文件处理与函数基础:文件操作、文件读写模式、文件操作模式、文件诸多方法、文件内光标的移动、文件内光标移动案例(了解)、文件内容修改(了解)、函数
一、 文件内光标移动案例(了解)
昨天讲解了如何使文件内的光标移动,现在我们举一个更符合实际情况的例子。
import time
# 这里是用于调用时间模块,他会返回给我们一个时间戳,下面的代码是用于监控文件中是否有新的内容产生
with open(r'a.txt', 'rb') as f:
# 打开a文件,使用的是二进制模式
f.seek(0, 2)
# 把光标定位到文件的最末尾
while True:
# 开始不断的监控,一次往下读取一行
line = f.readline()
# 如果监控一次没有发现新的内容就暂时停止0.5秒,如果监控到了新的内容就把他打印出来
if len(line) == 0:
# 没有内容,停止0.5秒
time.sleep(0.5)
else:
# 监控到了新的内容,将其打印出来
print(line.decode('utf8'), end='')
二、计算机硬盘修改数据的原理(了解,为了文件内容修改作解释)
在计算机的存储设备中,经过发展,到目前为止出现了两种主流设备设备:机械硬盘和固态硬盘。固态硬盘是通过算法来存储数据值的,机械硬盘是通过在光盘上刻录数据的方式来达成存储数据的目的。而机械硬盘的存储数据的方式就跟我们通过代码操作文件进行修改内容的原理十分相似。当我们刚买来一个机械硬盘的时候,它的内部并没有写入数据,内部的光盘上是空的,当我们第一次保存文件进去的时候,就相当于往光盘上刻录我们的数据。当数据写满后,就相当于光盘上录满了内容,此时我们需要删除一些数据,但是当我们删除这些数据的时候并不表示这些数据已经永久删除了,他们只是从写满时候的占有态变成了自由态,这个时候只是不能被读写。如果我们使用恢复数据的软件进行恢复,就可以重新获得这些数据。但是当我们在这些数据变成自由态的时候,保存了其他数据,那么这些数据值就不存在了。
之后当我们对保存的文件进行修改的时候会出现两种情况,需要分别表述:
情况一:保存到其他地方
当我们的磁盘进行保存操作的时候,他并没有把这个文件保存在原本的位置,而是取消了原本文件的占有态,使他变成自由态,并在其他地方重新保存了一个跟原文件一样名称的修改后的文件。
特点:占用磁盘空间较多,但是节约内存资源。
情况二:保存到原来位置(覆盖)
当我们对磁盘进行保存操作的时候,系统把修改后的文件保存到了原来的位置。但是保存在这里的文件并不是原来的文件了,在我们看不到的地方计算机进行了一系列的操作:1、删除原本的文件,2、把修改后的文件保存到原来的磁盘位置中,3、给保存后的文件命名成原来的名字。
特点:节省磁盘空间。但是占用内存资源较多。
三、文件内容修改
之前我们所讲的文件的操作其实就是对于内容的修改,当我们使用代码完成修改后,跟我们平时使用软件不一样,不需要刻意进行保存,修改结束后就会自动保存。
在我们使用代码对文件内容进行修改的时候,计算机的处理逻辑跟机械磁盘的处理方式相似,也是两种保存方式:
方式一
修改完成后保存在原来的地方
# 修改文件内容的方式1:覆盖写
with open(r'a.txt', 'r', encoding='utf8') as f:
