isdst=0)
拓展1:
格式化时间中,各个符号代表的意思:
%y 两位数的年份表示(00-99)
%Y 四位数的年份表示(000-9999)
%m 月份(01-12)
%d 月内中的一天(0-31)
%H 24小时制小时数(0-23)
%I 12小时制小时数(01-12)
%M 分钟数(00=59)
%S 秒(00-59)
%a 本地简化星期名称
%A 本地完整星期名称
%b 本地简化的月份名称
%B 本地完整的月份名称
%c 本地相应的日期表示和时间表示
%j 年内的一天(001-366)
%p 本地A.M.或P.M.的等价符
%U 一年中的星期数(00-53)星期天为星期的开始
%w 星期(0-6),星期天为星期的开始
%W 一年中的星期数(00-53)星期一为星期的开始
%x 本地相应的日期表示
%X 本地相应的时间表示
%Z 当前时区的名称
%% %号本身
拓展2:
struct_time元组共有9个元素共九个元素:(年,月,日,时,分,秒,一年中第几周,一年中第几天等)
| 索引(Index) | 属性(Attribute) | 值(Values) |
|---|---|---|
| 0 | tm_year(年) | 比如2011 |
| 1 | tm_mon(月) | 1 - 12 |
| 2 | tm_mday(日) | 1 - 31 |
| 3 | tm_hour(时) | 0 - 23 |
| 4 | tm_min(分) | 0 - 59 |
| 5 | tm_sec(秒) | 0 - 60 |
| 6 | tm_wday(weekday) | 0 - 6(0表示周一) |
| 7 | tm_yday(一年中的第几天) | 1 - 366 |
| 8 | tm_isdst(是否是夏令时) | 默认为0 |
几种时间格式的转换
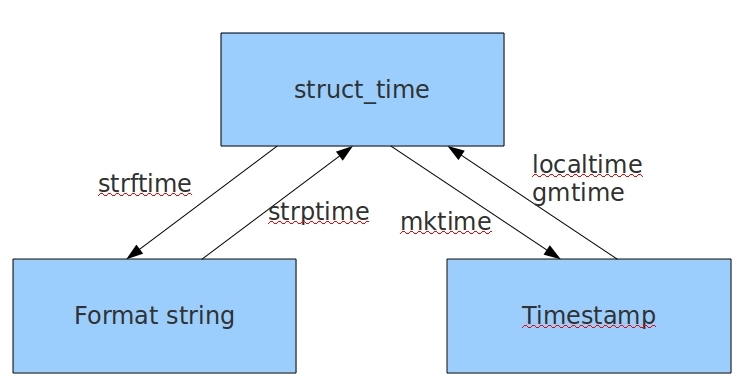
import time
#时间戳-->结构化时间
# time.gmtime(时间戳) # 根据UTC时间进行转换,与英国伦敦当地时间一致
# time.localtime(时间戳) # 根据当地时间进行转换。例如我们现在在北京执行这个方法:与UTC时间相差8小时,UTC时间+8小时 = 北京时间
print(time.gmtime(1500000000))
# 结果:time.struct_time(tm_year=2017, tm_mon=7, tm_mday=14, tm_hour=2, tm_min=40, tm_sec=0, tm_wday=4, tm_yday=195, tm_isdst=0)
print(time.localtime(1500000000))
# 结果:time.struct_time(tm_year=2017, tm_mon=7, tm_mday=14, tm_hour=10, tm_min=40, tm_sec=0, tm_wday=4, tm_yday=195, tm_isdst=0)
#结构化时间-->时间戳
#time.mktime(结构化时间)
time_tuple = time.localtime(1500000000)
print(time.mktime(time_tuple))
# 结果:1500000000.0
import time
#结构化时间-->字符串时间
#time.strftime("格式定义","结构化时间") 结构化时间参数若不传,则显示当前时间
print(time.strftime("%Y-%m-%d %X"))
# 结果:'2017-07-24 14:55:36'
print(time.strftime("%Y-%m-%d", time.localtime(1500000000)))
# 结果:'2017-07-14'
#字符串时间-->结构化时间
#time.strptime(时间字符串,字符串对应格式)
print(time.strptime("2017-03-16", "%Y-%m-%d"))
# 结果:time.struct_time(tm_year=2017, tm_mon=3, tm_mday=16, tm_hour=0, tm_min=0, tm_sec=0, tm_wday=3, tm_yday=75, tm_isdst=-1)
print(time.strptime("07/24/2017", "%m/%d/%Y"))
# 结果:time.struct_time(tm_year=2017, tm_mon=7, tm_mday=24, tm_hour=0, tm_min=0, tm_sec=0, tm_wday=0, tm_yday=205, tm_isdst=-1)
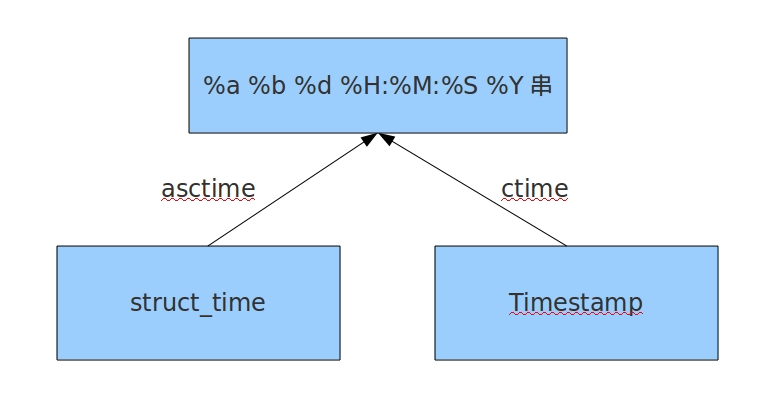
import time
#结构化时间 --> %a %b %d %H:%M:%S %Y串
#time.asctime(结构化时间) 如果不传参数,直接返回当前时间的格式化串
print(time.asctime(time.localtime(1500000000)))
# 结果'Fri Jul 14 10:40:00 2017'
print(time.asctime())
# 结果'Mon Jul 24 15:18:33 2017'
#时间戳 --> %a %b %d %H:%M:%S %Y串
#time.ctime(时间戳) 如果不传参数,直接返回当前时间的格式化串
print(time.ctime())
# 结果'Mon Jul 24 15:19:07 2017'
print(time.ctime(1500000000))
