模块与包:索引取值与迭代取值的差异、模块简介、模块的分类、导入模块的两种句式、导入模块补充说明、循环导入问题、判断文件类型、模块的查找顺序、绝对导入与相对导入、
一、索引取值和迭代取值的差异
这里是对昨天的内容进行一个小补充,对比了索引取值和迭代取值的区别:
索引取值
索引取值可以根据索引在任何为此任意次的取值,但是不能对无序的数据类型取值。
迭代取值
可以对无序的数据类型取值也可以对有序的数据类型取值,但是只能根据前后的顺序取一遍数据值,不能后退。
二、模块
1、简介
1.模块的本质
模块就是一个内部具有一定功能(功能无论大小)的py文件
如果把开发程序比喻成制造一台电脑,编写模块就像是在制造电脑的零部件,准备好零部件后,剩下的工作就是按照逻辑把它们组装到一起。
2.模块的历史
根据模块的本质我们可以知道,当我们实现一些复杂的功能的时候,直接调用别人的模块就可以实现目的,因此在最开始的时候其他程序员都看不起python,给他起名:调包侠。
但是随着时间的发展,代码的功能变得越来越复杂了,项目的要求变得越来越繁琐,之前看不起python的人也开始使用python成为了调包侠,最终逃不过一个真香定律。
所以总结下来,使用模块既保证了代码的重用性,又增强了程序的结构性和可维护性。另外除了自定义模块外,我们还可以导入使用内置或第三方模块提供的现成功能,这种“拿来主义”极大地提高了程序员的开发效率。
3.python模块的多种表现形式
这里了解就可以,方便后面的理解
1、py文件(一个py文件也可以看成一个模块)
2、含有多个py文件的文件夹(通常在存储的时候会根据功能来存放,比如功能相似的放在一起)
3、已被编译为共享库或DLL的c或c++扩展(了解一下就好)
4、使用C编写并链接到python解释器的内置模块(了解一下就好)
2、模块的分类
所谓的模块分类我们可以看成模块的来源,这里我们把模块分成三类来源:
1.自定义模块
自定义模块就是我们程序员自己编写的模块文件
2.内置模块
这些模块是python解释器自带的模块
3.第三方模块
这些就是一些大佬写的模块文件
3、导入模块的两种语法格式
在介绍之前需要强调一些注意事项:
①在导入模块的时候一定要分清楚谁是被执行文件,谁是被导入文件。
②在编写模块的时候需要注意,文件的名称需要是纯英文(被执行文件我们可能会出现中文,但是模块文件不行)。
③当我们导入模块的时候,文件末尾的后缀不需要写(.py),文件名为xxx.py模块名则是xxx
1.import 模块名
比如我们定义了一个py文件当模块:a.py
然后调用的代码如下:
import a
这种形式下会直接运行调用模块的文件内部的所有代码,之后我们就可以通过:模块名.变量名的形式来调用模块的函数或变量。
2.from 名称 import 名称
这里也用a.py当模块文件
调用代码如下:
from a import 函数名(或是变量名)