data = f.read()
with open(r'a.txt', 'w', encoding='utf8') as f1:
f1.write(data.replace('jason', 'tony'))
# 打开文件读取内容后替换jason为tony,并把替换后的内容覆盖到原来的文件中
方式二
删掉原来的文件,把内存中修改后的文件保存到其他地方命名成原来的名字
# 修改文件内容的方式2:换地写
'''先在另外一个地方写入内容 然后将源文件删除 将新文件命名成源文件'''
import os
# 调用了一个名叫os的方法库,方便后续使用内置方法操作
with open('a.txt', 'r', encoding='utf8') as read_f, open('.a.txt.swap', 'w', encoding='utf-8') as write_f:
for line in read_f:
write_f.write(line.replace('tony', 'kevinSB'))
# 从文件中读取内容然后遍历进行对比替换,并把替换后的内容写入到另一个文件中,最后我们会在另一个文件中得到修改后的结果
os.remove('a.txt') # 删除原来的文件
os.rename('.a.txt.swap', 'a.txt') # 把另一个文件命名成原来文件的名字,就当作把他替换了
四、函数
1、概念讲解
当我们在编写代码实现功能的时候,比如验证用户的登陆状态(确认用户的用户名和密码),一些情况下需要反复验证,这种时候就会反复套用一段一样的代码来检验。仔细想想这些地方其实进行了重复操作,因此我们引入了函数进行简化。这就相当于一个工人去干活,在最初的时候需要一次次的制造工具再去干活,后来他发现这挺蠢的。就做了工具之后保存好,每次干活的时候拿出来使用一下就可以快速完成工作了。
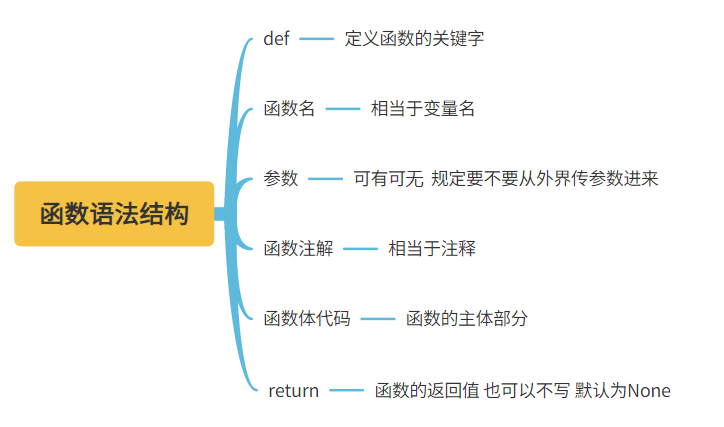
2、语法结构
def 函数名(参数(可以有多个,后续会讲):
'''函数注释(解释函数功能)'''
函数体代码
return 返回值
1.def
定义函数的关键字
2.函数名
命名等同于变量名,这里我们需要尽量做到见名知意,方便在使用的时候理解它的作用
3.参数
可有可无,主要是在使用函数的时候规定要不要外界传数据进来
4.函数注释
类似于工具说明书
5.函数体代码
是整个函数的核心,主要取决于程序员的编写
6.return
使用函数之后可以返回给使用者的数据,可有可无。
当我们给返回值的时候可以写多个,甚至是不同数据类型的多个数据值,他们会被封装到一个元组中一次性输出
当我们使用return的时候,意味着函数运行到这里就停止了,如果下方还有代码将不会运行。
当我们使用return的时候,意味着函数运行到这里就停止了,如果下方还有代码将不会运行。
3、函数的定义与调用
1.函数在定义阶段只检测语法,不执行代码。通常在编写代码的时候我们先定义这个函数然后用pass完善结构,这个状态下的函数也叫做空函数。等到需要填入内容的时候再填入内容替换pass。
def func():