# 结果'Fri Jul 14 10:40:00 2017'
datetime模块
1.datetime.now() # 获取当前datetime
datetime.utcnow() # 获取当前格林威治时间
from datetime import datetime
#获取当前本地时间
a=datetime.now()
print('当前日期:',a)
#获取当前世界时间
b=datetime.utcnow()
print('世界时间:',b)
2.datetime(2017, 5, 23, 12, 20) # 用指定日期时间创建datetime
from datetime import datetime
#用指定日期创建
c=datetime(2017, 5, 23, 12, 20)
print('指定日期:',c)
3.将以下字符串转换成datetime类型:
'2017/9/30'
'2017年9月30日星期六'
'2017年9月30日星期六8时42分24秒'
'9/30/2017'
'9/30/2017 8:42:50 '
from datetime import datetime
d=datetime.strptime('2017/9/30','%Y/%m/%d')
print(d)
e=datetime.strptime('2017年9月30日星期六','%Y年%m月%d日星期六')
print(e)
f=datetime.strptime('2017年9月30日星期六8时42分24秒','%Y年%m月%d日星期六%H时%M分%S秒')
print(f)
g=datetime.strptime('9/30/2017','%m/%d/%Y')
print(g)
h=datetime.strptime('9/30/2017 8:42:50 ','%m/%d/%Y %H:%M:%S ')
print(h)
4.将以下datetime类型转换成字符串:
2017年9月28日星期4,10时3分43秒
Saturday, September 30, 2017
9/30/2017 9:22:17 AM
September 30, 2017
from datetime import datetime
i=datetime(2017,9,28,10,3,43)
print(i.strftime('%Y年%m月%d日%A,%H时%M分%S秒'))
j=datetime(2017,9,30,10,3,43)
print(j.strftime('%A,%B %d,%Y'))
k=datetime(2017,9,30,9,22,17)
print(k.strftime('%m/%d/%Y %I:%M:%S%p'))
l=datetime(2017,9,30)
print(l.strftime('%B %d,%Y'))
5.用系统时间输出以下字符串:
今天是2017年9月30日
今天是这周的第?天
今天是今年的第?天
今周是今年的第?周
今天是当月的第?天
from datetime import datetime
#获取当前系统时间
m=datetime.now()
print(m.strftime('今天是%Y年%m月%d日'))
print(m.strftime('今天是这周的第%w天'))
print(m.strftime('今天是今年的第%j天'))
print(m.strftime('今周是今年的第%W周'))
print(m.strftime('今天是当月的第%d天'))
3、随机数模块:random
功能简介:
import random
# 随机小数
print(random.random())
# 大于0且小于1之间的小数
# 0.7664338663654585
print(random.uniform(1, 3))
# 大于1小于3的小数
# 1.6270147180533838#恒富:发红包
# 随机整数
print(random.randint(1, 5))
print(random.randrange(1, 10, 2))
# 随机选择一个返回
print(random.choice([1, '23', [4, 5]]))
print(random.choices([1, '23', [4, 5]]))
# choices返回的不是字符了,返回的是保留原来数据类型的数据值
# 随机选择多个返回,返回的个数为函数的第二个参数
print(random.sample([1, '23', [4, 5]], 2))
# [[4, 5], '23']
# 打乱列表顺序
item = [1, 3, 5, 7, 9]
random.shuffle(item) # 打乱次序
print(item)
# [5, 1, 3, 7, 9]
random.shuffle(item)
print(item)
# [5, 9, 7, 1, 3]
产生图片验证码(搜狗面试题):
每一位都可以是大写字母 小写字母 数字 n位
import random
def suijishu(n):
res = ''
for i in range(n):
wd_d = chr(random.randint(65, 90))
wd = chr(random.randint(97, 122))
num = str(random.randint(0, 9))
choice = random.choice([wd, wd_d, num])
res = res + choice
print(res)
suijishu(5)