这种形式下调用模块内的名称比较自由,可以掉几个也可以调用所有的名称,但是在我们调用的时候容易跟执行文件内的名称产生冲突,导致引用的时候导致同一变量绑定的值错误切换。
from a import *
默认是将模块名称空间中所有的名字导入
但是相应的,我们也可以用双下划线all来限制获取的名字,只是只能作用于from和*号的组合,使用import语句不受影响
__all__ = ['名字1', '名字2'] 针对*可以限制拿的名字
3.执行流程
这里我们运用代码举例进行讲解
import模式
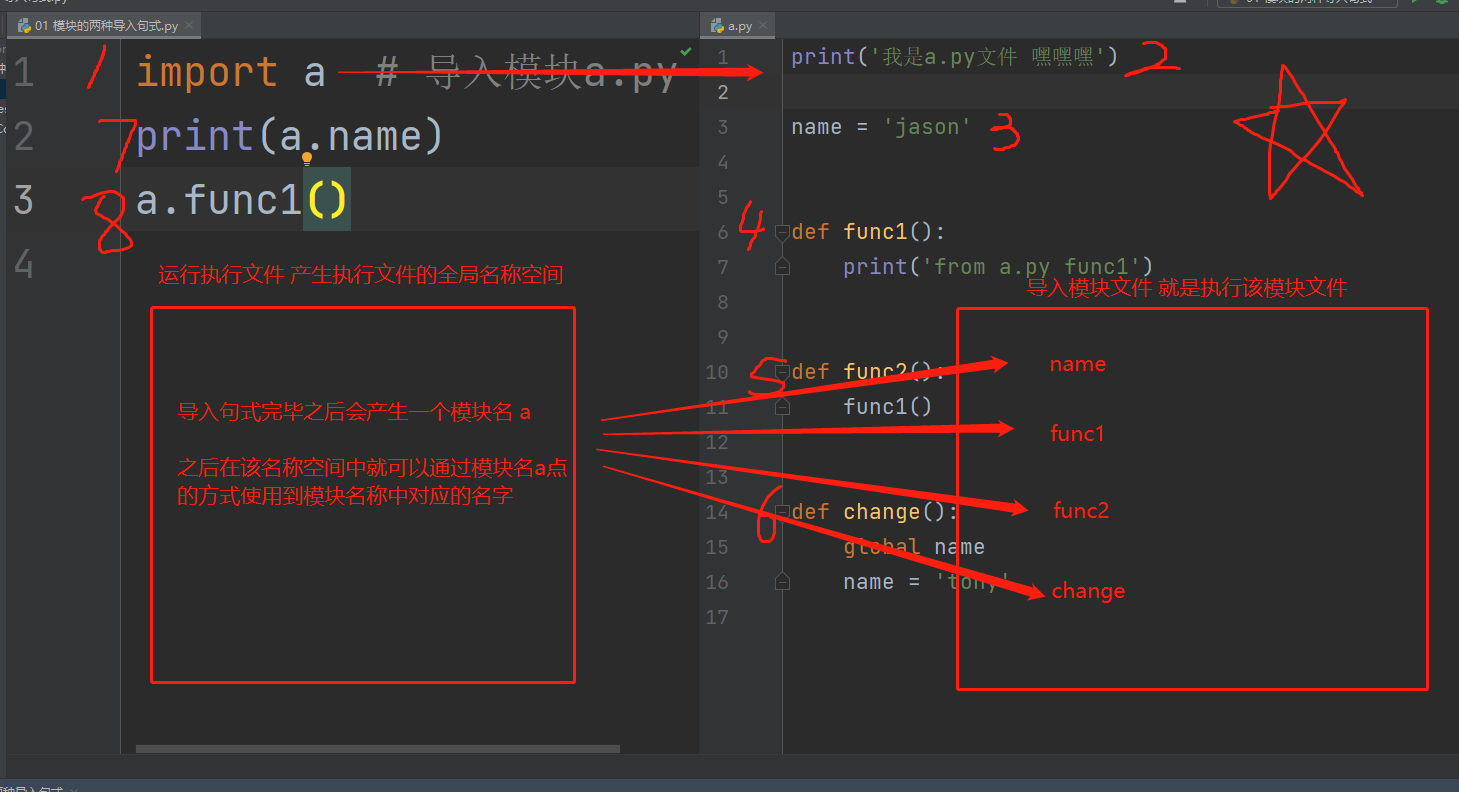
通过上面代码我们可以发现左边是执行文件右边的a.py是被导入的模块文件,执行文件运行的时候运行流程和名称空间的变化如下:
①这个时候先是运行了py文件产生了一个全局名称空间
②然后运行a.py文件,就会在内存中创建一个模块a对应的名称空间,把a.py中的名称全部放到里面,执行文件内会产生一个模块a的名称,当我们调用a中的名称就会去a模块的名称空间中寻找。这里需要注意导入模块的时候内部代码全会执行一遍,比如print操作会打印文字。
③根据流程图我们可以看到导入模块之后打印了a模块中给的name绑定的jason,这里就想到雨
④之后调用了a中的函数func1
from...import...模式
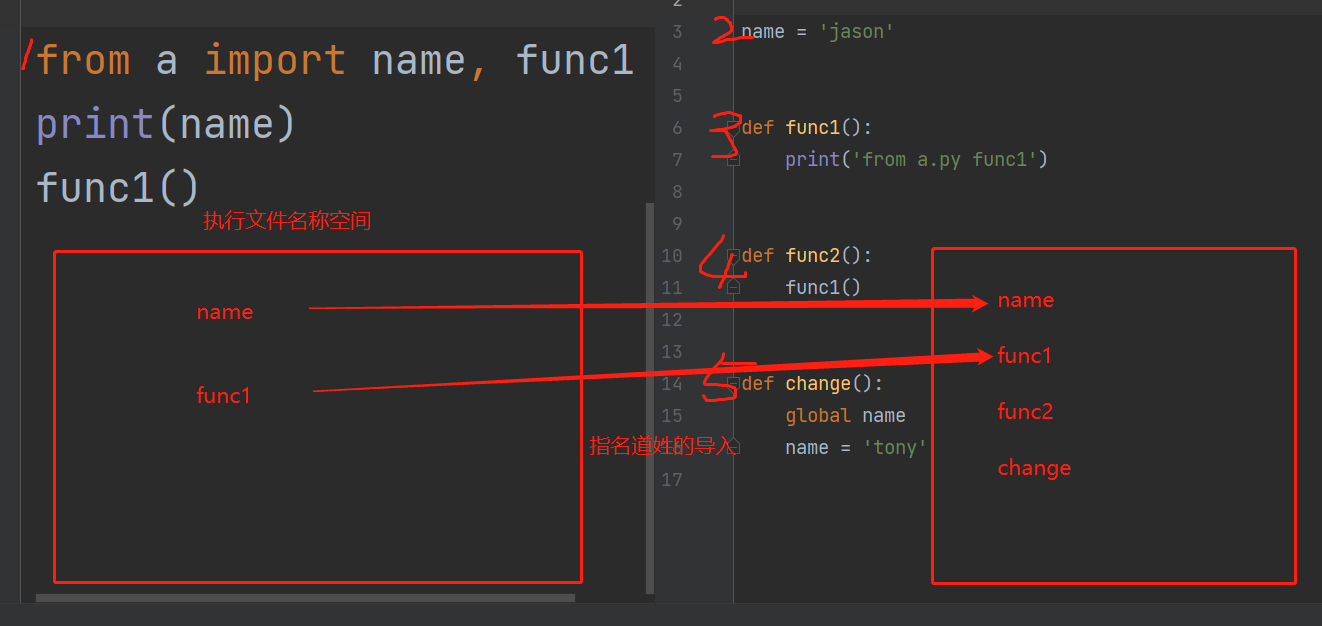
整体流程跟上面相似,在引用的时候名称有所区别
①这个时候先是运行了py文件产生了一个全局名称空间
②然后运行a.py文件,就会在内存中创建一个模块a对应的名称空间,把a.py中的名称全部放到里面,执行文件内会产生一个模块a的名称,当我们调用a中的名称就会去a模块的名称空间中寻找。这里需要注意导入模块的时候内部代码全会执行一遍,比如print操作会打印文字。
③根据流程图我们可以看到导入模块之后打印了a模块中给的name绑定的jason
④之后调用了a中的函数func1
特殊情况:
①当我们在使用from方式导入模块的之后,如果用相同的变量名绑定了其他数据值,就会把引入的模块中的值给定义,产生冲突(执行文件有个name绑定了jason,模块文件导入了一个name叫java,根据先后顺序,会留下后面那个值,前面那个值会顶替)
②from模式如果想要导入所有的变量名,可以在import后面把名称替换成一个'*'号
4、导入模块的补充说明
1.import与from...import...两者优缺点
import句式
①导入的时候可以一次性导入模块内的所有名称
②导入后调用方式是:模块名.变量名(或函数名),这导致我们在使用的时候不会跟执行文件内的名称产生冲突。
③但是相对的,调用的时候会变得繁琐
from...import...句式
①在调用的时候可以指定调用的名称,也可以一次导入所有的名称
②在使用导入的名称的时候可以直接使用名称来调用
③但是相对的,会跟执行文件内的同名变量或函数产生冲突,导致先出现的值被顶替