pass
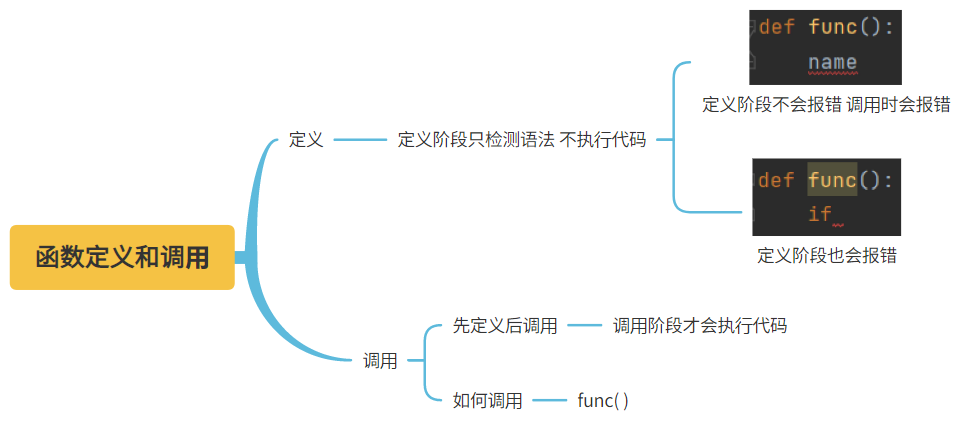
2.函数在调用阶段才会执行函数体代码
func()
3.函数必须先定义后调用,如果不定义就先调用会报错
4.函数定义使用关键字def
5.函数调用使用>>>:函数名加括号
如果有参数则需要在括号内按照相应的规则传递参数(后续详细讲解)
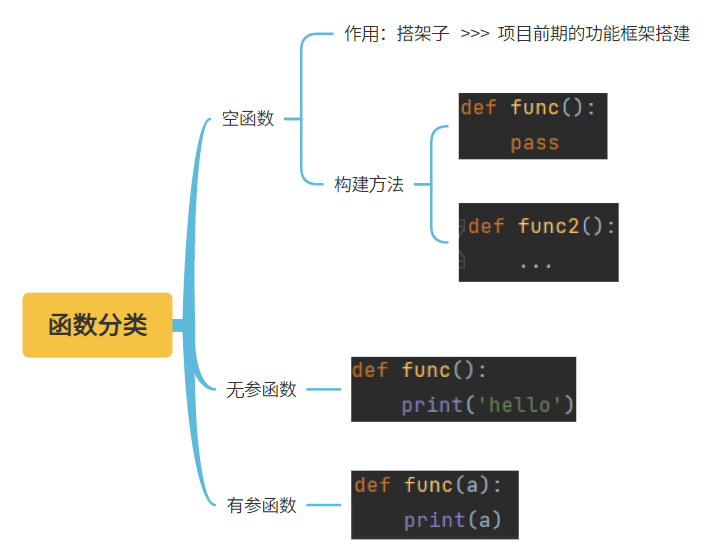
4、函数的分类
1.空函数
函数体代码为空 使用的pass或者...补全的
空函数主要用于项目前期的功能框架搭建
def register():
"""注册功能"""
pass
2.无参函数
定义函数的时候括号内没有参数
def index():
print('from index function')
3.有参函数
定义函数的时候括号内写参数 调用函数的时候括号传参数
def func(a):
print(a)
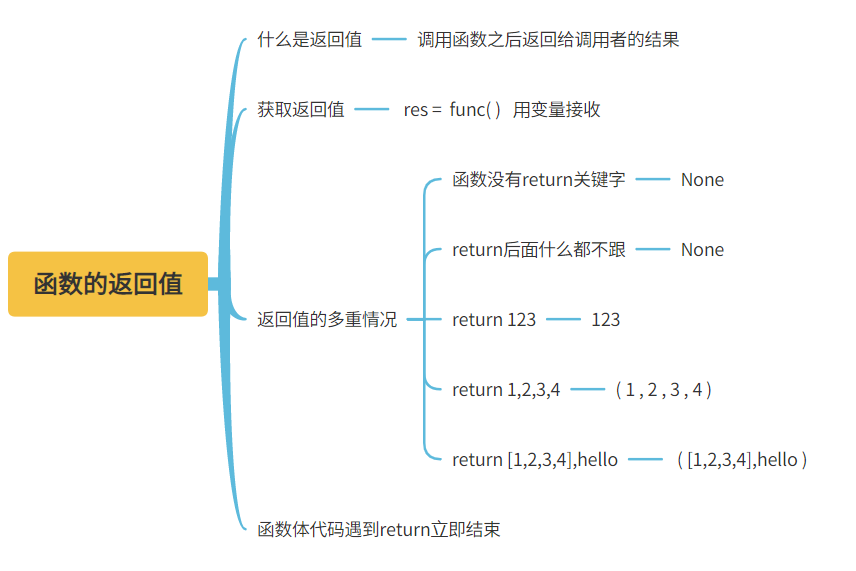
5、函数的返回值
1.什么是返回值
调用函数之后返回给调用者的结果
2.如何获取返回值
变量名 赋值符号 函数的调用
res = func() # 先执行func函数 然后将返回值赋值给变量res
3.函数返回值的多种情况
3.1.函数体代码中没有return关键字 默认返回None
3.2.函数体代码有return 如果后面没有写任何东西还是返回None
3.3.函数体代码有return 后面写什么就返回什么
3.4.函数体代码有return并且后面有多个数据值 则自动组织成元组返回
3.5.函数体代码遇到return会立刻结束
6、函数的参数
形式参数 在函数定义阶段括号内填写的参数 简称'形参' 实际参数 在函数调用阶段括号内填写的参数 简称'实参' ++++++++++++++++++++++++++++++++++++++++++++++++++++++++++ """ 形参与实参的关系 形参类似于变量名 在函数定义阶段可以随便写 最好见名知意 def register(name,pwd): pass 实参类似于数据值 在函数调用阶段与形参临时绑定 函数运行结束立刻断开 register('jason',123) 形参name与jason绑定 形参pwd与123绑定 """ ++++++++++++++++++++++++++++++++++++++++++++++++++++++++++

作业详解
1.编写简易版本的拷贝工具
自己输入想要拷贝的数据路径 自己输入拷贝到哪个地方的目标路径
任何类型数据皆可拷贝
ps:个别电脑C盘文件由于权限问题可能无法拷贝 换其他盘尝试即可
1.获取想要拷贝的文件路径
source_file_path = input('请输入您想要拷贝的文件路径>>>:').strip()
2.获取目标文件的路径
target_file_path = input('请输入您想要拷贝到哪个地方的路径>>>:').strip()
3.打开第一个文件路径 读取内容写入第二个文件路径中