2.重复导入模块
在我们重复导入模块的时候,只会执行一次,后续的重复代码是无效的。第一次导入模块已经将其加载到内存空间了,之后的重复导入会直接引用内存中已存在的模块,不会重复执行文件,通过import sys,打印sys.modules的值可以看到内存中已经加载的模块名。
3.起别名
当我们导入模块的时候,可能会出现模块名或模块内的名称很长很复杂,我们可以通过as关键字起别名来简化调用代码:
import wuyongerciyuan as wy
from wuyongerciyuan import zhangzehonglovezhanghong as zz
from a import name as n,func1 as f1
4.涉及到多个模块导入
当我们想要一次性导入多个模块的时候,可以跟导入模块内的名称一样,用逗号隔开,一次导入多个模块,这里也需要注意,调用的时候如果功能相似,可以一次性导入,如果功能不同,建议分开导入:
import a
import wuyongerciyuan
如果模块功能相似度不高 推荐使用第一种 相似度高可以使用第二种
import a, wuyongerciyuan
但其实第一种形式更为规范,可读性更强,推荐使用,而且我们导入的模块中可能包含有python内置的模块、第三方的模块、自定义的模块,为了便于明显地区分它们,我们通常在文件的开头导入模块,并且分类导入,一类模块的导入与另外一类的导入用空行隔开,不同类别的导入顺序如下:
#1. python内置模块
#2. 第三方模块
#3. 程序员自定义模块
5、循环导入问题
循环导入就是两个py文件互相导入对方,但是这里我们可以根据上面写的知识点:牢记谁是执行文件,谁是模块文件,来进行简单的分析:
md1:
import md2
name = 'from md1'
print(md2.name)
md2
name = 'from md2'
import md1
print(md1.name)
这里简单说一下流程;
1.我们把md1文件当作执行文件执行之后直接跳到md2文件执行,进行导入模块操作
2.md2中执行到import md1后再次回到md1中执行后续内容(这里是当作导入模块的操作执行,不是正常的流程走下去),然后输出print(md2.name)一次
3.md1模块导入之后回到md2那边执行后续的代码,输出print(md1.name)
4.md2导入结束之后走md1中后面的代码print(md2.name)
注:这里md2文件中的import不能放在最上面,会导致md1中的print获取不到md2中的name直接报错
6、判断文件类型
这里需要引入一个函数:双下划线name
__name__
当我们运行代码的时候,如果双下划线name所在文件是被执行文件,那么就会返回双下划线main
__main__
如果双下划线name所在文件是被导入文件的时候就会返回被导入的模块名
应用场景
if __name__ == '__main__':
print('哈哈哈 我是执行文件 我可以运行这里的子代码')
当我们在编写模块的时候可以使用上面的if语句来测试模块,在if下写下调用内部函数的代码,这样在我们测试的时候就可以调用函数进行测试,但是在引用的时候就不会被调用。
7、模块的查找顺序
所谓的查找顺序就是在运行代码的时候调用的优先级,这里分成三个优先级:
1.内存
这里可以举一个极端一点的例子,就是我们引入一个模块,然后在引入代码后使用time.sleep停个十几秒,在停止的时间内我们直接把导入的模块文件删除,接下来继续让代码执行模块内的函数或引用变量名,我们会发现代码正常运行。但是结束后就不弄再次运行了。
2.内置模块
内置模块就是python解释器中的模块,当我们在编写模块的时候如果名称跟内置模块中的名称冲突了,就会导致代码直接调用内置模块中的内容。因此我们在编写模块的时候应该尽量避免名称冲突
3.执行文件所在的sys.path
所谓的sys.path就是系统的环境变量,跟我们装python解释器的时候的环境变量作用相似。
这里的sys是一个模块名称,我们可以使用下面的代码获得当前的系统环境变量:
import sys
print(sys.path)
# 得到的结果是个列表 ,内部是目前的环境变量路径
之后我们可以使用下面代码添加路径到系统环境变量中去(需要放在执行文件中),这样当我们导入模块的时候就不会因为模块文件不在同一目录导致报错:
sys.path.append(r'D:\pythonProject03\day17\mymd')
import ccc
print(ccc.name)
8、模块的绝对导入和相对导入
绝对导入
绝对导入就是导入模块的时候需要精确的使用文件的绝对路径:
from mymd.aaa.bbb.ccc.ddd import name # 可以精确到变量名
from mymd.aaa.bbb.ccc import ddd # 也可以精确到模块名
起始目录是项目文件的路径
相对导入
相对路径就是导入模块的时候以自身被执行文件所在位置为基础进行查找。
.在路径中表示当前目录
..在路径中表示上一层目录
..\..在路径中表示上上一层目录
不在依据执行文件所在的sys.path 而是以模块自身路径为准
from . import b
相对导入不能使用在被执行文件中,只能使用模块文件中。比如执行文件导入模块后,模块文件中导入了另一个模块,这个模块的路径要么使用绝对导入,要么使用相对导入的方式来导入。
注:由于相对导入的限制条件很多,导致了使用频率偏低,一般使用绝对导入即可。
9、包的概念
所谓包就是内部有多个py文件的文件夹,也就是多个py文件的集合。这里根据python2和3有所区别:
内部含有
__init__.py文件
的文件夹(python2必须要有 python3无所谓)就是包。在python3中加上双下划线init的文件夹会有一个小点出现在文件夹图标上。