with open(r'%s' % source_file_path, 'rb') as read_f, open(r'%s' % target_file_path, 'wb') as write_f:
for line in read_f:
write_f.write(line)
2.利用文件充当数据库编写用户登录、注册功能
文件名称:userinfo.txt
基础要求:
用户注册功能>>>:文件内添加用户数据(用户名、密码等)
用户登录功能>>>:读取文件内用户数据做校验
ps:上述功能只需要实现一次就算过关(单用户) 文件内始终就一个用户信息
拔高要求:
用户可以连续注册
用户可以多账号切换登录(多用户) 文件内有多个用户信息
ps:思考多用户数据情况下如何组织文件内数据结构较为简单
提示:本质其实就是昨天作业的第二道题 只不过数据库由数据类型变成文件
while True:
print("""
1.注册功能
2.登录功能
""")
choice = input('请选择您想要执行的功能编号>>>:').strip()
if choice == '1':
username = input('please input your username>>>:').strip()
password = input('please input your password>>>:').strip()
# 2.校验用户名是否已存在
with open(r'userinfo.txt', 'r', encoding='utf8') as f:
for line in f: # 'jason|123'
real_name, real_pwd = line.split('|')
if username == real_name:
print('用户名已存在 无法完成注册')
break # 一旦重复 没有必要继续往下校验是否重复了 直接结束循环
else:
with open(r'userinfo.txt', 'a', encoding='utf8') as f1:
f1.write(f'{username}|{password}\n')
print(f'用户{username}注册成功')
elif choice == '2':
# 1.获取用户名和密码
username = input('please input your username>>>:').strip() # 'jason'
password = input('please input your password>>>:').strip() # '123'
# 2.打开文件读取内容并校验
with open(r'userinfo.txt', 'r', encoding='utf8') as f:
for line in f: # 'jason|123\n'
real_name, real_pwd = line.split('|') # 'jason' '123\n'
if real_name == username and real_pwd.strip('\n') == password:
print('登录成功')
break
else:
print('用户名或密码错误')
else:
print('没有该功能编号')

